
Hello! Our company has been dealing with the problem of protection against DDoS attacks for a long time, and in the process of this work I was able to get acquainted with related areas in sufficient detail - to study the principles of creating bots and how to use them. In particular, web scraping, that is, mass collection of public data from web resources using bots.
At some point, this topic fascinated me with the variety of applied problems in which scraping is successfully used. It should be noted here that the “dark side” of web scraping is of the greatest interest to me, that is, harmful and bad scenarios for its use and the negative effects that it can have on web resources and the business associated with them.
At the same time, due to the specifics of our work, most often it was in such (bad) cases that we had to immerse ourselves in detail, studying interesting details. And the result of these dives was that my enthusiasm was passed on to my colleagues - we implemented our solution to catch unwanted bots, but I have accumulated enough stories and observations that will, I hope, be interesting material for you.

I will talk about the following:
- Why do people scratch each other at all;
- What are the types and signs of such scraping;
- What impact does it have on targeted websites;
- What tools and technical capabilities do the creators of bots use to do scraping;
- How different categories of bots can be detected and recognized;
- What to do and what to do if the scraper comes to visit your site (and whether you need to do anything at all).
Let's start with a harmless hypothetical scenario - let's imagine that you are a student, tomorrow morning you have a defense of your term paper, you have no horse lying around based on materials, there are no numbers, no extracts, no quotes - and you understand that for the rest of the night You have neither the time, nor the energy, nor the desire to shove through this entire knowledge base manually.
Therefore, on the advice of older comrades, you uncover the Python command line and write a simple script that accepts URLs as input, goes there, loads the page, parses the content, finds keywords, blocks or numbers of interest in it, adds them into a file, or into the plate and goes on.
Load in this script the required number of addresses of scientific publications, online publications, news resources - it quickly goes over everything, adding up the results. You just have to draw graphs and diagrams, tables on them - and the next morning, with the appearance of a winner, you get your well-deserved point.
Let's think about it - did you do someone badly in the process? Well, unless you parsed HTML with a regular expression, then most likely you didn’t do any harm to anyone, and even more so to the sites that you visited in this way. This is a one-time activity, it can be called modest and inconspicuous, and hardly anyone suffered from the fact that you came, quickly and quietly grabbed the piece of data you needed.
On the other hand, will you do it again if everything worked out the first time? Let's face it - most likely you will, because you just saved a lot of time and resources, having received, most likely, even more data than you originally thought. And this is not limited to scientific, academic or general education research.

Because information costs money, and information gathered on time costs even more money. That is why scraping is a serious source of income for a large number of people. This is a popular freelance topic: go in and see a bunch of orders asking you to collect some data or write scraping software. There are also commercial organizations that do scraping to order or provide platforms for this activity, the so-called scraping as a service. Such a variety and spread is possible, also because scraping itself is something illegal, reprehensible, and is not. From a legal point of view, it is very difficult to find fault with him - especially at the moment, we will soon find out why.

For me, of particular interest is also the fact that in technical terms, no one can forbid you to fight scraping - this creates an interesting situation in which the participants in the process on both sides of the barricades have the opportunity in a public space to discuss the technical and organizational aspects of this matter. To move forward, to some extent, engineering thought and involve more and more people in this process.

From the point of view of legal aspects, the situation that we are now considering - with the permissibility of scraping, was not always the same before. If we look a little at the chronology of fairly well-known lawsuits related to scraping, we will see that even at the dawn of its dawn, eBay's first claim was against a scraper that collected data from auctions, and the court forbade him to engage in this activity. For the next 15 years, the status quo was more or less preserved - large companies won lawsuits against scrapers when they discovered their impact. Facebook and Craigslist, as well as a few other companies, have reported claims that ended in their favor.
However, a year ago, everything suddenly changed. The court found that LinkedIn's claim against the company that collected public profiles of users and resumes was unfounded and ignored the letters and threats demanding to stop the activity. The court ruled that the collection of public data, regardless of whether it is a bot or a person, cannot be the basis for a claim from the company displaying this public data. This powerful legal precedent has shifted the balance in favor of scrapers and has allowed more people to show, demonstrate and try their own interest in this area.
However, looking at all these generally harmless things, do not forget that scraping has many negative uses - when data is collected not just for further use, but in the process the idea of causing any damage to the site or the business behind it is realized. or attempts to enrich themselves in some way at the expense of users of the target resource.
Let's look at a few iconic examples.

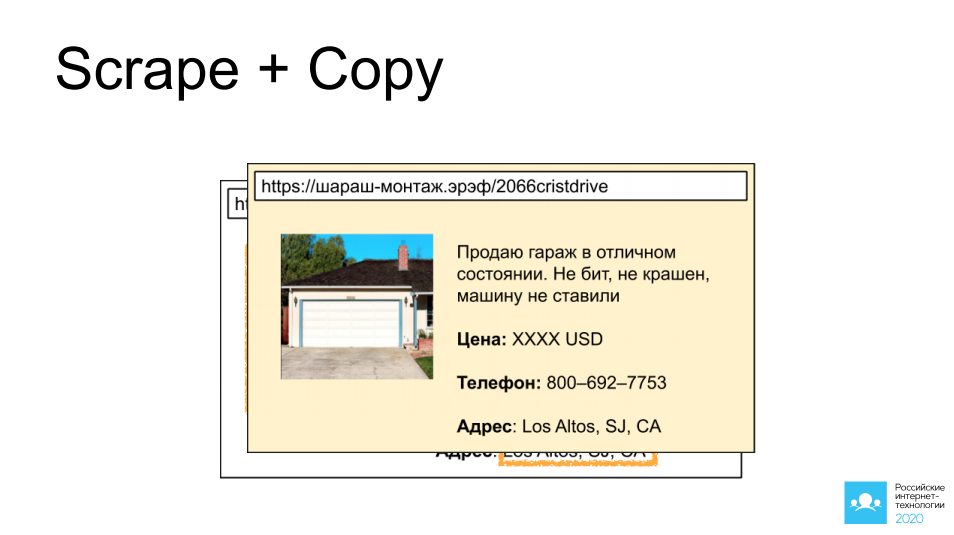
The first of which is scraping and copying other people's ads from sites that provide access to such ads: cars, real estate, personal items. I chose a wonderful garage in California as an example. Imagine that we set a bot there, collect a picture, collect a description, take all contact information, and after 5 minutes the same ad is hanging on another site of a similar focus, and it is quite possible that a profitable deal will happen through it.
If we turn on our imagination a little here and think to the next side - what if it is not our competitor who is doing this, but an attacker? Such a copy of the site can be very useful in order, for example, to request an advance payment from the visitor, or simply offer to enter the payment card details. You can imagine the further development of events yourself.
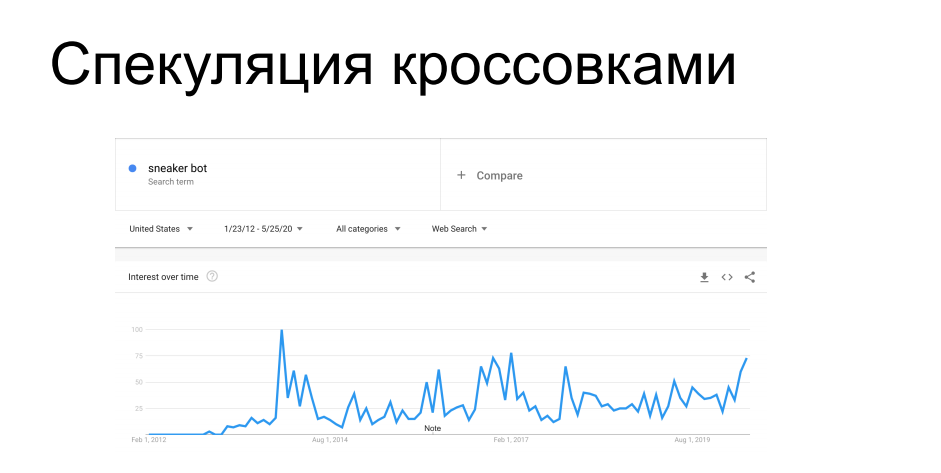
Another interesting case of scraping is the purchase of limited-availability items. Athletic shoe manufacturers such as Nike, Puma and Reebok periodically launch limited edition sneakers, etc. signature series - they are hunted by collectors, they are on sale for a limited time. Ahead of buyers, bots come running to shoe store websites and rake up the entire circulation, after which these sneakers float to the gray market with a completely different price tag. At one time it infuriated vendors and retailers that distribute them. For 7 years they have been fighting against scrapers, etc. sneaker bots with varying success, both technical and administrative methods.

You've probably heard stories when when shopping online it was required to personally come to a sneaker store, or about honeypots with sneakers for $ 100k, which the bot bought without looking, after which its owner grabbed his head - all these stories are in this trend.
And another similar case is the depletion of inventory in online stores. It is similar to the previous one, but no purchases are actually made in it. There is an online store, and certain items of goods that the incoming bots rake into the basket in the quantity that is displayed as available in the warehouse. As a result, a legitimate user trying to buy a product receives a message stating that this article is out of stock, scratches the back of his head in frustration and leaves for another store. The bots themselves then drop the collected baskets, the goods are returned to the pool - and the one who needed it comes and orders. Or does not come and does not order, if this is a scenario of petty mischief and hooliganism. From this it is clear that even if such activities do not cause direct financial damage to an online business, then at least it can seriously disrupt business metrics,which analysts will focus on. Parameters such as conversion, attendance, product demand, average cart check - all of them will be heavily stained by the actions of bots in relation to these items. And before these metrics are taken into work, they will have to be carefully and painstakingly cleaned from the effects of scrapers.
In addition to such a business focus, there are quite noticeable technical effects arising from the work of scrapers - most often when scraping is done actively and intensively.
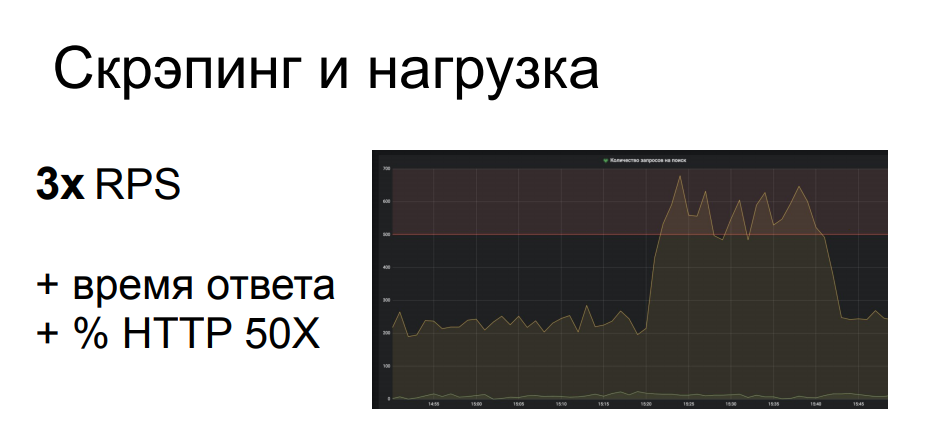
One of our examples from one of our clients. The scraper came to a location with a parameterized search, which is one of the hardest operations in the backend of the structure in question. The scraper had to go through a lot of search queries, and out of 200 RPS to this location he made almost 700. This seriously loaded part of the infrastructure, which caused a degradation of the quality of service for the rest of the legitimate users, the response time took off, the 502s and 503s fell. and mistakes. In general, the scraper did not care at all and he sat and did his job while everyone else frantically refreshed the browser page.
From this it is clear that such activity may well be classified as an applied DDoS attack - and often it does. Especially if the online store is not so large, it does not have an infrastructure that is repeatedly reserved in terms of performance and location. Such activity may well, if you do not completely put the resource - it is not very profitable for the scraper, since in this case he will not receive his data - then make all other users seriously upset.
But besides DDoS, scraping also has interesting neighbors from the cybercrime sphere. For example, brute force logins and passwords use a similar technical base, that is, using the same scripts, it can be done with an emphasis on speed and performance. For credential stuffing, user data scrapped from somewhere is used, which is pushed into form fields. Well, that example of copying content and posting it on similar sites is a serious preparatory work in order to slip phishing links and lure unsuspecting buyers.

In order to understand how different variants of scraping can, from a technical point of view, affect the resource, let's try to calculate the contribution of individual factors to this task. Let's do some arithmetic.

Let's say we have a bunch of data on the right that we need to collect. We have a task or order to retrieve 10,000,000 lines of commodity items, for example price tags or quotes. And on the left side we have a time budget, because tomorrow or in a week this data will no longer be needed by the customer - they will become outdated and will have to be collected again. Therefore, you need to keep within a certain timeframe and, using your own resources, do it in the optimal way. We have a number of servers - machines and IP addresses behind which they are located, from which we will go to the resource of interest to us. We have a number of user instances that we pretend to be - there is a task to convince an online store or some public base that these are different people or different computers go for some kind of data so that those whowho will analyze the logs, there was no suspicion. And we have some performance, request rate, from one such instance.
It is clear that in a simple case - one host machine, a student with a laptop, going through the Washington Post, a large number of requests with the same signs and parameters will be made. It will be very noticeable in the logs if there are a lot of such requests - which means it is easy to find and ban, in this case, by the IP address.
As the scraping infrastructure becomes more complex, a larger number of IP addresses appear, proxies are beginning to be used, including house proxies - more on them later. And we begin to multi-instantiate on each machine - to replace the query parameters, the signs that characterize us, in order to make the whole thing smear in the logs and not be so conspicuous.
If we continue in the same direction, then we have the opportunity, within the framework of the same equation, to reduce the intensity of requests from each such instance - making them more rare, rotating them more efficiently so that requests from the same users do not end up in the logs nearby. without arousing suspicion and being similar to the end (legitimate) users.
Well, there is an edge case - we once had such a case in practice, when a scraper came to a customer from a large number of IP addresses with completely different user attributes behind these addresses, and each such instance made exactly one request for content. I made a GET to the desired product page, parsed it and left - and never appeared again. Such cases are quite rare, as they require more resources (which cost money) to be used in the same amount of time. But at the same time, it becomes much more difficult to track them down and understand that someone even came here and scraped them. Traffic research tools such as behavioral analysis - building a pattern of behavior of a particular user - become very complicated. After all, how can you do behavioral analysis if there is no behavior? There is no history of user actions,he had never appeared before and, interestingly, since then he has never come either. In such conditions, if we do not try to do something at the first request, then it will receive its data and leave, and we will be left with nothing - we have not solved the problem of countering scraping here. Therefore, the only opportunity is to guess at the very first request that the wrong person has come, whom we want to see on the site, and give him an error or otherwise make sure that he does not receive his data.whom we want to see on the site, and give him an error or otherwise make sure that he does not receive his data.whom we want to see on the site, and give him an error or otherwise make sure that he does not receive his data.
In order to understand how you can move along this scale of complexity in building a scraper, let's look at the arsenal that bot creators have that are most often used - and what categories it can be divided into.

The primary, simplest category that most readers are familiar with is script scraping, the use of simple enough scripts to solve relatively complex problems.

And this category is perhaps the most popular and well-documented. It's even difficult to recommend what exactly to read, because, in reality, there is a lot of material. A lot of books were written using this method, there are a lot of articles and publications - in principle, it is enough to spend 5/4/3/2 minutes (depending on the impudence of the author of the material) to parse your first site. This is a logical first step for many who get started in web scraping. The "starter pack" of such an activity is most often Python, plus a library that can make requests flexibly and change their parameters, such as requests or urllib2. And some kind of HTML parser, usually Beautiful Soup. There is also an option to use libs that are created specifically for scraping, such as scrapy, which includes all these functionality with a user-friendly interface.
With the help of simple tricks, you can pretend to be different devices, different users, even without being able to somehow scale your activities by machines, by IP addresses and by different hardware platforms.

In order to knock off the scent of the one who inspects the logs on the server side from which the data is collected, it is enough to replace the parameters of interest - and this is easy and not long. Let's look at an example of a custom log format for nginx - we record an IP address, TLS information, headers of interest to us. Here, of course, not everything that is usually collected, but we need this restriction as an example - to look at a subset, simply because everything else is even easier to "throw".
In order not to be banned by addresses, we will use residential proxy, as they are called abroad - that is, proxies from rented (or hacked) machines in the home networks of providers. It is clear that by banning such an IP address, there is a chance to ban a certain number of users who live in these houses - and there may well be visitors to your site, so sometimes it is more expensive for yourself to do this.
TLS information is also not difficult to change - take the cipher suites of popular browsers and choose the one that you like - the most common, or rotate them periodically in order to present themselves as different devices.
As for the headers, with the help of a little study, you can set the referer to whatever the scraped site likes, and we take the user agent from Chrome, or Firefox, so that it does not differ in any way from tens of thousands of other users.
Then, juggling with these parameters, you can pretend to be different devices and continue scraping without being afraid to somehow be noted for the naked eye walking through the logs. For the armed eye, this is still somewhat more difficult, because such simple tricks are neutralized by the same, rather simple, countermeasures.

Comparing request parameters, headers, IP addresses with each other and with publicly known ones allows you to catch the most arrogant scrapers. A simple example - a search bot came to us, but for some reason its IP is not from the search engine's network, but from some cloud provider. Even Google itself on the page describing Googlebot recommends doing reverse lookup DNS records in order to make sure that this bot actually came from google.com or other valid Google resources.
There are many such checks, most often they are designed for those scrapers who do not bother with fuzzing, some kind of substitution. For more complex cases, there are more reliable and more cumbersome methods, for example, slip Javascript into this bot. It is clear that in such conditions the struggle is already unequal - your Python script will not be able to execute and interpret the JS code. But the author of the script can do it - if the author of the bot has enough time, desire, resources and skill to go see in the browser what your Javascript is doing.
The essence of the checks is that you integrate the script into your page, and it is important for you not only that it is executed, but also that it demonstrates some kind of result, which is usually POST sent back to the server before the client gets enough sleep content, and the page itself will load. Therefore, if the author of the bot solved your riddle and hardcodes the correct answers into his Python script, or, for example, understands where he needs to parse the script lines themselves in search of the necessary parameters and called methods, and will calculate the answer on his own, he can deceive you around your finger. Here's an example.

I think that some listeners will recognize this piece of javascript - this is a check that one of the largest cloud providers in the world used to have before accessing the requested page, compact and very simple, and at the same time, without learning it, it's so easy to the site does not break through. At the same time, having applied a little effort, we can ask the page in search of the JS methods of interest to us that will be called, from them, counting off, find the values of interest to us that should be calculated, and stick the calculations into the code. After that, do not forget to sleep for a few seconds due to the delay, and voila.

We got to the page and then we can parse what we need, spending no more resources than creating our own scraper. That is, from the point of view of using resources, we do not need anything additional to solve such problems. It is clear that the arms race in this vein - writing JS challenges and parsing them and circumventing them by third-party tools - is limited only by the time, desire, and skills of the author of bots and the author of checks. This race can go on for quite a long time, but at some point most scrapers become uninteresting, because there are more interesting options to cope with it. Why sit around and parse JS code in Python when you can just grab and run a browser?

Yes, I'm primarily talking about headless browsers, because this tool, originally created for testing and Q&A, has turned out to be ideal for web scraping tasks at the moment.
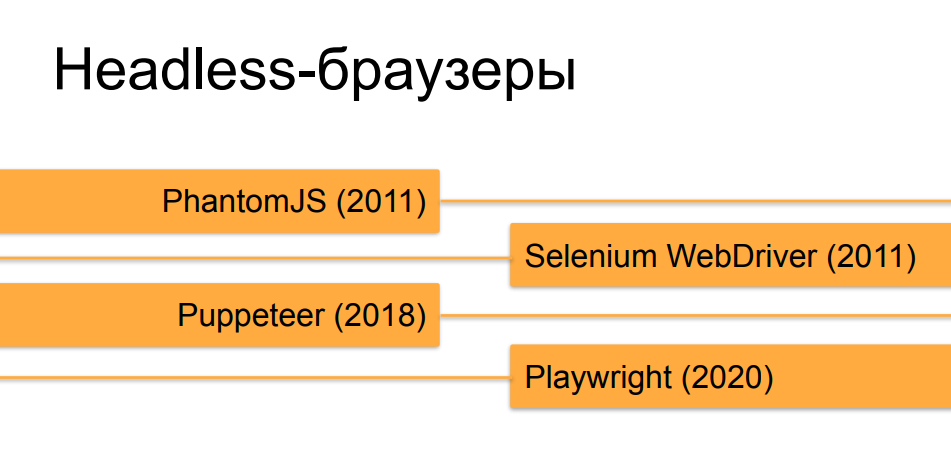
We will not go into details about headless browsers, I think that most of the listeners already know about them. Orchestrators, which automate headless browsers, have undergone quite a brisk evolution over the past 10 years. At first, at the time of the emergence of PhantomJS and the first versions of Selenium 2.0 and Selenium WebDriver, it was not at all difficult to distinguish a headless browser running under an automaton from a live user. But, over time and the emergence of tools such as Puppeteer for headless Chrome and, now, the creation of gentlemen from Microsoft - Playwright, which does the same thing as Puppeteer, but not only for Chrome, but for all versions of popular browsers, they are more and more and bring headless browsers closer to the real ones in terms ofhow they can be made with the help of orchestration similar in behavior and in different signs and properties to the browser of a healthy person.

In order to deal with headless recognition against the background of ordinary browsers that people sit at, as a rule, the same javascript checks are used, but deeper, detailed, collecting a cloud of parameters. The result of this collection is sent back either to the protection tool or to the site from which the scraper wanted to collect the data. This technology is called fingerprinting, because it collects a real digital fingerprint of the browser and the device on which it is running.
There are quite a few things that JS checks when fingerprinting look at - they can be divided into some conditional blocks, in each of which digging can go on and on. There are really a lot of properties, some of them are easy to hide, some are less easy. And here, as in the previous example, a lot depends on how meticulously the scraper approached the task of hiding the protruding "tails" of headlessness. There are properties of objects in the browser, which the orchestrator replaces by default, there is the very property (navigator.webdriver), which is set in headless, but at the same time it is not in regular browsers. It can be hidden, an attempt to hide can be detected by checking certain methods - what checks these checks can also be hidden and slipped fake output to functions that print methods, for example,and it can last indefinitely.
Another block of checks, as a rule, is responsible for studying window and screen parameters, which by definition do not have in headless browsers: checking coordinates, checking sizes, what is the size of a broken image that has not been drawn. There are a lot of nuances that a person who knows the device of browsers well can foresee and slip a plausible (but not real) conclusion on each of them, which will fly away in fingerprint checks to the server, which will analyze it. For example, in the case of rendering some pictures, 2D and 3D, by means of WebGL and Canvas, you can completely take the entire output ready, forge it, issue it in a method and make someone believe that something is really drawn.
There are more tricky checks that do not occur simultaneously, but let's say the JS code will spin for a certain number of seconds on the page, or it will hang constantly and transfer some information to the server from the browser. For example, tracking the position and speed of the cursor movement - if the bot clicks only in the places it needs and follows the links at the speed of light, then this can be tracked by the movement of the cursor, if the author of the bot does not think of registering some kind of human-like, smooth , offset.
And there is quite a jungle - these are version-specific parameters and properties of the object model, which are specific from browser to browser, from version to version. And in order for these checks to work correctly and not falsify, for example, on live users with some old browsers, you need to take into account a bunch of things. First, you need to keep up with the release of new versions, modify your checks so that they take into account the state of affairs on the fronts. It is necessary to maintain backward compatibility so that someone can come to a site protected by such checks on an atypical browser and at the same time not be caught like a bot, and many others.
This is painstaking, rather complicated work - such things are usually done by companies that provide bot detection as a service, and doing this on their own on their own resource is not a very profitable investment of time and money.
But, what can we do - we really need to scrape the site, hung with a cloud of such headlessness checks and calculating our some headless-chrome with puppeteer, despite everything, no matter how hard we try.
A small lyrical digression - for those who are interested in reading in more detail about the history and evolution of checks, for example, for headlessness of Chrome, there is a funny epistolary duel between two authors. I don't know very much about one author, and the other is called Antoine Vastel, a young man from France who maintains a blog about bots and their detection, obfuscation of checks and many other interesting things. And so they and their counterpart have been arguing for two years about whether it is possible to detect headless Chrome.
And we will move on and understand what to do if we can't get through the checks with the headless.

This means that we will not use headless, but will use large real browsers that draw us windows and all sorts of visual elements. Tools such as Puppeteer and Playwright allow, instead of headless, to launch browsers with a rendered screen, read user input from there, take screenshots, and much more that is not available to browsers without a visual component.

In addition to bypassing the headlessness checks, in this case, you can also cope with the following problem - when we have some cunning site builders, hide from the text in pictures, make them invisible without making additional clicks or some other actions and movements. They hide some elements that should be hidden, and which headless come across: they do not know that this element should not be displayed on the screen now, and they come across it. We can simply draw this picture in the browser, feed the screenshot to the OCR, get the text at the output and use it. Yes, it is more difficult, more expensive in terms of development, takes longer and eats more resources. But there are scrapers that work this way, and at the expense of speed and performance, they collect data in this way.

"What about the CAPTCHA?" - you ask. After all, OCR (advanced) captcha cannot be solved without some more complex things. There is a simple answer to this - if we can't solve the captcha automatically, why not use human labor? Why separate a bot and a human, if you can combine their work to achieve a goal?
There are services that allow you to send them a captcha, where it is solved by the hands of people sitting in front of the screens, and through the API you can get an answer to your captcha, insert a cookie into the request, for example, which will be issued, and then automatically process information from this site ... Every time a captcha pops up, we pull the apishka, get an answer to the captcha - slip it in the next question and move on.
It is clear that this also costs a pretty penny - the CAPTCHA solution is purchased in bulk. But if our data is more expensive than the cost of all these tricks, then, after all, why not?
Now that we have looked at the evolution towards the complexity of all these tools, let's think about what to do if scraping occurs on our online resource - an online store, a public knowledge base, or whatever.

The first thing to do is to locate the scraper. I’ll tell you this: not all cases of public gathering generally bring negative effects, as we have already considered at the beginning of the report. As a rule, more primitive methods, the same scripts without rate-limiting, without limiting the request speed, can do much more harm (if they are not prevented by means of protection) than some complex, sophisticated, headful-browser scraping with one request in the hour, which at first still needs to be somehow found in the logs.

Therefore, first you need to understand that we are being scraped - to look at those meanings that are usually affected by this activity. We are now talking about technical parameters and business metrics. These are the things that you can see in your Grafana, over time watching the load and traffic, all kinds of bursts and anomalies. You can also do this manually if you do not use a security tool, but it is more reliably done by those who know how to filter traffic, detect all sorts of incidents and match them with some events. Because in addition to analyzing logs after the fact and in addition to analyzing each individual request, the use of some accumulated means of protection of the knowledge base can work here, which has already seen the actions of scrapers on this resource or on similar resources, and you can somehow compare one with the other - speech about correlation analysis.
As for business metrics, we have already recalled using the example of scripts that cause direct or indirect financial damage. If it is possible to quickly track the dynamics of these parameters, then again scraping can be noticed - and then, if you solve this problem yourself, welcome to the logs of your backend.
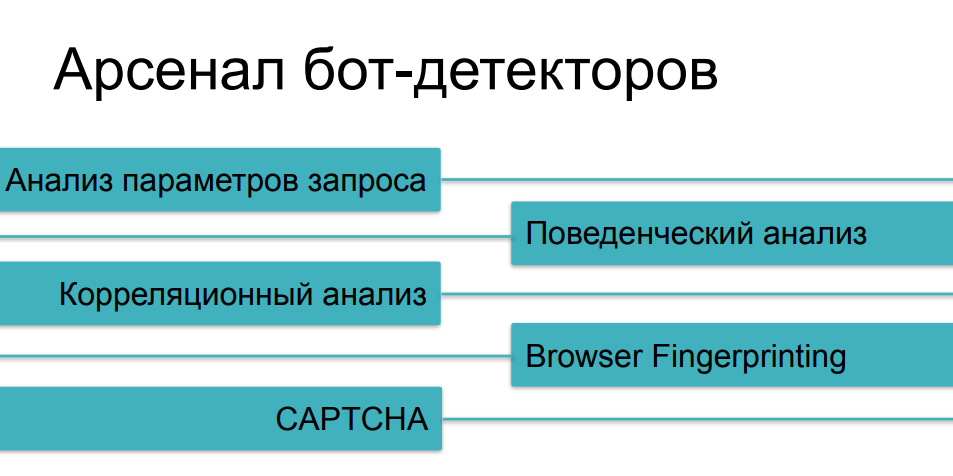
As for the means of protection that are used against aggressive scraping, we have already considered most of the methods, talking about different categories of bots. Traffic analysis will help us from the simplest cases, behavioral analysis will help us track things such as fuzzing (identity substitution) and multi-instance scripts. Against more complex things, we will collect digital prints. And, of course, we have a CAPTCHA as the last argument of the kings - if we could not somehow catch a cunning bot on the previous questions, then, probably, it will stumble on a CAPTCHA, right?
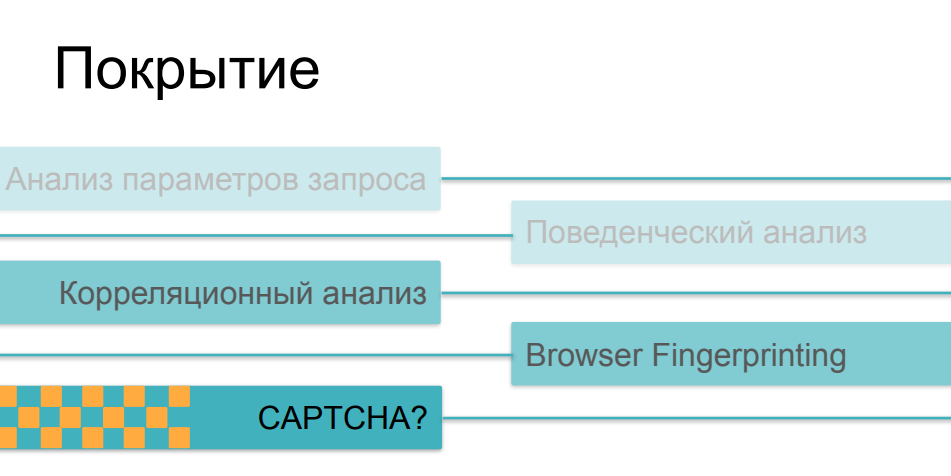
Well, it's a little more complicated here. The fact is that as the complexity and cunning of checks increases, they become more and more expensive, mainly for the client side. If traffic analysis and subsequent comparison of parameters with some historical values can be done absolutely non-invasively, without affecting the page load time and the speed of the online resource in principle, then fingerprinting, if it is massive enough and makes hundreds of different checks on the browser side, can seriously affect the download speed. And few people like to watch pages with checks in the process of following links.
When it comes to CAPTCHAs, this is the crudest and most invasive method. This is a thing that can really scare away users or buyers from the resource. Nobody likes captcha, and they don't turn to it because of a good life - they resort to it when all other options have not worked. There is one more funny paradox here, some problem with such application of these methods. The fact is that most of the means of protection in one or another superposition use all these possibilities, depending on how complex the scenario of bot activity they encountered. If our user managed to pass traffic analyzers, if his behavior does not differ from the behavior of users, if his fingerprint looks like a valid browser, he overcame all these checks, and then at the end we show him the captcha - and it turns out to be a person ... it can be very sad ...As a result, the captcha begins to be shown not to evil bots that we want to cut off, but to a fairly serious share of users - people who may get angry at this and may not come next time, not buy something on the resource, not participate in its further development.

Considering all these factors - what should we do in the end if scraping came to us, we looked at it and were able to somehow assess its impact on our business and technical performance? On the one hand, it makes no sense to fight against scraping by definition as with the collection of public data, machines or people - you yourself agreed that this data is available to any user who comes from the Internet. And to solve the problem of limiting scraping "out of principle" - that is, due to the fact that advanced and talented bot bots come to you, you try to ban them all - it means spending a lot of resources on protection, either your own, or using an expensive and very complex solution , self-hosted or cloud-based in "maximum security mode" and, in pursuit of each individual bot, risk scaring off the share of valid users with such things,like heavy javascript checks, like captcha that pops up on every third transition. All this can change your site beyond recognition in favor of your visitors.
If you want to use a security tool, then you need to look for those that will allow you to change and somehow find a balance between the proportion of scrapers (from simple to complex) that you will try to cut off from the use of your resource and, in fact, the speed of your web -resource. Because, as we have already seen, some checks are done simply and quickly, while some checks are difficult and time-consuming - and at the same time are very noticeable to the visitors themselves. Therefore, solutions that are able to apply and vary these countermeasures within a common platform will allow you to achieve this balance faster and better.
Well, it is also very important to use what is called the "correct mindset" in the study of all these problems on their own or others' examples. It must be remembered that public data itself is not in need of protection - it will still sooner or later be seen by all people who want it. The user experience needs protection: the UX of your customers, customers and users, which, unlike scrapers, generate income for you. You can keep it and increase it if you are better versed in this very interesting area.
Thank you very much for your attention!
