Now we need to learn how to describe the logic that will operate on the received data and issue a verdict on whether our rule will work in a given situation. It is this section of the rule and its features that this article is devoted to. The description of the detection logic section is the most important part of the syntax, knowledge of which is necessary to understand the existing rules and write your own.
In the next publication, we will dwell in detail on the description of meta information (attributes that are informative or infrastructural in nature, such as a description or identifier) and rule collections. Follow our publications!
Description of the detection logic (detection attribute)
Rules triggering conditions are set in the detection attribute . Its subfields describe the main technical part of the rule. It is important to note that a rule can have only one descriptive part and several logsource and detection. Since the detection section describes the triggering criterion based on data from the sources section, these two sections have a 1 to 1.
In general, the content of the detection field consists of two logical parts:
- a description of the assumptions about the event fields (search IDs),
- the logical relationship between these descriptions ( timeframe and expression in the condition field ).

The description of the assumptions about the content of the event fields is done by specifying search identifiers. Such an identifier can be one (as here ) or there can be several of them (as here ).
The second part can be of three types:
- the usual condition,
- a condition with an aggregate expression (as in the example above),
- condition with the keyword near .
The syntax of the elements of each part is described in the corresponding section of this article.
Search IDs
A search identifier is a key-value pair, where the key is the name of the search identifier, and the value is a list or dictionary (aka an associative array). By analogy with programming languages - list or map. The format for specifying lists and dictionaries is defined by the YAML standard, which can be found here . It is worth noting that the Sigma rule format does not fix the names of the search identifiers, but most often you can find variations with the word selection.
There are general requirements that apply to both list items and dictionary items:
- All values are treated as case-insensitive strings, that is, there is no difference between uppercase and lowercase letters.
- (wildcards) ‘*’ ‘?’. ‘*’ — ( ), ‘?’ — ( ).
- ‘\’, ‘\*’. , : ‘\\*’. .
- , .
- ‘ .
List of Values Search Identifier
Lists of Values contain strings that are searched for throughout the event message. The elements of the list are combined with a logical OR.
detection:
keywords:
- EVILSERVICE
- svchost.exe -n evil
condition: keywords

Examples of rules containing search identifiers as a list of values:
- rules / web / web_apache_segfault.yml (the list can contain one element)
- rules / windows / powershell / powershell_clear_powershell_history.yml
- rules / linux / lnx_shell_susp_log_entries.yml
Dictionary search identifier
Dictionaries consist of a set of key-value pairs, where the key is the name of the field from the event, and the value can be a string, an integer, or a list of one of these types (lists of strings or numbers are combined with a logical OR). Sets of dictionaries are combined by logical AND.
General scheme:
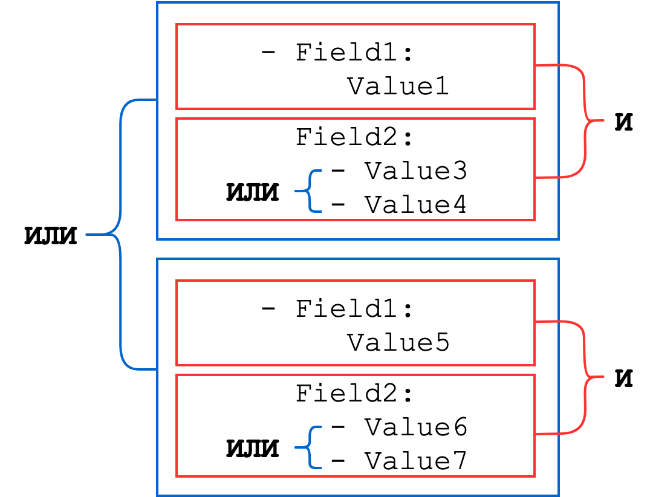
Let's consider a few examples.
Example 1. Event log cleanup detection rule
rules / windows / builtin / win_susp_security_eventlog_cleared.yml
This rule will be triggered if the event meets the condition:
EventID = 517 OR EventID = 1102
In the rule, it looks like this:
detection:
selection:
EventID:
- 517
- 1102
condition: selection Here selection is the name of the only search identifier, and the rest of the subfields are its value, and this value is of type "dictionary" In this dictionary, EventID is the key, and the numbers 517 and 1102 form a list, which is the value of this dictionary key.
Example 2. A suspicious ticket request, most likely Kerberoasting
rules / windows / builtin / win_susp_rc4_kerberos.yml
This rule will be triggered if the event meets the condition:
EventID = 4679 AND TicketOptions = 0x40810000 AND TicketEncryption = 0x17 AND ServiceName does not end with a '$' sign
In the rule, it looks like this:
detection:
selection:
EventID: 4769
TicketOptions: '0x40810000'
TicketEncryption: '0x17'
reduction:
- ServiceName: '*$'
condition: selection and not reduction Special field values
There are two special field values that can be used:
- An empty value specified by two single quotes ''
- The null value specified by the null keyword
Note: a non-empty value cannot be specified via the not null construct
The application of these values depends on the target SIEM system. To describe the not null condition, you need to create a separate search identifier with an empty value and take from it the negation in the condition (the condition field, it is described at the end of the article). Consider further examples of rules that use the description of an empty field.
Example 3. Suspicious launch of a remote stream
rules / windows / sysmon / sysmon_password_dumper_lsass.yml
The specified rule will be triggered if the event meets the condition:
EventID = 8 AND TargetImage = 'C: \ Windows \ System32 \ lsass.exe' AND StartModule is an empty field
In the rule it looks like this:
detection:
selection:
EventID: 8
TargetImage: 'C:\Windows\System32\lsass.exe'
StartModule: null
condition: selection Example 4. Writing an executable file to an alternative file stream NTFS
rules / windows / sysmon / sysmon_ads_executable.yml
The considered rule is an example of the correct designation for a non-empty value. This rule will be triggered if the event meets the condition:
EventID = 15 AND I
mphash != '00000000000000000000000000000000' Imphash
In the rule, it looks like this:
detection:
selection:
EventID: 15
filter:
Imphash:
- '00000000000000000000000000000000'
- null
condition: selection and not filter As mentioned above, the negation must now be placed in the condition (the condition field), and not in the search identifiers.
Value modifiers
The interpretation of field values in a rule can be changed using modifiers. Modifiers are added after the field name, each modifier is preceded by a vertical bar (pipe) - “|”. They can be chained to build chains (pipelines) of modifiers:

The field value is modified in accordance with the order of the modifiers in the chain. Modifiers can be of two types: transform and type modifiers.
Transform modifiers are those that convert the original value of a field to some other value or transform the logic for processing lists of values in search identifiers. An example of the first type is Base64 modifiers, and the second is the all modifier . All modifiers will be discussed in more detail later.
Let's take a look at each of the transform modifiers. For clarity, we will schematically show how exactly this or that modifier changes the initial value.
startswith
The startswith modifier is used to match the beginning of a string with the desired value.

Examples of using:
- rules / windows / builtin / win_ad_replication_non_machine_account.yml
- rules / windows / process_creation / win_apt_winnti_mal_hk_jan20.yml
- rules / windows / powershell / powershell_downgrade_attack.yml
endswith
The endswith modifier is used to match the end of a string with a search value.

Examples of using:
- rules / windows / process_creation / win_local_system_owner_account_discovery.yml
- rules / windows / sysmon / sysmon_minidumwritedump_lsass.yml
- rules / windows / process_creation / win_susp_odbcconf.yml
contains
The contains modifier checks the occurrence of a substring in the field value. In fact, this modifier converts the field value as follows:

That is, if we consider the results of applying the considered modifiers, you can write the following formula:
startswith + endswith = contains
Examples:
- rules / windows / process_creation / win_hack_bloodhound.yml
- rules / windows / process_creation / win_mimikatz_command_line.yml
- rules / windows / sysmon / sysmon_webshell_creation_detect.yml
all
Usually, sheet elements are combined with a logical OR. The all modifier changes logical OR to logical AND. That is, all elements of the list must be present. Let's see how the conditions would change in the general scheme, which was at the beginning of the section:
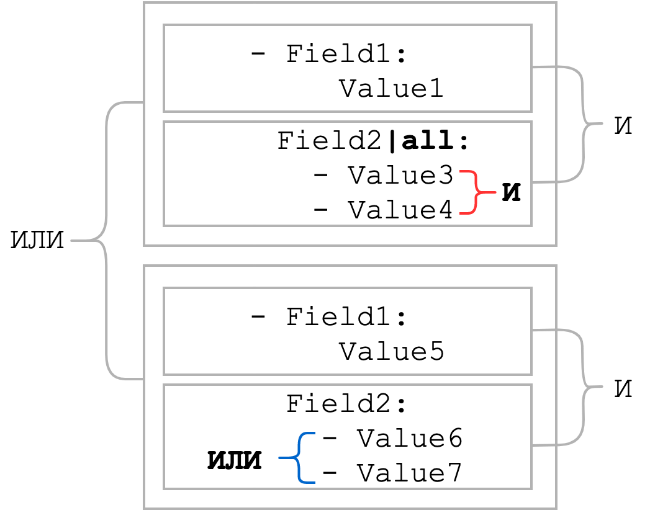
As you can see, when the all modifier was applied, the logical connection between the list items became AND. Usually, the all modifier is used in conjunction with the contains modifier. Such a bunch can serve as a replacement for the pattern with wildcard metacharacters if the order of the static parts is unknown.
Examples of using the all modifier :
- rules / windows / builtin / win_meterpreter_or_cobaltstrike_getsystem_service_installation.yml
- rules / windows / powershell / powershell_suspicious_profile_create.yml
- rules / windows / powershell / powershell_suspicious_download.yml
base64
This modifier is applied when the field value is encoded in Base64 , and for clarity, we write the encoded text in the rule, and not the resulting Base64 string.

This modifier assumes an exact match of the field to the encoded string. It is usually more useful to identify signs of suspicious activity in the original data than to look for an exact match to the encoded result. Therefore, there are no examples of using the base64 modifier yet.
base64offset
Due to the peculiarities of Base64 encoding, a pipeline from base64 and contains cannot be used to find an encoded substring . The base64offset modifier is created for this very purpose . It is used when a string is Base64 encoded and we want to find a substring of the encoded string. Moreover, the characters that surround the desired substring are unknown in advance, and the offset of the substring relative to the beginning of the string is unknown. You can clearly see what is at stake here.
Almost always, this modifier is used together with the contains modifier :

Examples of use:
- rules / windows / process_creation / win_encoded_frombase64string.yml
- rules / windows / process_creation / win_encoded_iex.yml
Important! The following three encoding transform modifiers are used only in conjunction with Base64 modifiers.
utf16le or wide
The utf16le and wide modifiers are synonyms. They transform the string value of the field to UTF-16LE encoding, that is
“123” -> 0x31 0x00 0x32 0x00 0x33 0x00.

utf16be
The utf16be modifier converts the string value of the field to UTF-16BE, that is
“123” -> 0x00 0x31 0x00 0x32 0x00 0x33.

utf16
Modifier utf16 adds a byte order mark (BOM), and encodes a string in UTF-16, that is
“123” -> 0xFF 0xFE 0x31 0x00 0x32 0x00 0x33 0x00.

There is currently only one type modifier - re .
re
This type modifier interprets the field value as a regular expression pattern. So far, it is only supported by the converter to an Elasticsearch query, so it practically does not appear in public rules.
Examples of using:
- rules / windows / process_creation / win_invoke_obfuscation_obfuscated_iex_commandline.yml
- rules / windows / builtin / win_invoke_obfuscation_obfuscated_iex_services.yml
- rules / windows / builtin / win_mal_creddumper.yml
Time interval (timeframe attribute)
Additionally, the detection logic can be refined by specifying the time interval during which the search identifiers should appear. Standard abbreviations are used to denote time units:
15s (15 )
30m (30 )
12h (12 )
7d (7 )
3M (3 ) Examples of using:
- rules / linux / modsecurity / modsec_mulitple_blocks.yml
- rules-unsupported / net_possible_dns_rebinding.yml
- rules / windows / builtin / win_rare_service_installs.yml
Description of rule trigger conditions (condition attribute)
According to the official Sigma documentation, the part of the rule that contains the trigger condition is the most complex and will change over time. The following expressions are currently available.
Logical operations AND, OR
They are indicated by the keywords and and or, respectively. These expressions are the main elements of building a logical relationship between search identifiers.
detection:
keywords1:
- EVILSERVICE
- svchost.exe -n evil
keywords2:
- SERVICEEVIL
- svchost.exe -n live
condition: keywords1 or keywords2 Examples of using:
One of the search ID values / all of the search ID values (1 / all of search-identifier)
The same as for the previous case, if the search ID
- 1 - logical OR among alternatives,
- all - logical AND among alternatives.
By default
condition: keywordsmeans that the values listed in the keywords identifier are logical OR, that is, this is the same as writing condition: 1 of keywords. If we want the values to be combined with a logical AND, then we need to write condition: all of keywords.
Examples of using:
One of the search IDs / all search IDs (1 / all of them)
Logical OR (1 of them) or logical AND (all of them) among all given search IDs. By default, search IDs are linked by a logical AND if they are elements of a dictionary, or a logical OR if they are elements of a list. To change these relationships, this structure was created. Thus, the condition, condition: 1 of them, means that at least one of the search identifiers must appear in the event.
Examples of using:
- rules / windows / process_creation / win_hack_bloodhound.yml
- rules / windows / powershell / powershell_psattack.yml
- rules / cloud / aws_ec2_download_userdata.yml
One of the search IDs matching the name pattern / all search IDs matching the name pattern (1 / all of search-identifier-pattern)
Same as for the previous paragraph, but the selection is limited to search identifiers whose names match the pattern. Such patterns are constructed using the wildcard * (any number of characters) at a specific position in the name pattern.
The syntax is as follows:
condition: 1 of selection*
condition: all of selection* Examples of using:
- rules / windows / builtin / win_user_added_to_local_administrators.yml
- rules / windows / process_creation / win_susp_eventlog_clear.yml
- rules / cloud / aws_iam_backdoor_users_keys.yml
Logical negation
Logical negatives are constructed using the not keyword . As noted above, the expression “not empty” must be specified in the condition field , and not in the description of the search ID. The following example clearly shows the correct version of the description of the expression "field value is not empty".

Examples of using:
- rules / windows / sysmon / sysmon_malware_backconnect_ports.yml
- rules / windows / process_creation / win_apt_gallium.yml
Pipe
The vertical bar (or pipe) indicates that the result of the expression will be passed to an aggregate function, the result of which is likely to be compared to some value.
General scheme:
_ | _
condition: selection | count(category) by dst_ip > 30 Examples of using:
- rules / windows / builtin / win_susp_failed_logons_single_source.yml
- rules / windows / other / win_rare_schtask_creation.yml
- rules / network / net_high_dns_requests_rate.yml
Parentheses
Parentheses are used to specify a subexpression. This can be useful for specifying the order in which a logical expression is evaluated, or for negating a predicate that contains multiple expressions. They have the highest priority for the operation.
condition: selection and (keywords1 or keywords2)
condition: selection and not (filter1 or filter2) Usage example:
Aggregate Function Expressions
Aggregate expressions (or aggregate function expressions) are used to quantify the events that have occurred.
Aggregate Expression Schema:

All aggregate functions except count require a field name as a parameter. The count function counts all matching events if no field name is specified. If a field name is specified, then the function counts different values in this field. For example, the following expression counts the number of different ports to which connections were made from one IP address, and if this number exceeds 10, then the rule is triggered:
condition: selection | count(dst_port) by src_ip > 10 Examples of using:
- rules / linux / lnx_susp_failed_logons_single_source.yml
- rules / windows / other / win_rare_schtask_creation.yml
- rules / network / net_susp_network_scan.yml
Aggregate expression near
The near keyword is used to generate a query (if this functionality is supported by the target system and backend) that recognizes the occurrence of all specified search IDs within a specified time interval after finding the first ID.
General schema:
near search-id-1 [ [ and search-id-2 | and not search-id-3 ] ... ]
Syntax example:
timeframe: 30s
condition: selector | near dllload1 and dllload2 and not exclusion The same rules apply to the search expression after the word near as to the search expression before the vertical bar, which we discussed in detail above.
Examples of using:
- rules / windows / sysmon / sysmon_mimikatz_inmemory_detection.yml
- rules / windows / builtin / win_susp_samr_pwset.yml
The default priority of operations is:
- (expression)
- X of search-pattern
- Not
- And
- Or
- |
Thus, parentheses have the highest priority, and the pipe has the lowest.
Note: if multiple condition fields are specified, then the final value is obtained by applying logical OR to all expression values.
In this article, we have described the detection logic. Follow our posts, in the next article we will look at the remaining fields of the rule. Most of them are of informational or infrastructural nature. In addition to fields with meta information, let us dwell on such a feature of the composition of rules, which is called rule collections. For people who are not familiar with the intricacies of the YAML language, considering this aspect of syntax will be useful when reading strangers and writing their own rules.
Author : Anton Kutepov, specialist of the department of expert services and development of Positive Technologies (PT Expert Security Center)