
There are only a few processor development companies in Russia. One of these companies is MCST with Elbrus processors. In general, MCST focuses on the fact that their processors are Russian, and the state helps it in every possible way. Firstly, the state is the main consumer of Elbrus, since an ordinary consumer does not need such a processor at the moment. And secondly, the state grants subsidies for MCST projects and takes initiatives that simplify the activities of this company. This article will discuss the Elbrus processor family and what they can offer instead of processors because of the “hillock”.
Elbrus processors
Soviet period
At the end of the 60s of the 20th century, a state directive was adopted in the USSR, which designated the further vector of development of computer engineering in the USSR as copying the developments of Western colleagues, in particular the IBM S / 360 computer . In general, many Soviet engineers, including the father of Soviet cybernetics, Sergei Lebedev , were skeptical about such a decision. According to Lebedev, the path of copying is, by definition, the path of the laggards. But no one saw other options or did not want to see.

Sergey Alekseevich Lebedev
If the majority of Soviet developments did not escape the influence of this directive, then the Elbrus-1 computer was lucky. It can be called the original development of Soviet scientists. In 1969, engineers were tasked with creating a computer with a productivity of 100 million operations per second. Since such a project was dictated by military goals, namely the arms race, the issues of fault tolerance and continuous operation of the system came to the fore. As a result, "Elbrus-1" acquired multiprocessing and parallelization tools. Work on "Elbrus-1" went on for 6 years, from 1973 to 1979, and in 1980 the project was handed over to the state commission. The final version had a performance of 15 million operations per second, 64 MB of RAM and supported the simultaneous operation of up to 10 processors.

Elbrus-1
Coming by leaps and bounds development of computer engineering led to the emergence in 1985 of the computer "Elbrus-2". This supercomputer was an order of magnitude more powerful - 125 million operations per second. In total, up to 200 of these machines were produced, some of which are still used today, for example, in missile defense systems.

Elbrus-2 components
In addition to supercomputers, a general-purpose computer “Elbrus 1-KB” was also developed. KBshka was created to replace the outdated BESM-6 . It implemented software compatibility with BESM-6. The productivity of the new computer was 2.5-3 million operations per second.

Elbrus 1-KB
After the release of Elbrus-2, work began on the last computer of the family - Elbrus-3. By 1991, under the leadership of Boris Babayan, work on the new computer was completed. The machine had a performance of up to 1 billion operations per second, coupled with 16 processors, but turned out to be too cumbersome. Due to its shortcomings, as well as the historical and economic context of that period, "Elbrus-3" did not get into serial production, but the ideas put into it influenced the modern generation of "Elbrus".
MCST - the era of modern Russia
After the collapse of the USSR, on the basis of the team that worked on Elbrus-3, the Moscow Center of SPARK Technologies LLP, or simply MCST, was founded. Having worked for some time with the American company Sun Microsystems, now taken over by Oracle, and having gained experience and knowledge, MCST decides to create a processor based on the ideas of Elbrus-3. On February 25, 1999, Boris Babayan (the one who worked on Elbrus-3) at the Microprocessor Forum announced that his company (MCST) had developed the Elbrus-2000 microprocessor, which in all respects is ahead of the vaunted Itanium.

It is worth taking a digression here and describing Itanium in more detail. In 1989, the notorious Intel company joined forces with the notorious HP company to create a new generation Itanium processor. As conceived, Itanium was supposed to implement all the coolest developments of that time and become the "king" of processors. This processor was expected to dominate many markets. The expected clock speed was 800 MHz on the IA-64 architecture . Looking ahead, it should be said that the processor was greeted rather cool against the backdrop of the success of the x86 architecture.

Anyway, such statements shocked the public - how did a little-known company develop a processor cooler than Intel? The promised processor had a frequency of 1.2 GHz, and the performance was equal to 8.9 billion operations per second. Even in physical parameters, the declared "Elbrus" was superior to Itanium - the die area was 126mm2 versus 300mm2 and the heat dissipation was 35W versus 60W. And the cherry on the cake was the required amount, announced by Babayan, for the release of a trial batch - $ 60 million. Coupled with the fact that no developments were shown, potential investors did not dare to invest in the “paper” flagship of MCST.

In 2001, Itanium is released, which, as mentioned above, is not very well received. It seemed that this was the moment when it was possible to show Kuzkin's mother to Western corporations. In 2002, in an interview with ExtremeTech magazine, Babayan raised the bar even more, stating that the processor would have a clock speed of 3 GHz, but the amount required to start production increased to a record $ 100 million.
But the announced parameters were not achieved. In July 2008, the processor "Elbrus 2000" or "Elbrus-3M" was shown to the public. It clocked at 300 MHz and outperformed the 500 MHz Pentium 3 released in 1999 in comparative tests. The following processors of the Elbrus family develop and improve the Elbrus 2000 processor. Below is information about all processors of the "Elbrus" family:
"Elbrus 2000"

| Characteristic | Description |
| Year of issue | Production since 2008 |
| Process technology, nm | 130 |
| Number of Cores | one |
| Clock frequency, GHZ | 0.3 |
| Performance, Gflops | 4.8 - 32 bits; 2.4 - 64 bits |
| Power, W | 6 |
| Kesh | Level 1 - 64 KB + 64 KB (commands + data); Level 2 - 256 KB |
| Number of transistors, million | 75.8 |
"Elbrus-S"

| Characteristic | Description |
| Year of issue | Introduced to the public in October 2010 |
| Process technology, nm | 90 |
| Number of Cores | one |
| Clock frequency, GHZ | 0.5 |
| Performance, Gflops | 8 - 32 bits; 4 - 64 bits |
| Power, W | 13 - typical; 20 - maximum |
| Kesh | 1 — 64 + 64 (+);2 — 2 |
| , | 218 |
«-2C+»

| 2011 | |
| , | 90 |
| 2 + 4 | |
| , | 0,5 |
| , | 28 — 32 ; 8 — 64 |
| , | 25 |
| 1 — 64 + 64 (+);2 — 1 | |
| , | 368 |
«-4C»

| 2015 | |
| , | 65 |
| 4 | |
| , | 0,8 |
| , | 50 — 32 ; 25 — 64 |
| , | 60 |
| 1 — 128 + 64 (+);2 - 8 | |
| , | 986 |
«-1C+»

| 2015 | |
| , | 40 |
| 1 + 1 2D + 1 3D | |
| , | 1 |
| , | 24 — 32 ; 12 — 64 |
| , | 10 |
| 1 — 128 + 64 (+);2 - 2 | |
| , | 375 |
«-8C»

| 2016 | |
| , | 28 |
| 8 | |
| , | 1,3 |
| , | 250 — 32 ; 125 — 64 |
| , | 80 |
| 1 — 128 + 64 (+);2 - 4 ;3 — 16 | |
| , | 2730 |
«-8CB»

| 2020 | |
| , | 28 |
| 8 | |
| , | 1,5 |
| , | 576 — 32 ; 288 — 64 |
| , | 90 |
| 1 — 128 + 64 (+);2 - 4 ;3 — 16 | |
| , | 3500 |
At the moment, the main consumer of Elbrus processors is the state. It both subsidizes MCST projects and is the main customer. MCST positions the Elbrus family as a powerful server hardware, which corresponds to the municipal needs for processing a large amount of information. According to MCST representatives, they supply processors only for legal entities, so the company's turnover is relatively small, which negatively affects the cost of one processor. So, according to some reports , the cost of "Elbrus-4C" reached 400 thousand rubles.

Source - mcst.ru
Elbrus architecture
First of all, it should be said that the Elbrus architecture is an original Russian design. And although the flagships of the family with the 28 nm process technology are currently being manufactured in Taiwanese factories, this is still better than nothing. According to the developers from MCST, the main advantage of Elbrus is energy efficiency and software-controlled parallelism of operations. Surely, those who were interested in the topic heard about the optimizing compiler and "broad commands". To understand what the essence is, let's figure out the existing ways to speed up the execution of commands in microprocessors.
Superscalar and VLIW processors
The simplest scalar processor can execute one machine instruction per clock cycle. The commands are lined up in a chain, the order of which is set in machine code. In this case, the next command does not start executing until the old one ends. This approach is justified when the next command uses the results of the previous one. But this is completely optional: teams can be independent. Therefore, the developers of microprocessors began to think about how to speed up the execution of commands. As a result, two main approaches have been developed.
In the first, the command is split into several sequential stages: read the command from memory, decode it, read the parameters of this command, send to the executive device, write the result of the command to the destination register. If you split a command into several different stages, you can run the next command before the previous one has finished. This approach is called pipelining , similar to industrial production.
The second way involves finding in the sequence of commands those that do not intersect in arguments and results (in terms of used and defined resources). Such a group can be launched for execution simultaneously, hence the name of the approach - parallel grouping of commands .
If you think a little and compare the described approaches, you will find that they do not contradict each other. Microprocessor architectures that combine these principles are called in-order superscalar . In the 60s, the next step was implemented - changing the sequence of commands relative to each other right in the process of execution. This approach is called out-of-order superscalar (OOOSS). Most modern representatives of RISC and CISC architectures (x86, PowerPC, SPARC, MIPS, ARM) are OOOSS. The evolution of approaches to parallel execution of multiple instructions is shown below.
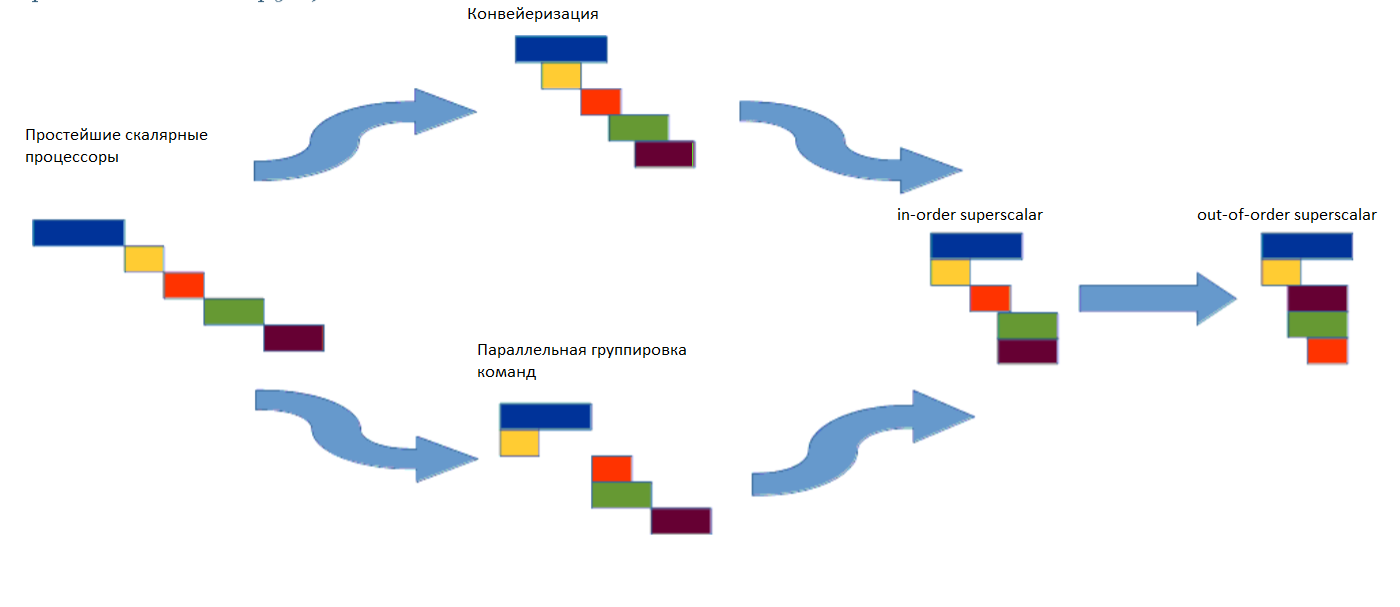
Moving from scalar processors to superscalar processors with the ability to swap instructions
In the 1980s, an alternative processor architecture began to develop. Their main distinguishing feature is the reordering of commands not at runtime, but at compilation time. Also, a key characteristic was the use of the so-called wide commands, which made it possible to express the parallelism of many operations in assembler (this is the program-controlled parallelism of operations, which was mentioned at the beginning of the section). This architecture is called a very long instruction word ( VLIW ). Elbrus belongs to this type.
About the "wide team"
In traditional RISC and CISC, the responsibility for dependency analysis, scheduling, and register allocation rests with the hardware. In Elbrus, the compiler does this job. Accordingly, the processor receives “wide commands” as input, each of which encodes operations for all the processor's execution units that should be launched at a given cycle. This greatly simplifies the hardware, since the processor does not need to analyze dependencies between operands or swap operations between wide instructions: the compiler will do all this by scheduling operations based on the resources of the wide instruction. Let's look at the structure of a wide team.
A wide command is understood as a set of elementary Elbrus operations that can be launched for execution in one clock cycle. From the point of view of executive devices, the following are available in a wide team:
- 6 arithmetic logic devices (ALU) performing the following operations:
- 1 device for a transfer of control (CT) operation;
- 3 devices for operations on predicates (PL);
- 6 qualifying predicates (QP);
- 4 devices for asynchronous data reading commands at regular addresses in a cycle (APB);
- 4 literals of size 32 bits for storing constant values (LIT);

Wide team "Elbrus"
The average degree of filling a wide team with useful operations largely reflects the performance of the processor. We can say that the task of improving the performance of code on VLIW architectures is to statically (at compile time) detect parallelism at the operation level, schedule operations taking into account the found parallelism, ensure that a wide team is well filled with useful operations and various optimizations.
Features of the architecture
Register file . A significant number of operational registers are required for parallel execution of operations. The so-called register file contains 256 registers for integer and real data, 32 of them are intended for global data, the remaining 224 are for the procedure stack.
There are also 32 two-bit predicate registers in the system that make up the predicate file . The predicate device performs operations on predicate registers, and the duration of the operation is half a cycle. Therefore, in one cycle, you can plan logical operations, where the second group uses the results of the first.
To speed up the program, you can perform operations before the direction of the conditional branch becomes known, or read data from memory before the previous write. But such methods are not always correct, since non-deterministic behavior during execution is possible. For example, if a conditional branch is executed before a conditional branch, an operation that should not be executed may cause an interrupt. And if you read before the previous write, the wrong value may be read from memory. For such situations, modes of speculative control and speculative data are introduced into the architecture .
Pre-transfer control... Preempting the code in the direction of branching, as well as its primary processing on an additional pipeline (against the background of the execution of the main branch) hide the delay in accessing the program code during control transfers. Thus, it is possible to transfer control without stopping the execution pipeline when the branching condition is already known.
Using the mechanism of predicate and speculative execution of operations , it is possible to plan operations related to different control branches in one wide command, get rid of expensive branch operations and transfer arithmetic-logical operations through branch operations.
Loop pipelining is also possible , which allows the most efficient execution of loops with independent or weakly dependent iterations. In a program-pipelined loop, successive iterations are performed with overlapping - one or more subsequent iterations start before the current one ends. The step with which the iterations are superimposed determines the overall rate of their execution, and this rate can be significantly higher than with strictly sequential execution of iterations. This way of organizing the execution of the loop allows you to make good use of the resources of the wide team and gain a performance advantage.
Asynchronous accessto arrays allows you to buffer data from memory regardless of the execution of commands of the main thread. Requests to data should be formed in a loop, and addresses should linearly depend on the iteration number. Asynchronous access is implemented in the form of an independent additional loop, in which only the operations of swapping data from memory into the FIFO are encoded. Data is retrieved from the buffer by operations of the main loop. The length of the buffer and the asynchronous nature of the independent loop allow eliminating locks on reading data in the main execution thread.
Comparison of VLIW and OOOSS. Advantages and disadvantages
Let's briefly describe the main differences between VLIW and OOOSS
VLIW:
- Parallelism of elementary operations execution explicitly expressed in the code.
- Accurate, consistent execution of wide commands.
- The special role of optimizing compilation.
- Additional architectural solutions to improve the parallelism of operations.
OOOSS:
- Rearrangement and parallel execution of operations is provided by hardware within the window of currently executing operations.
- Reordering uses hidden buffers, hidden register file, implicit speculativeness.
- A fairly large window for looking for parallelism in instruction permutations is provided by a hardware branch predictor.
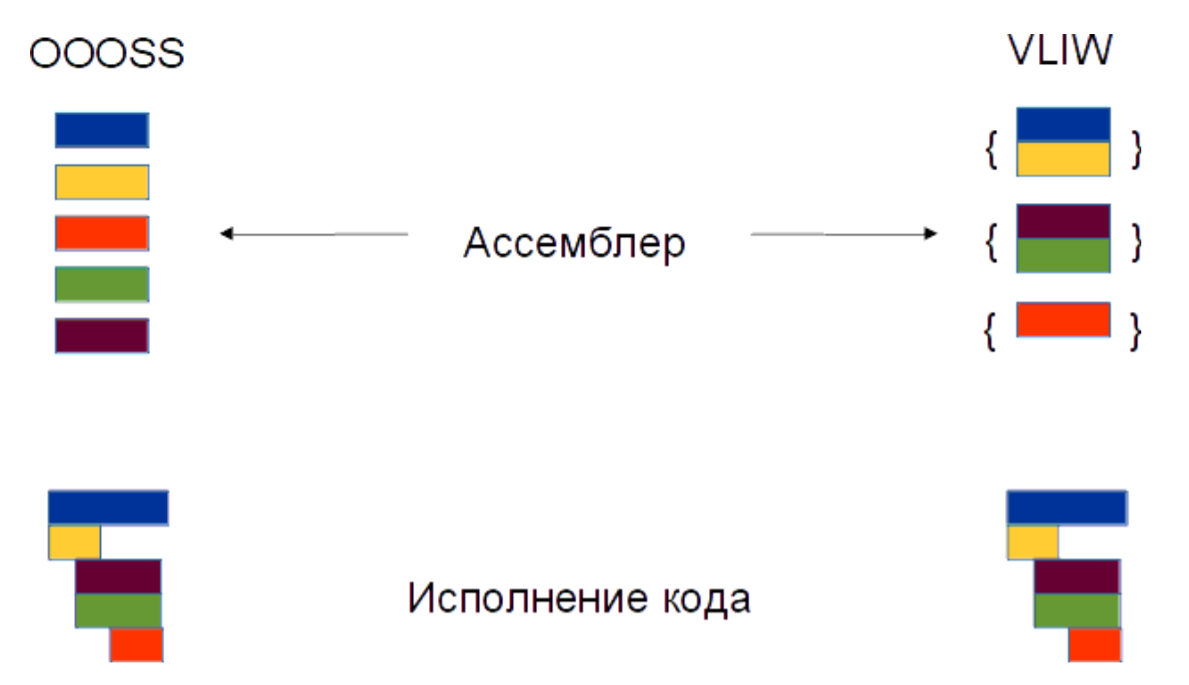
Code execution in OOOSS and VLIW. The red command depends on yellow and requires it to be completed, while the brown and green operations do not depend on yellow, so they can be performed earlier.
VLIW advantages and disadvantages
| Benefits | disadvantages |
| More open possibilities for expressing instruction parallelism. | Possible performance degradation when executing legacy codes. |
| Better energy efficiency with similar performance. | More complex code for debugging and analysis. |
| More complex compiler. |
Advantages and disadvantages of OOOSS:
| Benefits | disadvantages |
| Efficient execution of legacy codes. | Energy consumption for multiple scheduling of the same operations. |
| Additional information about the parallelism of operations, available in the dynamics of execution. | Hardware limitation of the window of executable operations for reordering. |
What is the problem to go straight to the technical process, like that of Apple, AMD or Intel?
Elbrus processors are manufactured in the same factories in Taiwan as Apple or AMD. Why can't you immediately implement the same technical process as those of these companies? The main problem is that MCST does not have the appropriate technology at the moment. Reason one: no leading-edge company will sell 5nm or 7nm processor technology. Also, manufacturers make sure that their technology cannot be stolen. Reason two: budget. The processor is developed for a specific factory on its licensed software. Moreover, the smaller the technical process, the higher the cost of the license. And MCST doesn't have problems with the budget, but they don't bathe in gold either. And this is just one of the economic aspects of processor design. And the third reason: in order to create a good processor,based on 5nm or 7nm technology, it is necessary to go through all the stages of development: 65nm, 40nm, 28nm and so on. Of course, it would be possible to immediately make a processor based on 7 nm technology, but the resulting product will not have good performance and is unlikely to be able to become competitive.
Cloud VPS with fast NVM drives and daily payment from Macleod hosting.
