Aside Needed: Apache Ignite Cluster
A cluster in Ignite is a set of server and client nodes, where server nodes are combined into a logical structure in the form of a ring, and client nodes are connected to the corresponding server nodes. The main difference between client nodes and server nodes is that the former do not store data.

Data, from a logical point of view, belongs to partitions, which, in accordance with some affinity function, are distributed across nodes ( more about data distribution in Ignite ). The primary ( primary ) partitions can have copies ( backups ).
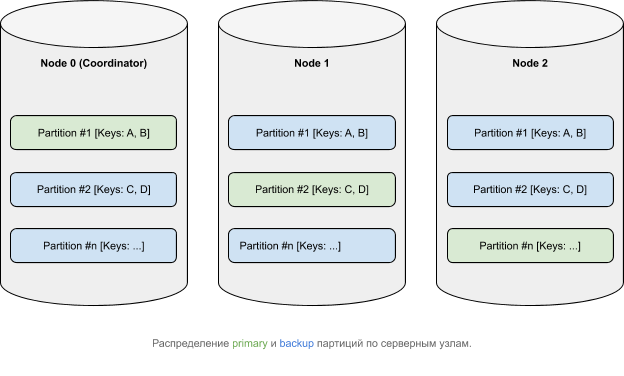
How transactions work in Apache Ignite
The cluster architecture in Apache Ignite imposes a certain requirement on the transaction mechanism: data consistency in a distributed environment. This means that data located on different nodes must be changed in a holistic manner in terms of ACID principles. There are a number of protocols available to do what you want. Apache Ignite uses a two-phase commit algorithm that consists of two stages:
- prepare;
- commit;
Note that, depending on the level of isolation of the transaction , the mechanism for taking locks, and a number of other parameters, the details in the phases may change.
Let's see how both phases take place using the following transaction as an example:
Transaction tx = client.transactions().txStart(PESSIMISTIC, READ_COMMITTED);
client.cache(DEFAULT_CACHE_NAME).put(1, 1);
tx.commit();
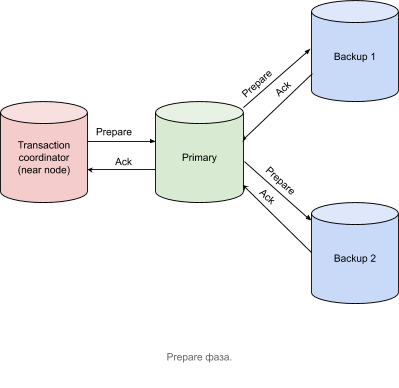
Prepare phase
- — (near node Apache Ignite) — prepare- , primary- , .
- primary- Prepare- backup-, , . backup- .
- backup- Acknowledge- primary-, , , , .
Commit
After receiving acknowledgment messages from all nodes containing primary partitions, the transaction coordinator node sends a Commit message, as shown in the figure below.
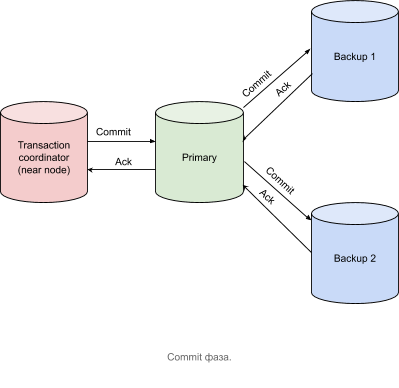
A transaction is considered complete the moment the transaction coordinator has received all Acknowledgment messages.
From theory to practice
To consider the logic of a transaction, let's turn to tracing.
To enable tracing in Apache Ignite, follow these steps:
- Let's enable the ignite-opencensus module and set OpenCensusTracingSpi as tracingSpi through the cluster configuration:
<bean class="org.apache.ignite.configuration.IgniteConfiguration"> <property name="tracingSpi"> <bean class="org.apache.ignite.spi.tracing.opencensus.OpenCensusTracingSpi"/> </property> </bean>
or
IgniteConfiguration cfg = new IgniteConfiguration(); cfg.setTracingSpi( new org.apache.ignite.spi.tracing.opencensus.OpenCensusTracingSpi());
- Let's set some non-zero level of sampling transactions:
JVM_OPTS="-DIGNITE_ENABLE_EXPERIMENTAL_COMMAND=true" ./control.sh --tracing-configuration set --scope TX --sampling-rate 1
or
ignite.tracingConfiguration().set( new TracingConfigurationCoordinates.Builder(Scope.TX).build(), new TracingConfigurationParameters.Builder(). withSamplingRate(SAMPLING_RATE_ALWAYS).build());
:
- API
JVM_OPTS="-DIGNITE_ENABLE_EXPERIMENTAL_COMMAND=true" - sampling-rate , , . , .
- , SPI, . , , .
- API
- PESSIMISTIC, SERIALIZABLE .
Transaction tx = client.transactions().txStart(PESSIMISTIC, SERIALIZABLE); client.cache(DEFAULT_CACHE_NAME).put(1, 1); tx.commit();
Let's turn to the GridGain Control Center (a detailed overview of the tool) and take a look at the resulting span tree: In the illustration, we can see that the transaction root span, created at the beginning of the transactions (). TxStart call, spawns two conditional span groups:
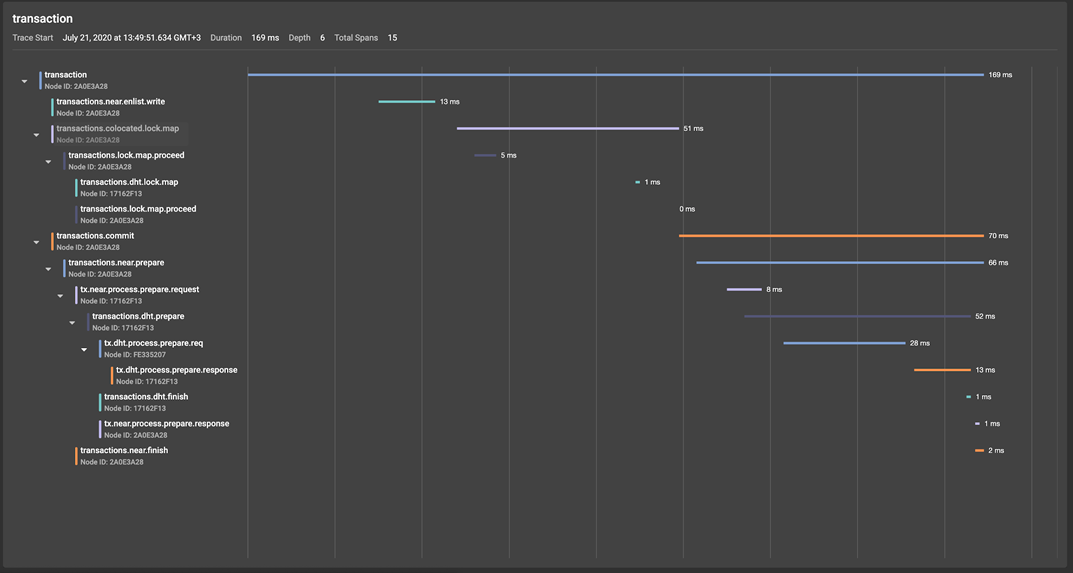
- The lock capture machine initiated by the put () operation:
- transactions.near.enlist.write
- transactions.colocated.lock.map
- transactions.commit, tx.commit(), , , — prepare finish Apache Ignite (finish- commit- ).
Let's now take a closer look at the prepare-phase of a transaction, which, starting at the transaction coordinator node (near-node in Apache Ignite terms), produces the transactions.near.prepare span.
Once on the primary partition, the prepare-request triggers the creation of transactions.dht.prepare span, within which prepare-requests are sent to the tx.process.prepare.req backups, where they are processed by tx.dht.process.prepare.response and sent back to the primary partition, which sends a confirmation message to the transaction coordinator, along the way creating a span tx.near.process.prepare.response. The Finish phase in this example will be similar to the prepare phase, which saves us from the need for detailed analysis.
By clicking on any of the spans, we will see the corresponding meta information:
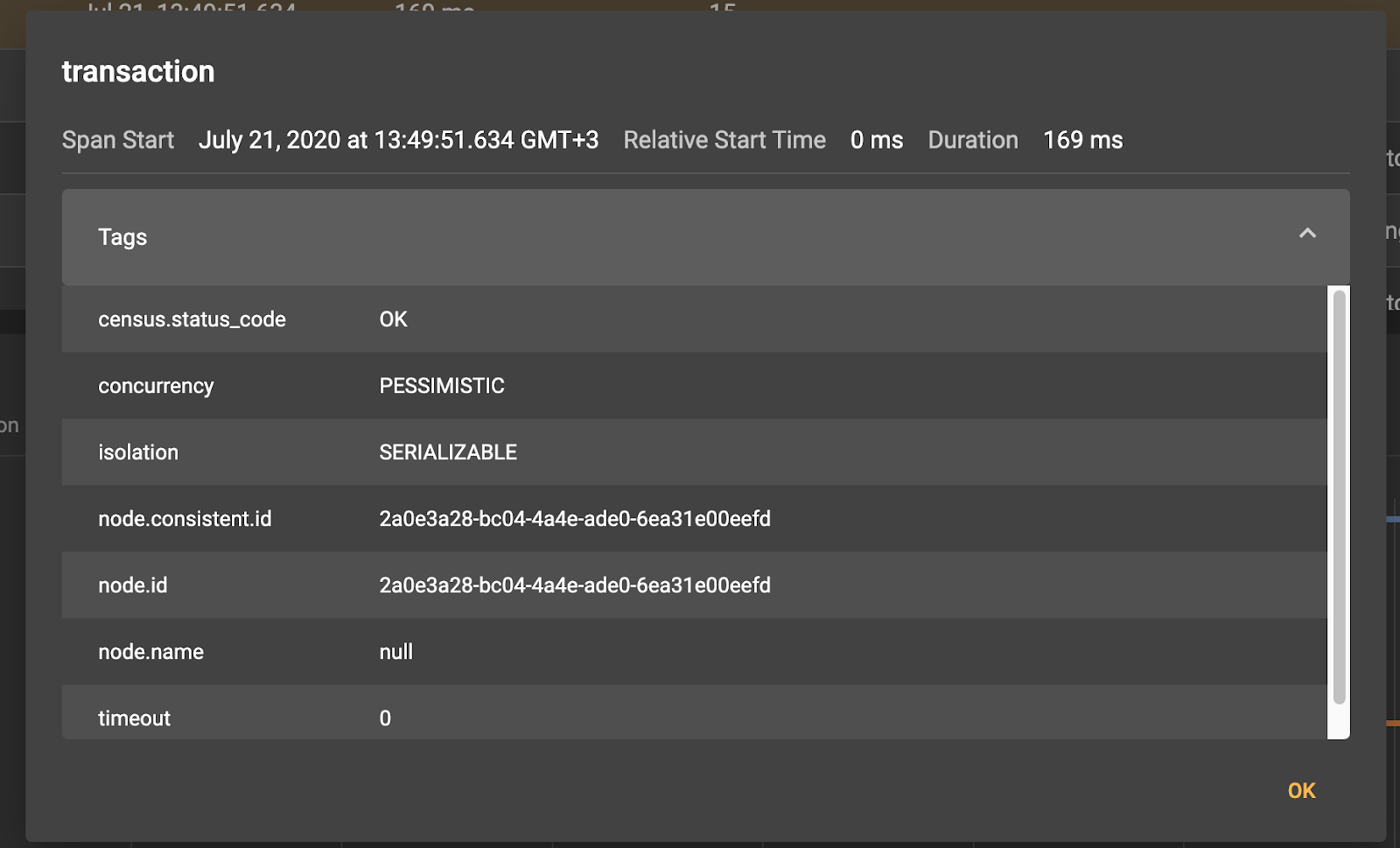
So, for example, for the root transaction span, we see that it was created on the client node 0eefd.
We can also increase the granularity of transaction tracing by enabling tracing of the communication protocol.
Setting up tracing parameters
JVM_OPTS="-DIGNITE_ENABLE_EXPERIMENTAL_COMMAND=true" ./control.sh --tracing-configuration set --scope TX --included-scopes Communication --sampling-rate 1 --included-scopes COMMUNICATION ignite.tracingConfiguration().set(
new TracingConfigurationCoordinates.Builder(Scope.TX).build(),
new TracingConfigurationParameters.Builder().
withIncludedScopes(Collections.singleton(Scope.COMMUNICATION)).
withSamplingRate(SAMPLING_RATE_ALWAYS).build())

Now we have access to information about the transmission of messages over the network between cluster nodes, which, for example, will help answer the question of whether a potential problem was caused by nuances of network communication. We will not dwell on the details, we only note that the set of socket.write and socket.read spans are responsible for writing to the socket and reading one or another message, respectively.
Exception Handling and Crash Recovery
Thus, we see that the implementation of the distributed transaction protocol in Apache Ignite is close to the canonical one and allows you to obtain the proper degree of data consistency, depending on the selected transaction isolation level. Obviously, the devil is in the details and a large layer of logic remained outside the scope of the material analyzed above. For example, we have not considered the mechanisms of operation and recovery of transactions in the event of a fall of the nodes participating in it. We will fix this now.
We said above that in the context of transactions in Apache Ignite, three types of nodes can be distinguished:
- Transaction coordinator (near node);
- Primary node for the corresponding key (primary node);
- Nodes with backup key partitions (backup nodes);
and two phases of the transaction itself:
- Prepare;
- Finish;
Through simple calculations, we will get the need to process six options for node crashes - from a backup fall during the prepare-phase to a fall of the transaction coordinator during the finish-phase. Let's consider these options in more detail.
Falling backup both on prepare and on finish-phases
This situation does not require any additional action. The data will be transferred to the new backup nodes independently as part of the rebalance from the primary node.

Falling primary-node in the prepare-phase
If there is a risk of receiving inconsistent data, the transaction coordinator throws an exception. This is a signal to transfer control to make a decision to restart the transaction or another way to resolve the problem to the client application.
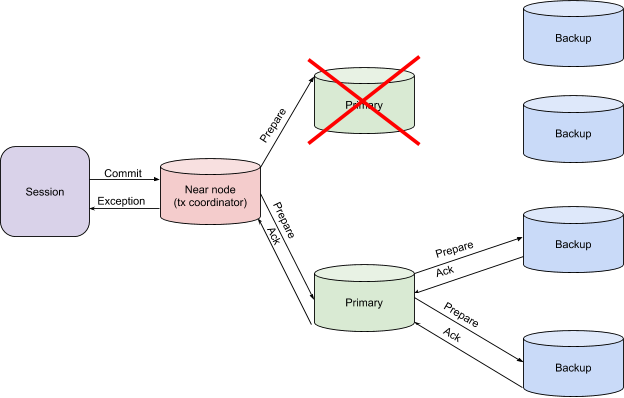
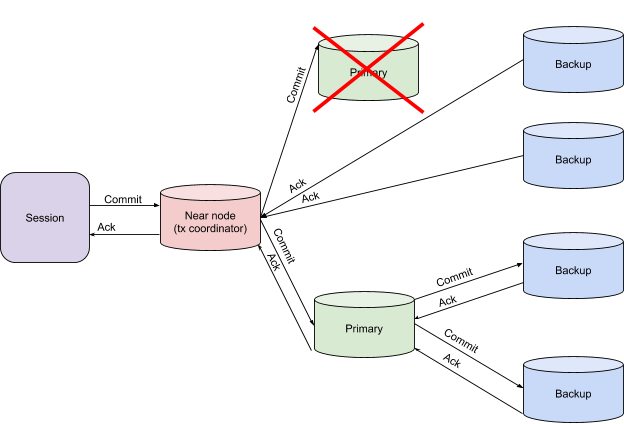
Fall of the primary node in the finish phase
In this case, the transaction coordinator waits for additional NodeFailureDetection messages, after receiving which it can decide on the successful completion of the transaction, if the data was written on the backup partitions.
Fall of the transaction coordinator
The most interesting case is loss of transaction context. In such a situation, the primary and backup nodes directly exchange the local transactional context with each other, thereby restoring the global context, which allows a decision to be made to verify the commit. If, for example, one of the nodes reports that it did not receive a Finish message, the transaction will be rolled back.

Summary
In the above examples, we examined the flow of transactions, illustrating it using tracing, which shows the internal logic in detail. As you can see, the implementation of transactions in Apache Ignite is close to the classic concept of a two-phase commit, with some tweaks in the area of transaction performance related to the mechanism for taking locks, features of recovery after failures, and transaction timeout logic.