
Our world is generating more and more information. Some part of it is fleeting and is lost as quickly as it is collected. The other should be stored longer, while the other is designed "for centuries" - at least this is how we see it from the present. Information flows are settling in data centers at such a speed that any new approach, any technology designed to satisfy this endless "demand" is rapidly becoming obsolete.
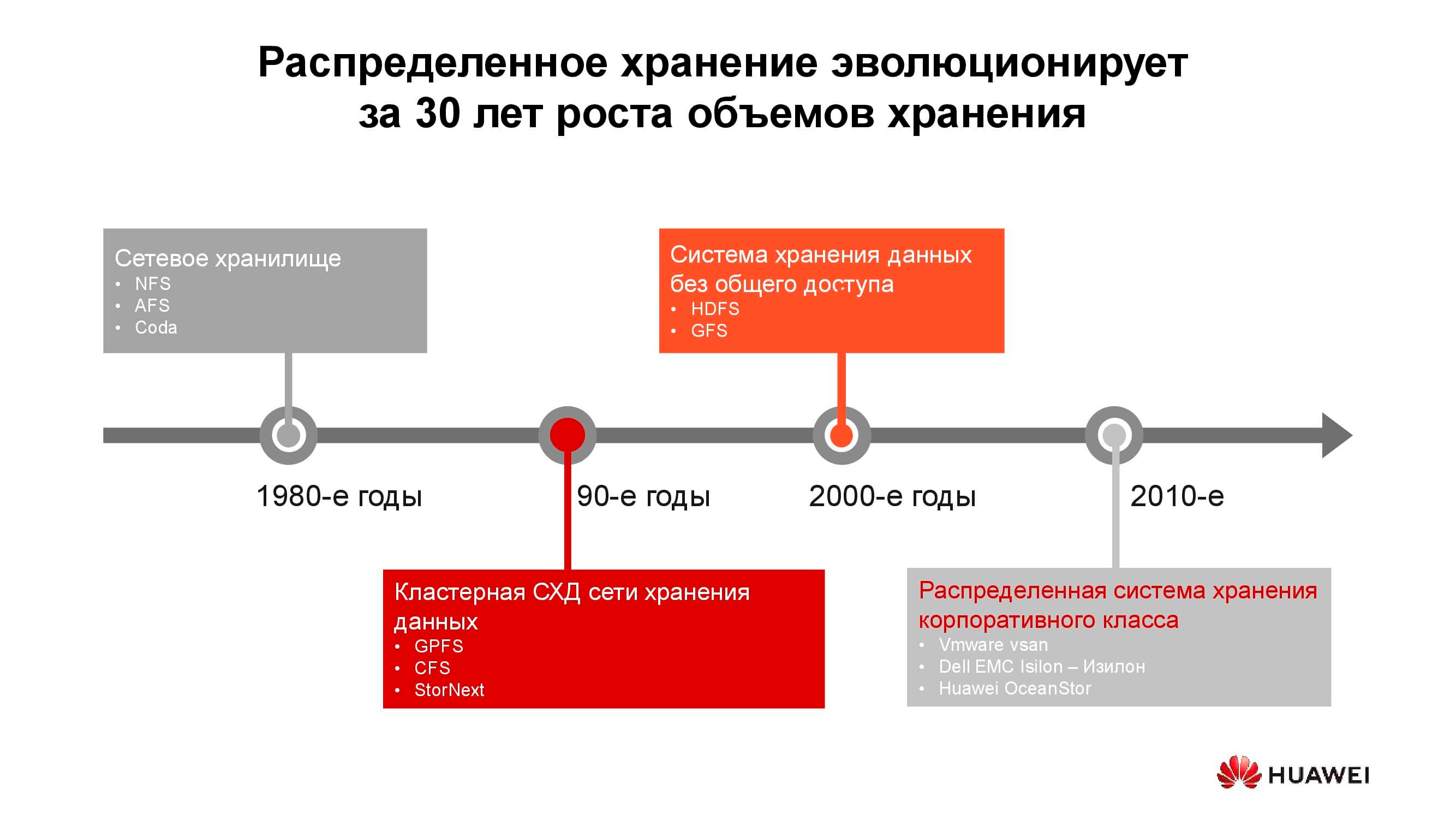
40 years of development of distributed storage systems
The first network attached storages appeared in the usual form in the 1980s. Many of you have come across NFS (Network File System), AFS (Andrew File System) or Coda. A decade later, fashion and technology have changed, and distributed file systems have given way to clustered storage systems based on GPFS (General Parallel File System), CFS (Clustered File Systems) and StorNext. As a basis, block storages of classical architecture were used, on top of which a single file system was created using a software layer. These and similar solutions are still in use, occupy their own niche and are quite in demand.
At the turn of the millennium, the distributed storage paradigm changed somewhat, and systems with the SN (Shared-Nothing) architecture took the lead. There was a transition from cluster storage to storage on separate nodes, which, as a rule, were classic servers with software that provide reliable storage; on such principles are built, say, HDFS (Hadoop Distributed File System) and GFS (Global File System).
Closer to the 2010s, the underlying concepts of distributed storage were increasingly reflected in full-fledged commercial products such as VMware vSAN, Dell EMC Isilon and our Huawei OceanStor.... The platforms mentioned are no longer a community of enthusiasts, but specific vendors who are responsible for the functionality, support, service of the product and guarantee its further development. Such solutions are most in demand in several areas.
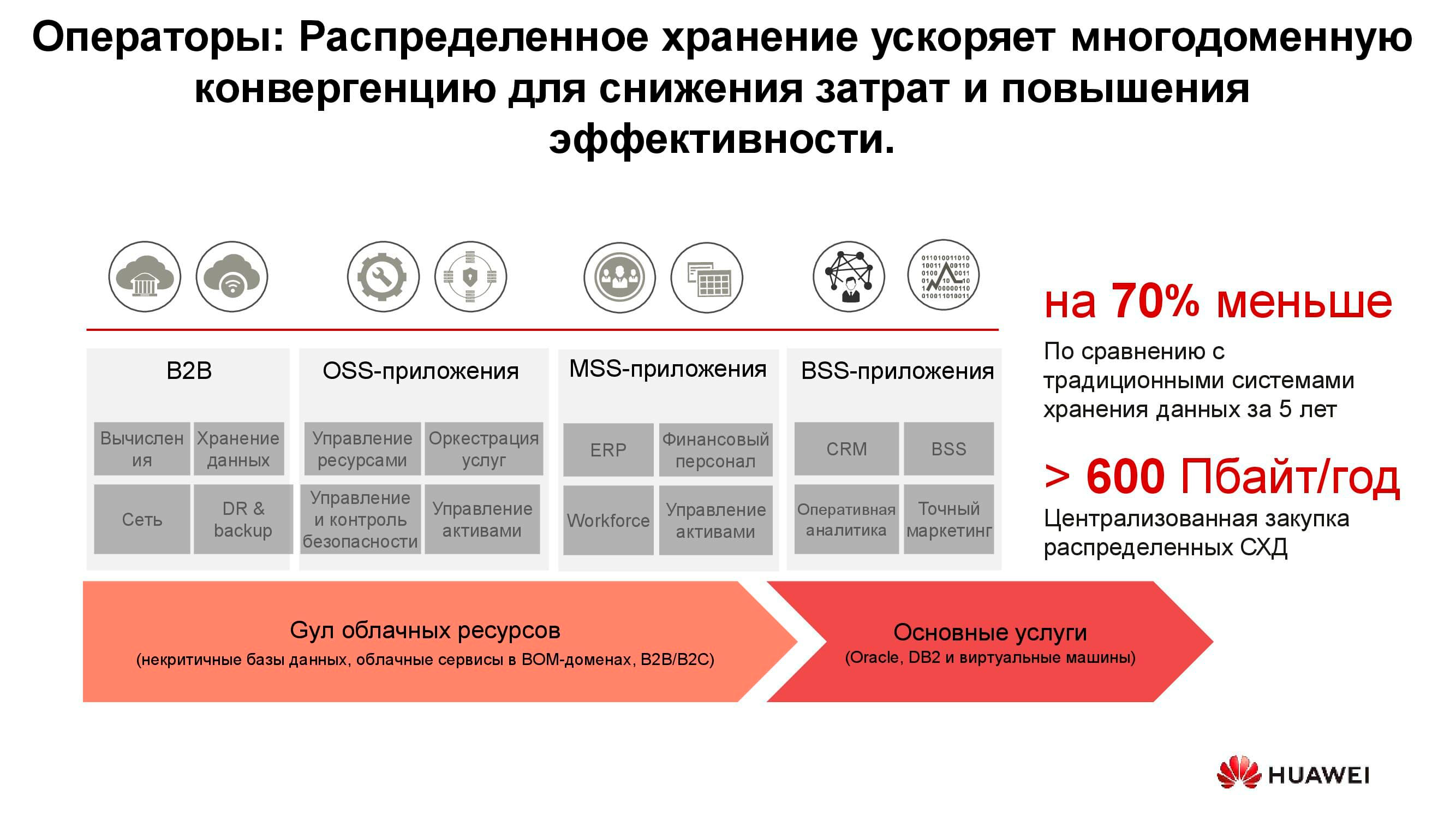
Telecom operators
Perhaps one of the oldest consumers of distributed storage systems are telecom operators. The diagram shows which application groups produce the bulk of the data. OSS (Operations Support Systems), MSS (Management Support Services) and BSS (Business Support Systems) are three complementary software layers required to provide service to subscribers, financial reporting to the provider and operational support to the operator's engineers.
Often, the data of these layers is strongly mixed with each other, and in order to avoid the accumulation of unnecessary copies, distributed storages are used, which accumulate the entire amount of information coming from the working network. Storages are combined into a common pool, to which all services refer.
Our calculations show that the transition from classic storage systems to block storage systems allows you to save up to 70% of the budget only by eliminating dedicated storage systems of the hi-end class and using conventional servers of classical architecture (usually x86), working in conjunction with specialized software. Cellular operators have long begun to purchase such solutions in serious volumes. In particular, Russian operators have been using such products from Huawei for more than six years.
Yes, a number of tasks cannot be performed using distributed systems. For example, with increased performance requirements or compatibility with older protocols. But at least 70% of the data that the operator processes can be located in a distributed pool.
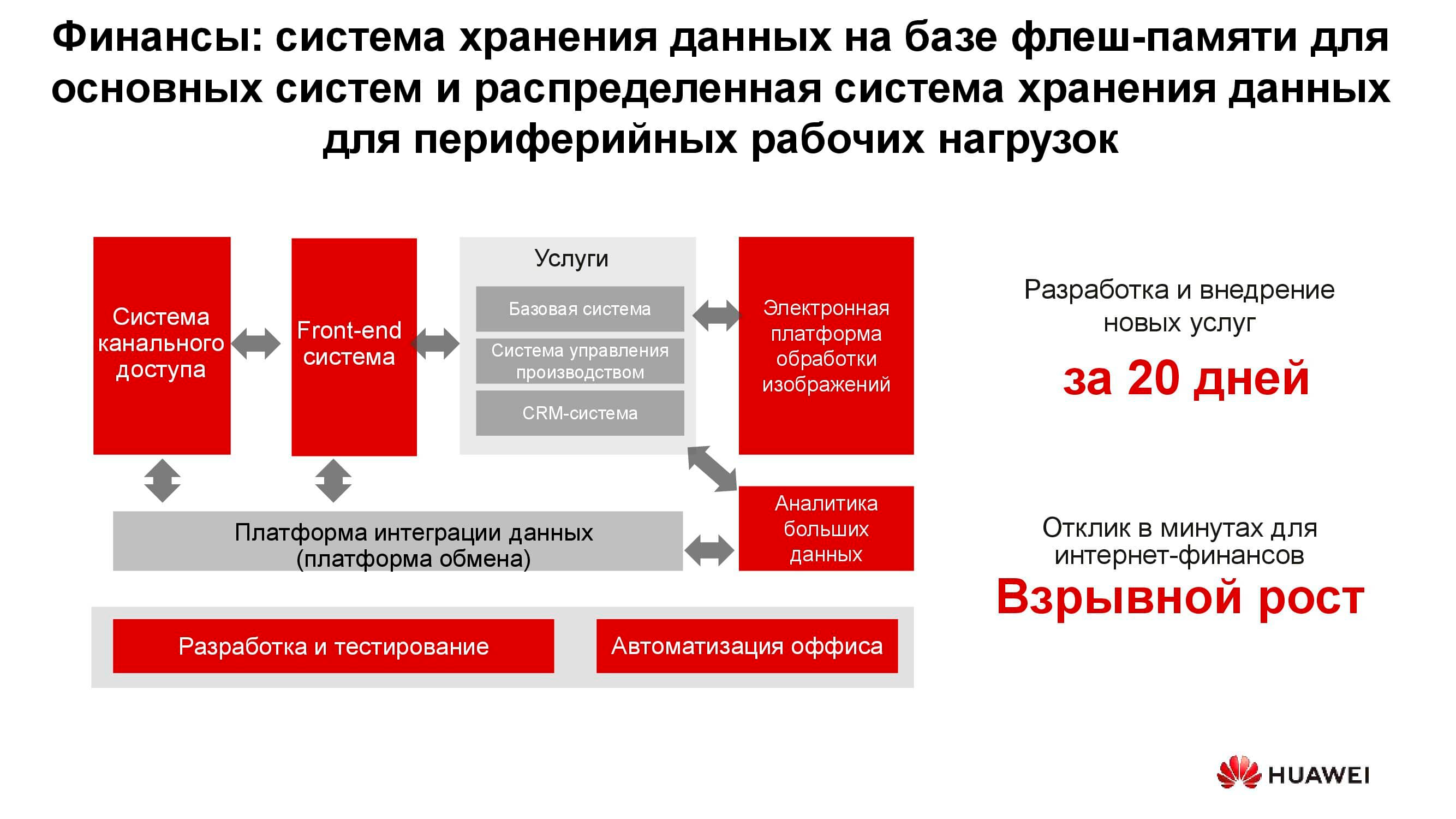
Banking sector
In any bank, there are many different IT-systems coexisting, from processing to an automated banking system. This infrastructure also works with a huge amount of information, while most of the tasks do not require increased performance and reliability of storage systems, for example, development, testing, automation of office processes, etc. Here, the use of classical storage systems is possible, but every year it is less and less profitable. In addition, in this case, there is no flexibility in the use of storage resources, the performance of which is calculated from the peak load.
When using distributed storage systems, their nodes, which in fact are ordinary servers, can be converted at any time, for example, into a server farm and used as a computing platform.
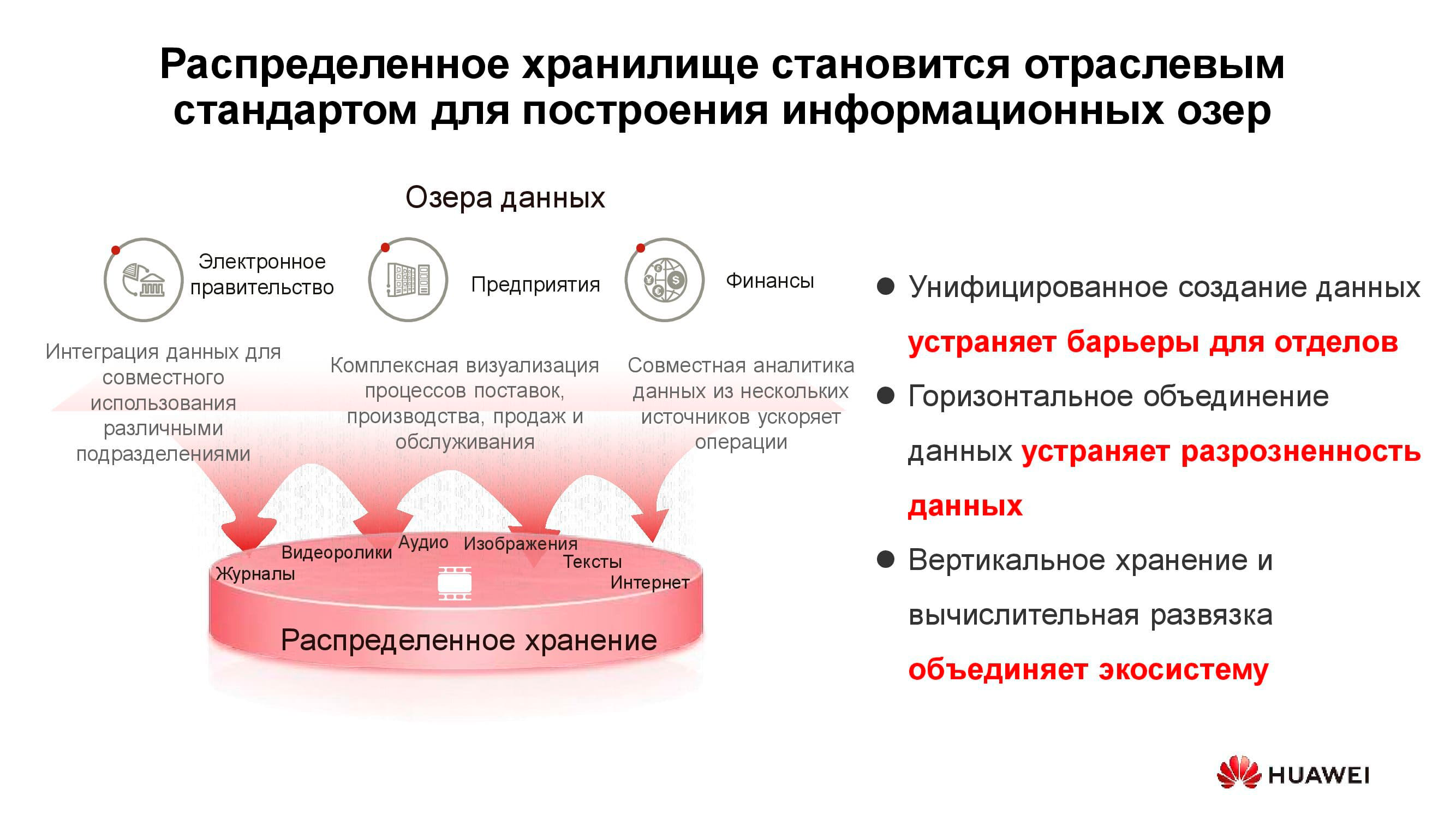
Data lakes
The diagram above shows a list of typical consumers of data lake services . These can be e-government services (for example, "Gosuslugi"), digitized enterprises, financial structures, etc. They all need to work with large volumes of heterogeneous information.
The operation of classic storage systems to solve such problems is ineffective, since both high-performance access to block databases and regular access to libraries of scanned documents stored as objects are required. This can also be linked, for example, an ordering system through a web portal. To implement all this on a classic storage platform, you will need a large set of equipment for different tasks. One horizontal universal storage system may well cover all the previously listed tasks: you just need to create several pools in it with different storage characteristics.

Generators of new information
The amount of information stored in the world is growing by about 30% per year. This is good news for storage vendors, but what is and will be the main source of this data?
Ten years ago, social networks became such generators, which required the creation of a large number of new algorithms, hardware solutions, etc. Now there are three main drivers of growth in storage volumes. The first is cloud computing. Currently, about 70% of companies use cloud services in one way or another. These can be email systems, backups, and other virtualized entities.
The second driver is fifth generation networks. These are new speeds and new volumes of data transfer. We predict the widespread adoption of 5G will lead to a drop in demand for flash memory cards. No matter how much memory there is in the phone, it still runs out, and if there is a 100-megabit channel in the gadget, there is no need to store photos locally.
The third group of reasons for the growing demand for storage systems include the rapid development of artificial intelligence, the transition to big data analytics and the trend towards universal automation of everything that is possible.
The peculiarity of the "new traffic" is its unstructuredness... We need to store this data without specifying its format. It is required only for subsequent reading. For example, a banking scoring system to determine the available loan size will look at the photos you posted on social networks, determining whether you often go to the sea and in restaurants, and at the same time study the extracts from your medical documents available to it. These data, on the one hand, are all-encompassing, and on the other, lacking in uniformity.

An ocean of unstructured data
What problems does the emergence of "new data" entail? The foremost among them, of course, is the amount of information itself and the estimated storage time. A modern autonomous car alone without a driver generates up to 60 TB of data every day from all its sensors and mechanisms. To develop new motion algorithms, this information must be processed in the same day, otherwise it will begin to accumulate. Moreover, it should be stored for a very long time - tens of years. Only then in the future it will be possible to draw conclusions based on large analytical samples.
One genetic sequencing device generates about 6 TB per day. And the data collected with its help does not imply deletion at all, that is, hypothetically, it should be stored forever.
Finally, all the same fifth-generation networks. In addition to the actual transmitted information, such a network itself is a huge generator of data: action logs, call records, intermediate results of machine-to-machine interactions, etc.
All this requires the development of new approaches and algorithms for storing and processing information. And such approaches appear.
Technologies of a new era
There are three groups of solutions designed to cope with the new requirements for storage systems: the introduction of artificial intelligence, the technical evolution of storage media, and innovations in the field of system architecture. Let's start with AI.

In new Huawei solutions, artificial intelligence is already used at the level of the storage itself, which is equipped with an AI processor that allows the system to independently analyze its state and predict failures. If the storage system is connected to a service cloud that has significant computational capabilities, artificial intelligence can process more information and improve the accuracy of its hypotheses.
In addition to failures, such an AI is able to predict future peak loads and the time remaining until capacity is exhausted. This allows you to optimize performance and scale the system even before any unwanted events occur.

Now about the evolution of data carriers. The first flash drives were made using SLC (Single-Level Cell) technology. The devices based on it were fast, reliable, stable, but had small capacity and were very expensive. The increase in volume and price reduction was achieved through certain technical concessions, due to which the speed, reliability and lifespan of the drives were reduced. Nevertheless, the trend did not affect the storage systems themselves, which, due to various architectural tricks, in general, have become both more productive and more reliable.
But why did you need All-Flash storage systems? Wasn't it enough to simply replace the old HDDs in an already in use system with new SSDs of the same form factor? It took this in order to efficiently use all the resources of the new solid-state drives, which was simply impossible in old systems.
Huawei, for example, has developed a range of technologies to address this challenge, one of which is FlashLink , which maximizes disk-controller interactions.
Intelligent identification has made it possible to decompose data into multiple streams and cope with a number of undesirable phenomena such as WA (write amplification). At the same time, new recovery algorithms, in particular RAID 2.0+, increased the speed of the rebuild, reducing its time to completely insignificant values.
Failure, overcrowding, "garbage collection" - these factors also no longer affect the performance of the storage system thanks to a special modification of the controllers.
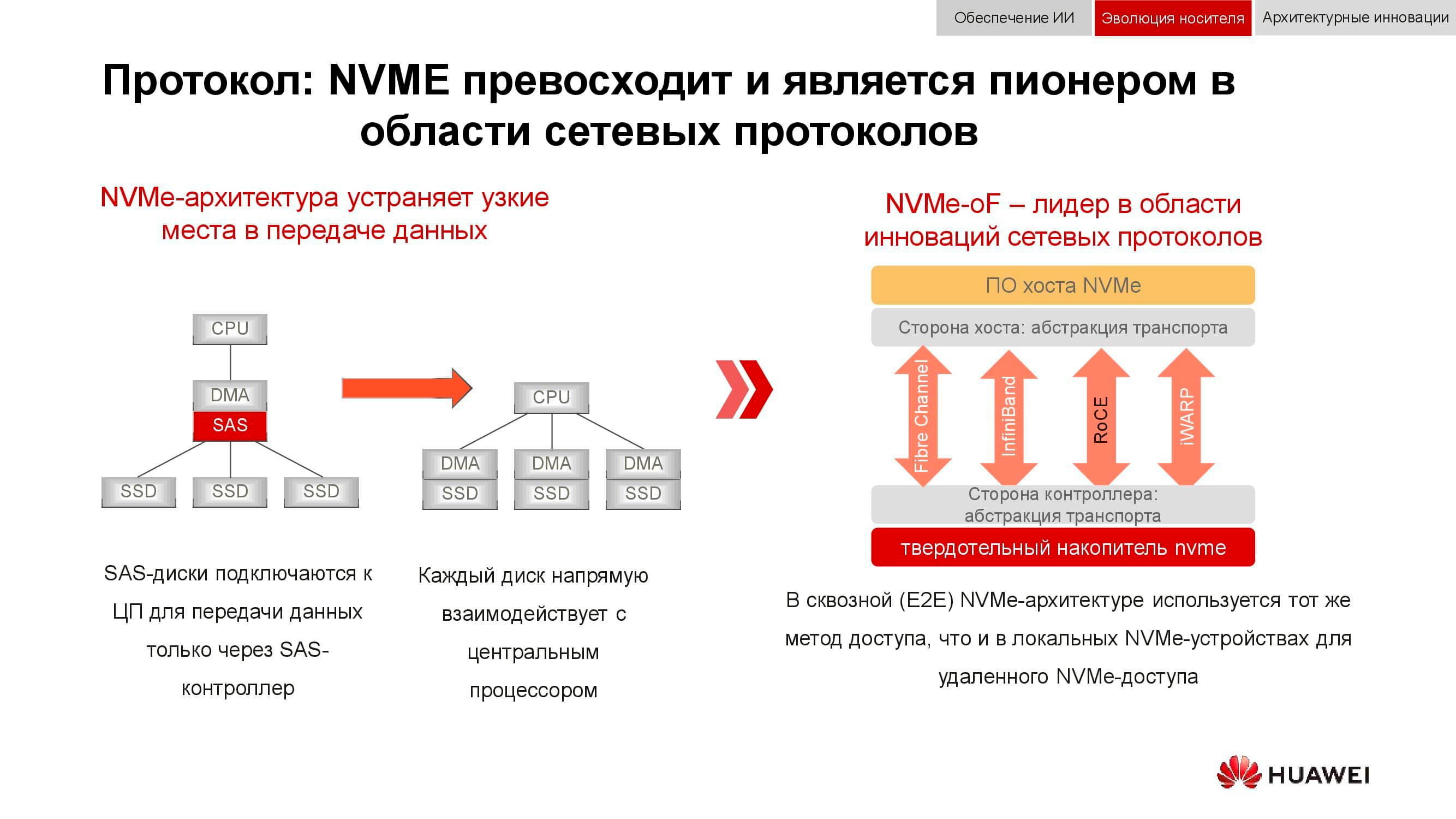
And block data storage is getting ready for NVMe . Recall that the classical scheme for organizing data access worked as follows: the processor accessed the RAID controller via the PCI Express bus. That, in turn, interacted with mechanical disks via SCSI or SAS. The use of NVMe on the backend significantly accelerated the whole process, but it had one drawback: the drives had to be directly connected to the processor in order to provide direct access to memory.
The next phase of technology development that we are seeing now is the use of NVMe-oF (NVMe over Fabrics). As for the Huawei block technologies, they already support FC-NVMe (NVMe over Fiber Channel), and on the NVMe over RoCE (RDMA over Converged Ethernet) approach. The test models are quite functional, several months are left before their official presentation. Note that all this will also appear in distributed systems, where "lossless Ethernet" will be in great demand.
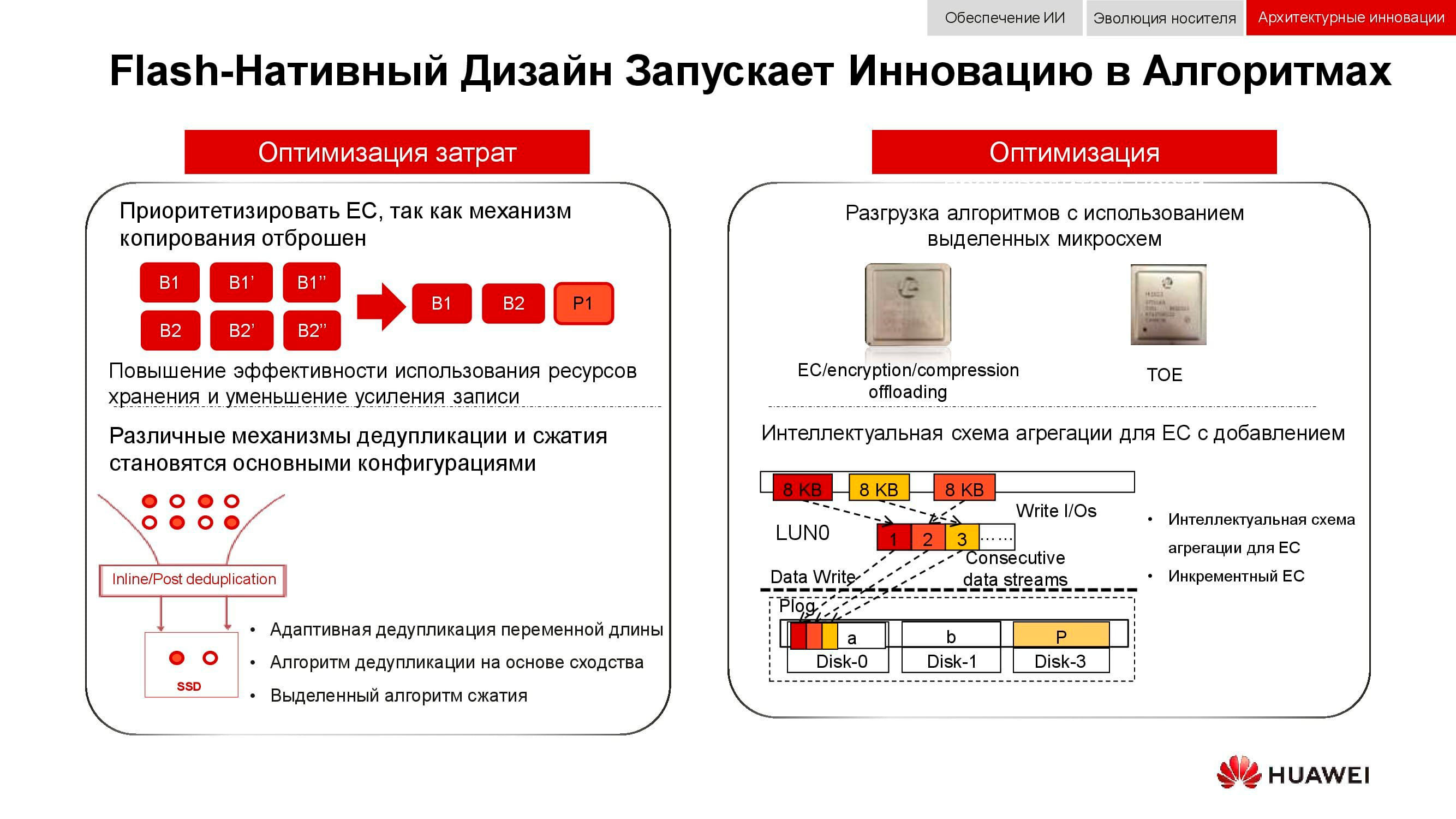
An additional way to optimize the work of distributed storage is a complete rejection of data mirroring. Huawei solutions no longer use n copies, as in the usual RAID 1, and completely switch to the EC mechanism(Erasure coding). A special mathematical package with a certain frequency calculates control blocks that allow you to restore intermediate data in case of loss.
Deduplication and compression mechanisms are becoming mandatory. If in classical storage systems we are limited by the number of processors installed in controllers, then in distributed scale-out storage systems each node contains everything you need: disks, memory, processors and interconnect. These resources are sufficient for deduplication and compression to have minimal performance impact.
And about hardware optimization methods. Here, it was possible to reduce the load on the central processors with the help of additional dedicated microcircuits (or dedicated blocks in the processor itself), which play the role of TOE(TCP / IP Offload Engine) or taking over the math problems of EC, deduplication and compression.
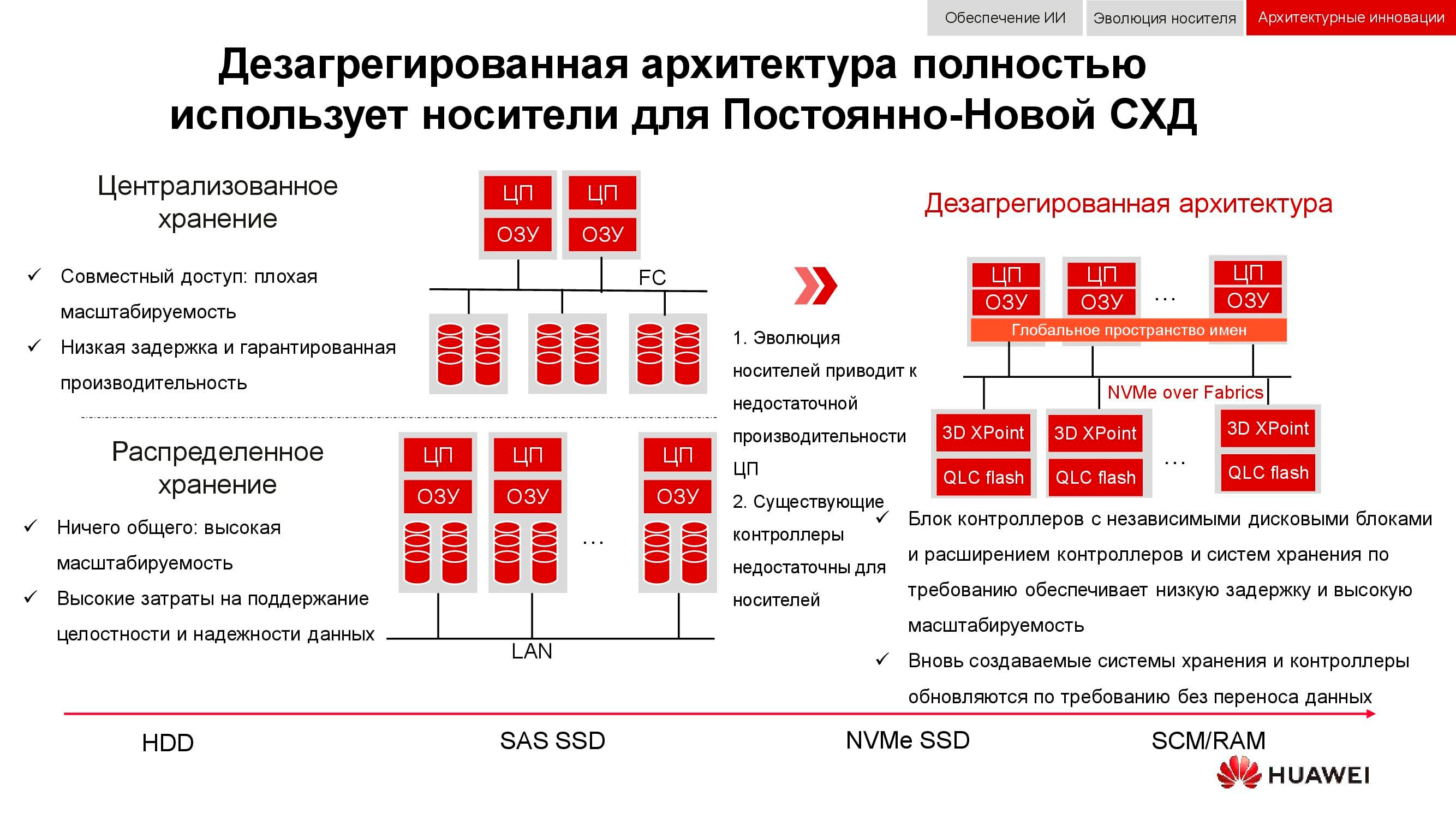
New approaches to data storage are embodied in a disaggregated (distributed) architecture. In centralized storage systems, there is a server factory that is connected via Fiber Channel to a SAN with a large number of arrays. The disadvantages of this approach are the difficulty in scaling and providing guaranteed service levels (performance or latency). Hyper-converged systems use the same hosts for both storing and processing information. This provides virtually unlimited scalability, but entails high costs for maintaining data integrity.
In contrast to both of the above, disaggregated architecture implies the separation of the system into a compute fabric and a horizontal storage system . This provides the benefits of both architectures and allows you to scale almost indefinitely only to the element that lacks performance.
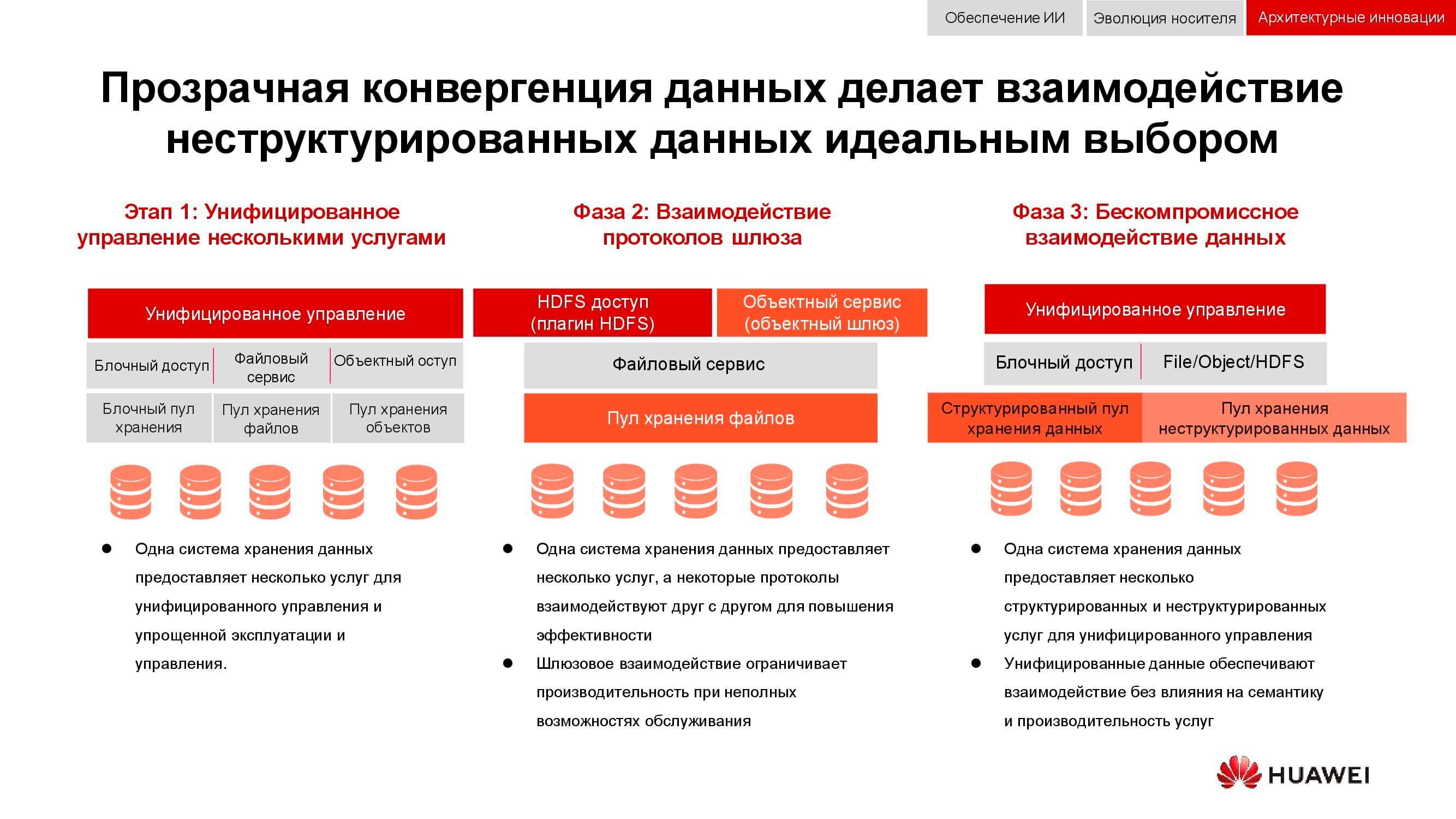
From integration to convergence
A classic task, the relevance of which has only grown over the past 15 years, is the need to simultaneously provide block storage, file access, access to objects, farm operation for big data, etc. The cherry on the cake can also be, for example, a backup system to magnetic tape.
At the first stage, it was only possible to unify the management of these services. Heterogeneous data storage systems were locked into some specialized software, through which the administrator allocated resources from the available pools. But since these pools were different in hardware, migration of the load between them was impossible. At a higher level of integration, the consolidation took place at the gateway level. If there was a shared file access, it could be given through different protocols.
The most advanced convergence method available to us now involves the creation of a universal hybrid system. Exactly what our OceanStor 100D should be . Accessibility uses the same hardware resources, logically divided into different pools, but allowing for workload migration. All this can be done through a single management console. In this way, we managed to implement the concept of “one data center - one storage system”.
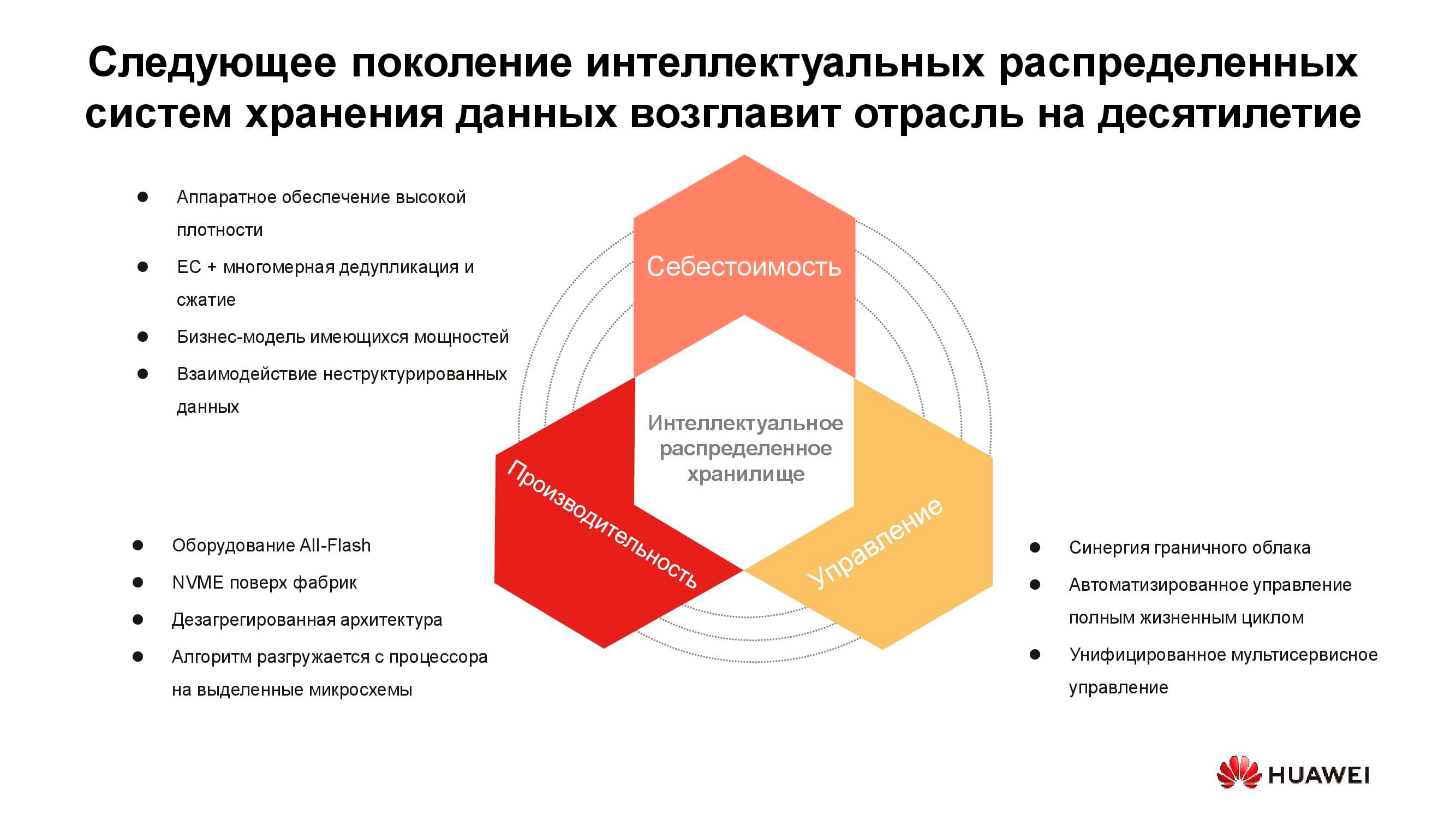
The cost of storing information now determines many architectural decisions. Although it can be safely put at the forefront, we are discussing live storage with active access today, so performance must also be considered. Another important property of next generation distributed systems is unification. After all, no one wants to have several disparate systems controlled from different consoles. All these qualities are embodied in the new series of Huawei OceanStor Pacific products .
Mass storage of a new generation
OceanStor Pacific meets the requirements of reliability at the level of "six nines" (99.9999%) and can be used to create data centers of the HyperMetro class. With a distance of up to 100 km between two data centers, the systems demonstrate an additional delay of 2 ms, which makes it possible to build on their basis any disaster-resistant solutions, including those with quorum servers.
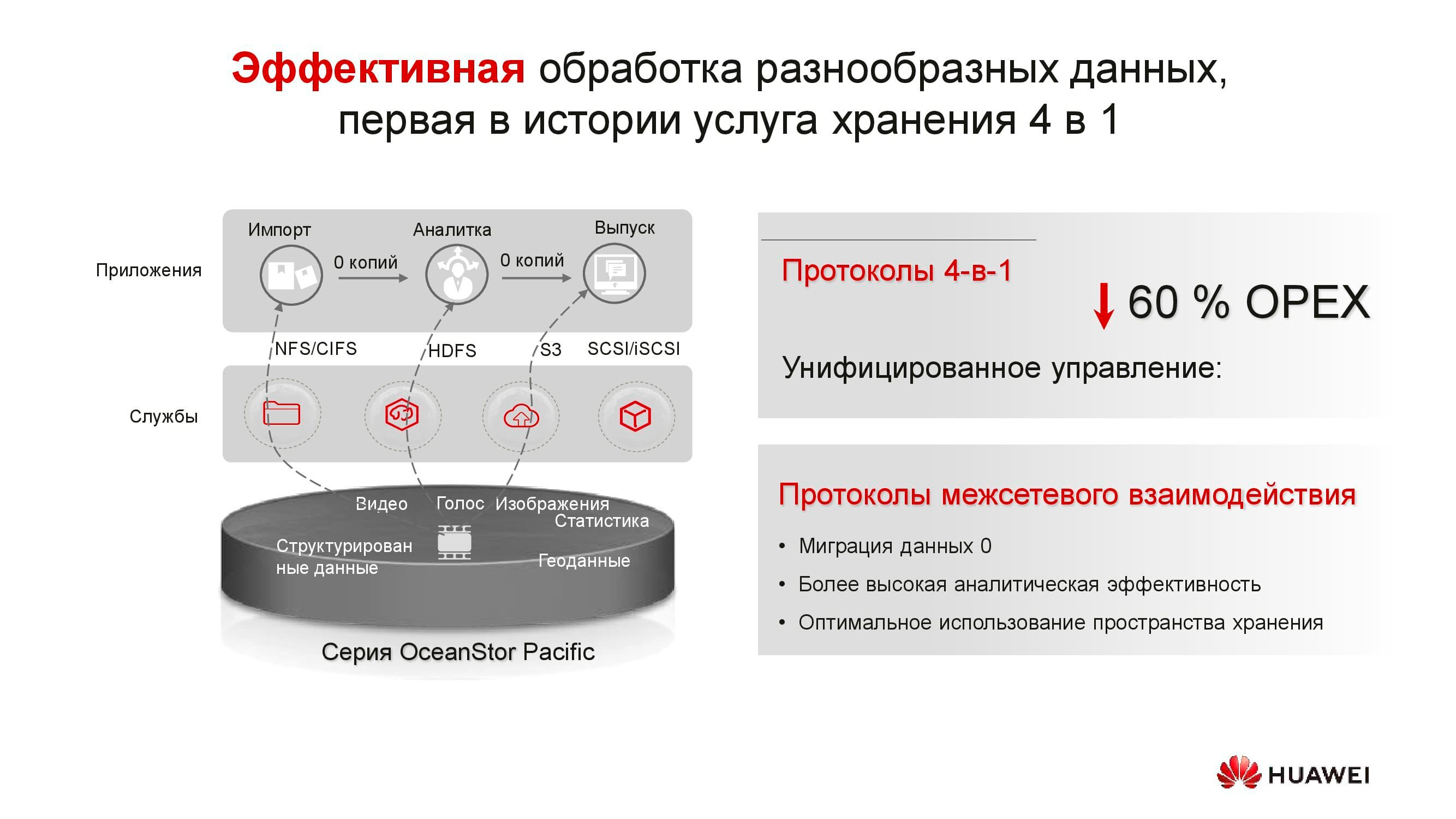
The products in the new series demonstrate protocol versatility. OceanStor 100D already supports block access, object access, and Hadoop access. File access will also be implemented in the near future. There is no need to keep multiple copies of the data if they can be delivered through different protocols.
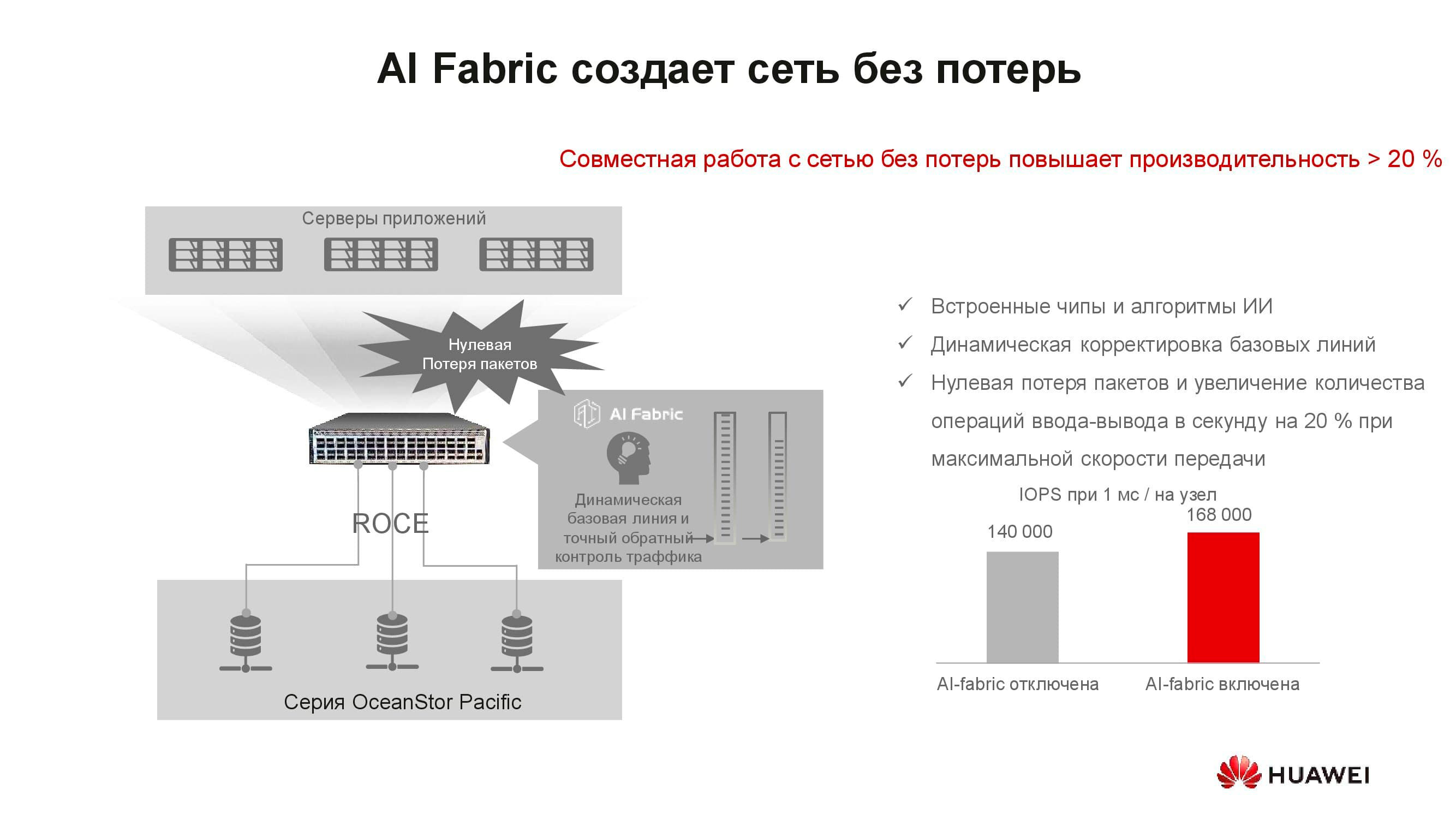
It would seem, what does the concept of a "lossless network" have to do with storage? The fact is that distributed storage systems are built on the basis of a fast network that supports the appropriate algorithms and the RoCE mechanism. The AI Fabric supported by our switches helps to further increase network speed and reduce latency . Storage performance gains with AI Fabric activation can be up to 20%.
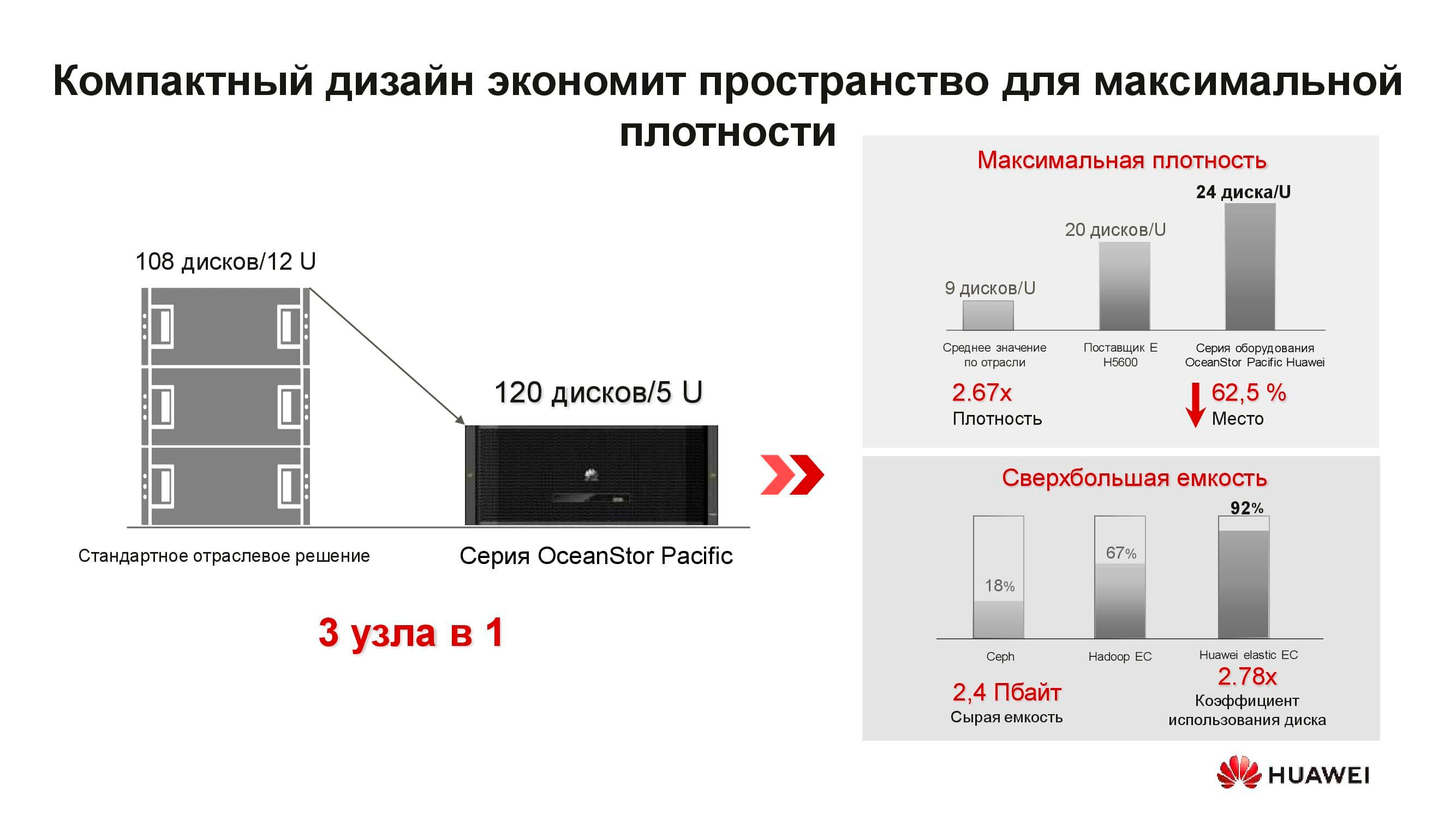
What is the new OceanStor Pacific distributed storage node? The 5U solution includes 120 drives and can replace three classic nodes, which saves more than 2 times rack space. Due to the refusal to store copies, the efficiency of drives significantly increases (up to + 92%).
We are used to the fact that SDS is special software installed on a classic server. But now, to achieve optimal parameters, this architectural solution also requires special nodes. It consists of two servers based on ARM-processors, managing an array of 3-inch drives.
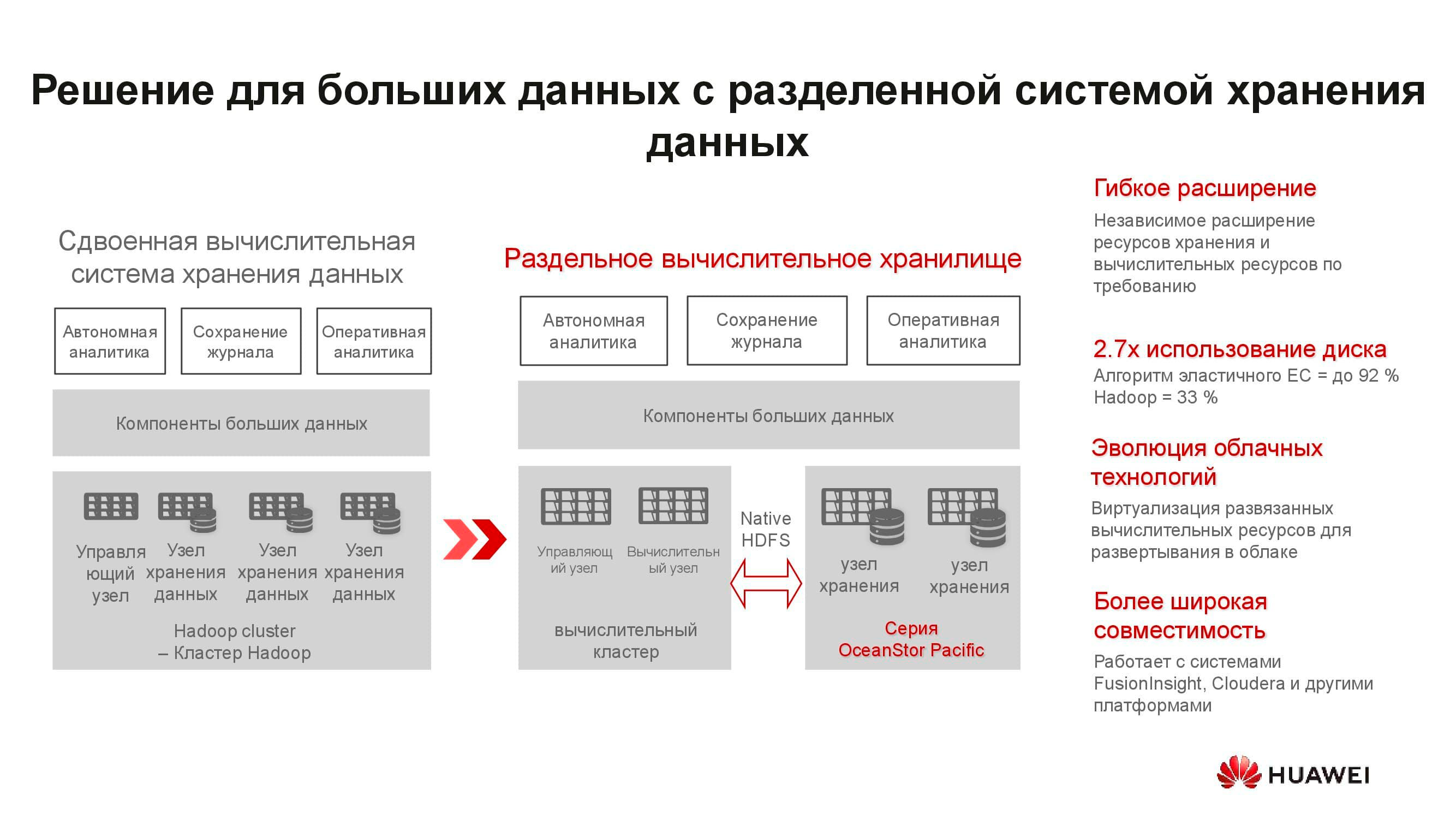
These servers are poorly suited for hyper-converged solutions. Firstly, there are few applications for ARM, and secondly, it is difficult to maintain load balance. We propose to move to separate storage: a computational cluster, represented by classic or rack servers, operates separately, but connects to OceanStor Pacific storage nodes, which also perform their direct tasks. And it justifies itself.
For example, take a classic hyperconverged big data storage solution that takes up 15 server racks. By separating the load between the individual compute servers and OceanStor Pacific storage nodes, separating them from each other, the number of required racks is cut in half! This reduces the cost of operating the data center and reduces the total cost of ownership. In a world where the volume of stored information is growing by 30% per year, such advantages are not scattered around.
***
You can get more information about Huawei solutions and scenarios for their use on our website or by contacting the company representatives directly.