We continue a series of articles about content moderation at the sites of the Financial Technologies Development Center of the Russian Agricultural Bank. In the last article, we talked about how we solved the problem of text moderation for one of the sites of the ecosystem for farmers "Own Farming" . You can read a little about the site itself and what result we got here .
In short, we used an ensemble of a naive classifier (filter by dictionary) and BERT. The texts that passed the dictionary filter were allowed to enter the BERT, where they were also checked.
And we, together with the MIPT Laboratory, continue to improve our site, setting ourselves a more difficult task of pre-moderation of graphic information. This task turned out to be more difficult than the previous one, since when processing a natural language, one can do without using neural network models. With images, everything is more complicated - most tasks are solved using neural networks and the selection of their correct architecture. But with this task, as it seems to us, we have coped well! And what we got from this, read on.

What we want?
So let's go! Let's immediately define what an image moderation tool should be. By analogy with a text moderation tool, this should be a kind of "black box". By submitting an image uploaded to the site by sellers of goods as input, we would like to understand how this image is acceptable for publication on the site. Thus, we get the task: to determine whether the image is suitable for publication on the site or not.
The task of pre-moderation of images is common, but the solution often differs from site to site. Thus, images of internal organs may be acceptable for medical forums, but not suitable for social networks. Or, for example, images of cut animal carcasses are acceptable on a website where they are sold, but they are unlikely to be liked by children who go online to watch Smesharikov. As for our site, images of agricultural products (vegetables / fruits, animal feed, fertilizers, etc.) would be acceptable for it. On the other hand, it is obvious that the theme of our marketplace does not imply the presence of images with various obscene or offensive content.
To begin with, we decided to get acquainted with the already known solutions to the problem and try to adapt them to our site. As a rule, many tasks of graphical content moderation are reduced to solving problems of the NSFW class , for which there is a dataset in the public domain.
To solve NSFW tasks, as a rule, classifiers based on ResNet are used, which show quality accuracy> 93%.
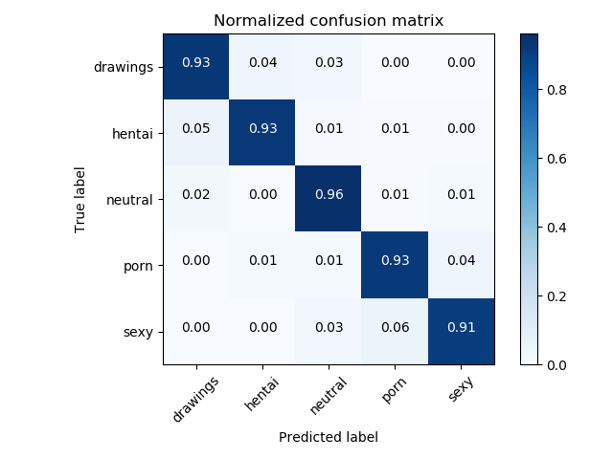
Error matrix of the original NSFW classifier
Ok, let's say we have a good model and a ready-made dataset for NSFW, but will this be enough to determine the acceptability of the image for the site? It turned out not. After discussing this initial approach with the NSFW model with the owners of our site, we realized that it is necessary to define a little more categories, namely:
- ( , )
- ( , , , . )
- ( )
That is, we still had to compose our own dataset and think about what other models could be useful.
This is where we run into a common machine learning problem: lack of data. It is due to the fact that our site was created not so long ago, and there are no negative examples on it, that is, marked as unacceptable. To solve it, the few-shot learning method comes to our aid . The essence of this method is that we can retrain, for example, ResNet on small datasets we assembled, and get an accuracy higher than if we made a classifier from scratch and only using our small dataset.
How did you do it?
Below is a general scheme of our solution, starting from the input image and ending with the result of detecting various categories, if an apple image is fed to the input.

General scheme of the solution
Let's consider each part of the scheme in more detail.
Stage 1: Graffiti detector
We expect that goods with text on packages will be loaded onto our site and, accordingly, the task of detecting inscriptions and identifying their meaning arises.
At the first stage, we used the OpenCV Text Detection library to find the labels on the packages.
OpenCV Text Detection is an optical character recognition (OCR) tool for Python. That is, it recognizes and "reads" text embedded in images.

Example of EAST detector operation
You can see an example of detection of inscriptions in the photo. To identify the bounding box, we used the EAST model, but here the reader may feel a catch, since this model is trained to recognize English texts, and on our images the texts are in Russian. That is why, further, we use a binary classification model (graffiti / not graffiti) based on ResNet, which has been trained to the required quality on our data. We took ResNet-18, as this model proved to be the best when choosing an architecture.
In our task, we would like to distinguish a photo where the inscriptions are inscriptions on the packaging of goods from graffiti. Therefore, we decided to divide all photos with text into two classes: graffiti and non-graffiti.The
obtained model accuracy was 95% on a pre-deferred sample:
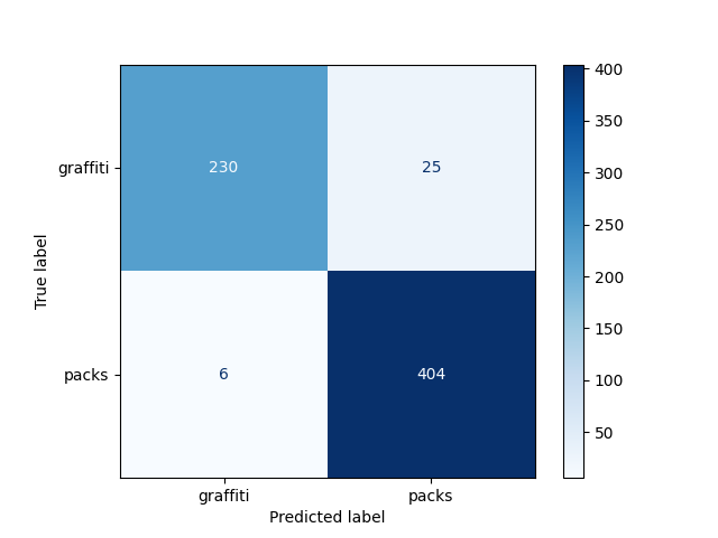
Graffiti Detector Bug Matrix
Not bad! Now we are able to isolate the text in the photo and with a good probability understand whether it is suitable for publication. But what if there is no text in the photo?
Stage 2: NSFW detector
If we do not find text in the picture, this does not mean that it is unacceptable, therefore, next we want to evaluate how the content on the image corresponds to the theme of the site.
At this stage, the task is to assign the image to one of the categories:
- drugs
- porn (porn)
- animals
- photos that can cause rejection (including drawings) (gore / drawing_gore)
- hentai (hentai)
- neutral images (neutral)
It is important that the model returns not only the category, but also the degree of confidence of the algorithms in it.
An NSFW-based model was used for classification. She is trained in such a way that she divides the photo into 7 classes and only one of them we expect to see on the site. Therefore, we only leave neutral photos.
The result of such a model is 97% (in terms of accuracy)

NSFW detector error matrix
Stage 3: Person detector
But even after we have learned how to filter NSFW, the problem still cannot be considered solved. For example, a photo of a person does not fall into either the NSFW category or the photo with text category, but we would not like to see such images on the site either. Then we added to our architecture a model of human detection - Single Shot Detector (hereinafter referred to as SSD).
Selecting people or some other previously known object is also a popular task with a wide range of applications. We used the ready-made nvidia_ssd model from pytorch.

An example of the SSD algorithm
The results of the model are lower (accuracy - 96%):

Human detector error matrix
results
We assessed the quality of our instrument using weighted F1, Precision, Recall metrics. The results are presented in the table:
| Metrics | Accuracy obtained |
| Weighted F1 | 0.96 |
| Weighted Precision | 0.96 |
| Weighted Recall | 0.96 |
And here are some more illustrative examples of its work:
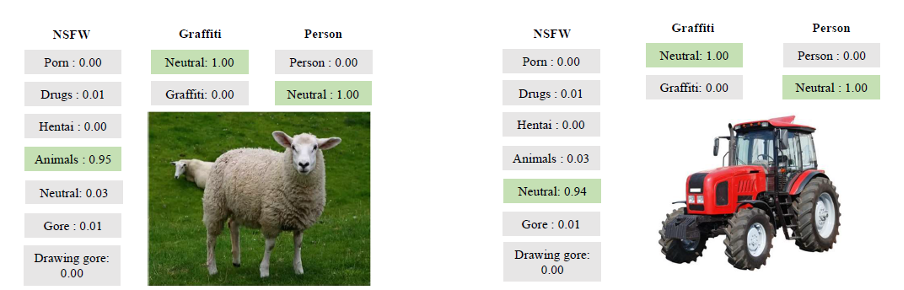
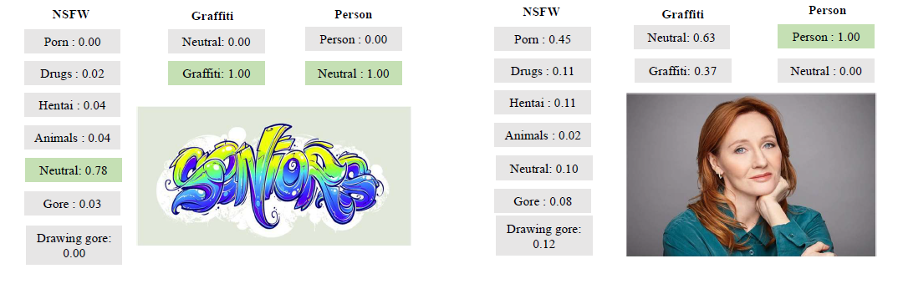
Examples of the tool
Conclusion
In the process of solving, we used a whole "zoo" of models that are often used for computer vision tasks. We learned to “read” text from a photo, find people, and distinguish inappropriate content.
Finally, I would like to note that the considered problem is useful from the point of view of gaining experience and using modified classical models. Here are some of the insights we got:
- You can work around the data shortage problem using the few-shot learning method: large models can be trained to the required accuracy on their own data
- : ,
- , ,
- , , . , , ,
- Despite the fact that the task of image moderation is quite popular, its solution, as in the case of texts, may differ from site to site, since each of them is designed for a different audience. In our case, for example, we, in addition to inappropriate content, also detected animals and people
Thank you for your attention and see you in the next article!