I decided to build the multisession from audio recordings accumulated over one calendar month in order to avoid unnecessary clutter for Adobe Audition. Of course, such a session can be built manually, but it is a long and painstaking work. The main interest of this task is to automate the construction of a multisession by software. More precisely, write a program that, based on a list of audio recording files, will generate an SES file for an Adobe Audition multisession. For those who do not know: a multisession, in short, is a project consisting of many different audio recordings distributed in time and over tracks (tracks) and designed to create a mix of them.
First of all, it is worth discussing how I get the audio recordings of telephone conversations. It's no secret that modern smartphones have the ability to record phone calls with various tools, both built into the system and third-party ones. Personally, I use a Lenovo TAB3 tablet (MT8735P processor). The device allows you to make audio recordings in manual mode in a compressed format, receiving files with the 3gpp extension. The recordings are obtained in stereo with separated channels: in one channel, the subscriber's voice is recorded, and in the other - his own voice. The compressed format of audio recordings affects their distortion during playback. Because of this, I use third-party audio recording applications, of which there are countless. One of the apps that I liked the most is “Record My Call”.This application records calls in automatic mode, has many settings related, in particular, to the choice of the format and quality of audio recording. And also, as a bonus, the application has a nice very convenient built-in call log, which is saved to the db database file (Fig. 1).
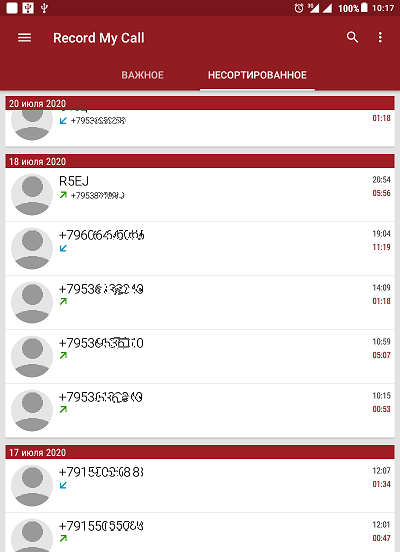
Figure: 1. Call log in the "Record My Call" application.
The best audio recording parameters for sound quality are WAV 8000Hz 16bit Stereo. With such settings, the recording has no distortions, sounds clear, although it takes up more memory space. The application is configured in such a way that the audio recording starts automatically even before the start of the telephone conversation: when an incoming call arrives before “picking up the receiver” or when dialing a number during ringing. That is, missed and unanswered calls are also recorded. Can be configured to record only the conversation. The audio recording file name format is also configurable. In my case, I configured it as shown in Figure 2.
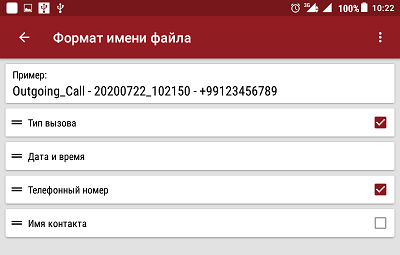
Fig. 2. Setting the file name format in “Record My Call”.
During the development of the multisession generation program, it will be necessary to take information about the date and time of the audio recording of the telephone call. This information will be taken from the file name at fixed positions.
Before you start creating a multisession SES file, you need to understand how such a file works. Of course, there is no documentation on this format anywhere, so I had to solve it on my own, relying on personal experience and knowledge. This file is not a text file, so there is little point in opening it in Notepad. "WinHex" - a hexadecimal editor comes to the rescue. I have already written a number of articles on working with binary data and decrypting information, in particular, an article on writing a 264-avi video repackaging program. There I wrote more or less in detail about the device of the avi file.
First, I created a simple arbitrary multisession in Adobe Audition 1.5, consisting of one track and one audio file (Fig. 3), saving it to a file with the ses extension. The file is 2422 bytes in size. Then I opened this file in WinHex (Fig. 4).
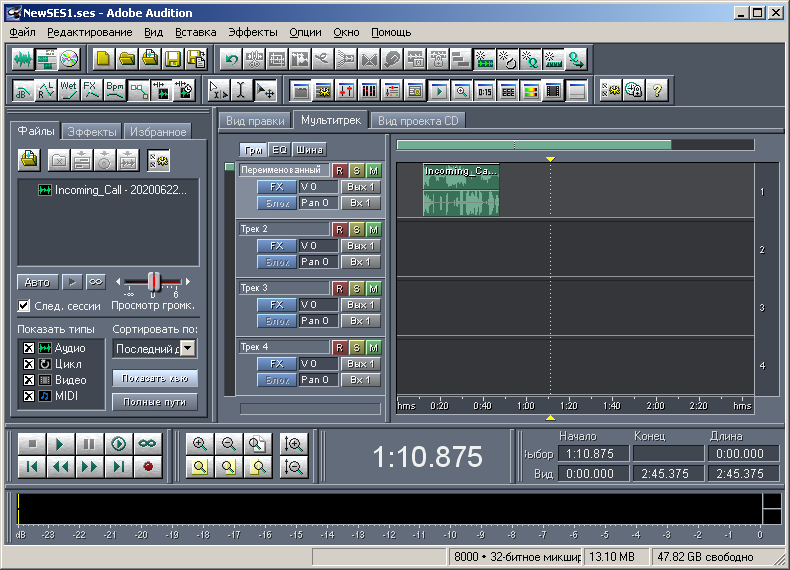
Figure: 3. View of multisession in Adobe Audition 1.5 - Example 1.
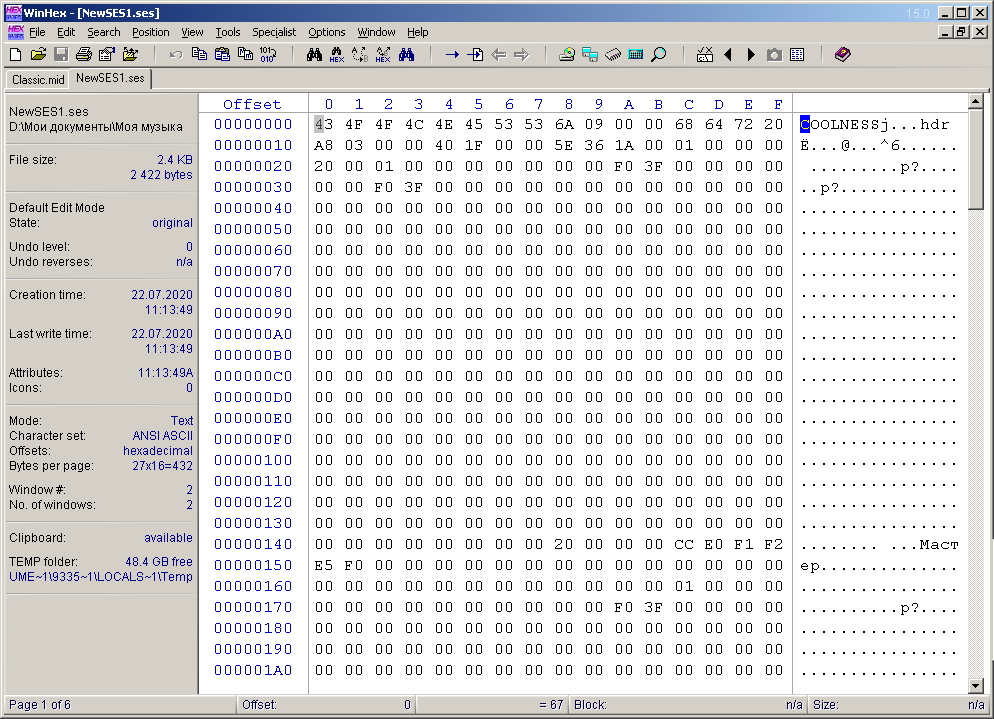
Fig. 4. Multisession file opened in WinHex.
At first glance, nothing is clear at all. In the symbolic part of the window, you can see the semantic words "COOLNESS", "hdr", "Master". If you scroll through the document below, you can see the text containing the full path to the file (and, in two versions), which is used in the multisession. This is shown in Figure 5 and circled in green. Immediately striking are short semantic words circled in a red frame in the same figure.
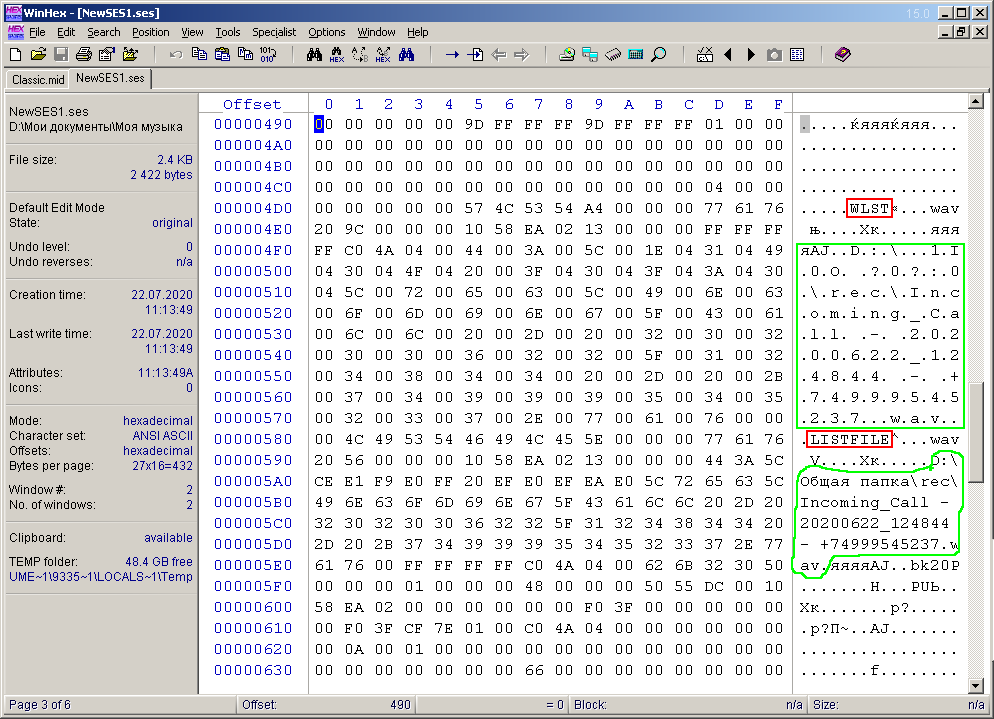
Figure: 5. Bytes of paths to multisession audio files.
Looking more closely this document from beginning to end, I noticed a few other short semantic words. I also noticed that the length of any meaningful word is a multiple of four. Apparently, these words are the headers of the blocks that make up the entire multisession file. It reminded me of the RIFF structure of an avi or wav file consisting of blocks that also have headers of the same size. These headers were followed by a 32-bit number (4 bytes) indicating the size of the current block. With this fact in mind, I decided to check if this principle works for the ses file? It turned out that in the case of the ses format, this also works (fig. 6).
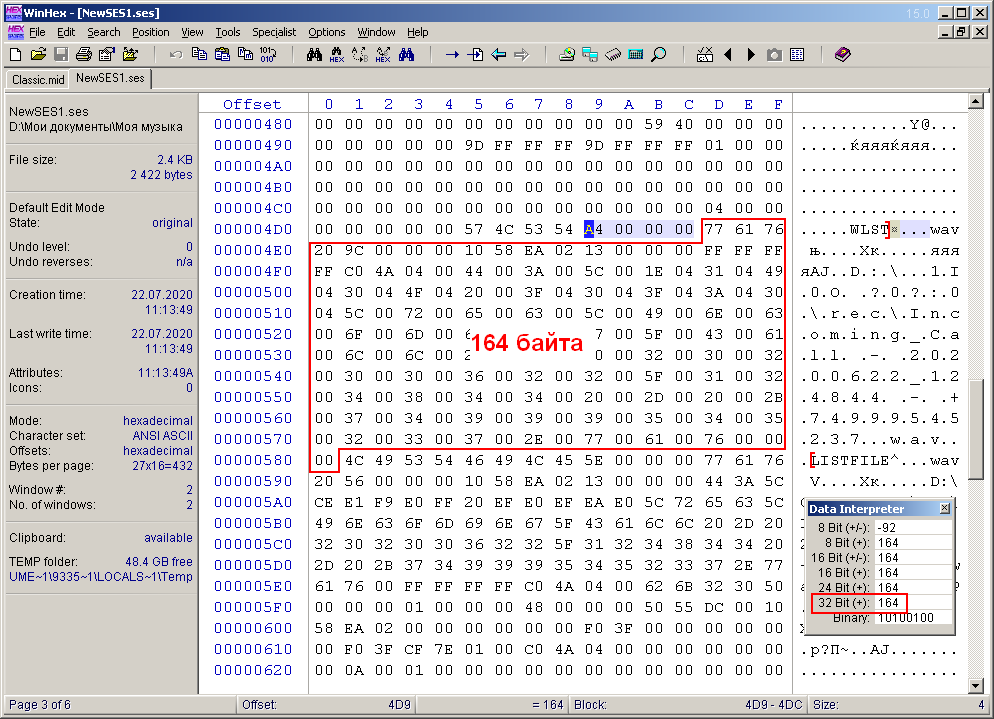
Figure: 6. Similarity to the RIFF structure (for example, the "WLST" block).
The first word "COOLNESS" in the ses file seems to be the main header and the type of this file. The next 4 bytes are the size of the content, which is placed next, up to the end of the file. That is, if you carefully calculate, this value is 12 bytes less than the size of the entire file. And further content consists of a collection of different blocks. A block has a header of four or eight bytes, followed by 4 bytes indicating the size of this block, and after them the contents of this block follow. In some blocks, I identified the presence of subblocks, but this will be discussed in the course of a more detailed description of each block. In this file, which in the example, I counted 17 blocks, they are listed in the table in Figure 7.
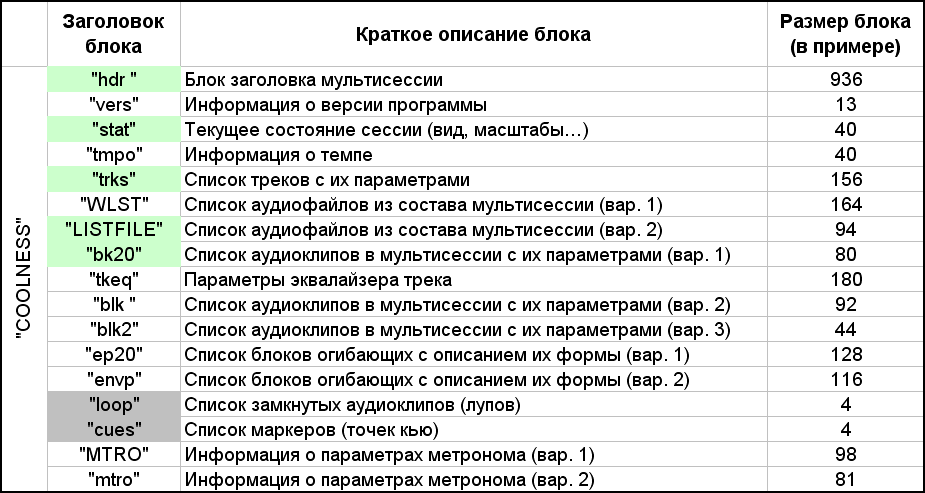
Fig. 7. List of blocks that make up the multisession.
As you can see from the table, some of the same information is presented in different versions by different blocks. This is probably done for the compatibility of different versions of the program. Looking ahead, those blocks are highlighted in green, without which the multisession presented in the example cannot exist. Two 4-byte blocks are highlighted in gray, which are fictitious in this session. Indeed, I had a question: what will happen if you delete some of the blocks from the file? After all, I, for example, do not need information about the metronome and tempo, and the envelopes on clips (more precisely, on one clip) are missing in my simple example. Envelopes are curves on top of an audio clip that set the dynamics of sound parameters (volume, balance) over time. I sequentially started cutting blocks from the given file,not forgetting to recalculate and correct the value after the word "COOLNESS". As a result, the multisession was successfully opened with at least five blocks highlighted in green. The session contains two blocks of the list of audio files. Any of them could be left. I prefer the second option (the "LISTFILE" block), since in the first option (the "WLST" block) there are two bytes per character in the file path description. This may have been done for the extended character alphabet, but the standard ASCII alphabet is enough for me. Moreover, Russian characters, as you can see, are well supported. Description of audio clips is presented in three versions. I chose the first option (block "bk20"), because I figured out its description the fastest.The session contains two blocks of the list of audio files. Any of them could be left. I prefer the second option (the "LISTFILE" block), since in the first option (the "WLST" block) there are two bytes per character in the file path description. This may have been done for the extended character alphabet, but the standard ASCII alphabet is enough for me. Moreover, Russian characters, as you can see, are well supported. Descriptions of audio clips are presented in three versions. I chose the first option (block "bk20"), because I figured out its description the fastest.The session contains two blocks of the list of audio files. Any of them could be left. I prefer the second option (the "LISTFILE" block), since in the first option (the "WLST" block) there are two bytes per character in the file path description. This may have been done for the extended character alphabet, but the standard ASCII alphabet is enough for me. Moreover, Russian characters, as you can see, are well supported. Descriptions of audio clips are presented in three versions. I chose the first option (block "bk20"), because I figured out its description the fastest.but the standard ASCII alphabet is enough for me. Moreover, Russian characters, as you can see, are well supported. Description of audio clips is presented in three versions. I chose the first option (block "bk20"), because I figured out its description the fastest.but the standard ASCII alphabet is enough for me. Moreover, Russian characters, as you can see, are well supported. Description of audio clips is presented in three versions. I chose the first option (block "bk20"), because I figured out its description the fastest.
A multisession from audio recordings of telephone conversations will be similar in complexity to the multisession presented in this example. The only difference is that it will be more voluminous: the number of audio files will be quite large, and the number of tracks will be equal to the number of days in a month. For such a multisession, no other "bells and whistles" are needed. The block sizes "hdr" and "stat" are static and are always 936 and 40 bytes, respectively, regardless of the size of the multisession. The sizes of the "trks" and "bk20" blocks depend on the number of tracks and audio clips in the multisession, respectively. But the size of the "LISTFILE" block is the most unpredictable: it depends not only on the number of audio files in the multisession, but also on the length of their names and their location paths.
Deciphering and composing a complete description of the blocks of a multisession file is a rather time-consuming task. Therefore, I partially decoded the information, paying attention only to those byte sections that must be taken into account when forming a multisession of simplified content. In this article, I will provide a description of the contents of each block, which I was able to decipher.
In the content of the multisession header block "hdr" (there is just a space at the end), the key bytes are the first 12 bytes, that is, 3 words of 4 bytes each (Fig. 8). The first word is the sampling rate of the samples in the multisession. For my multisession, this value is 8000 Hz (0x1F40). In Figure 8 it is highlighted with green fill. Let me remind you that bytes in words for numeric values are read backwards. The second word is the duration (length) of the multisession, expressed in the number of samples (orange fill in the figure). In this example, this value is 0x1A365E (1717854). If translated into minutes, you get 1717854/8000/60, which is approximately three and a half minutes. And so it is: on a minimal scale, a multisession has exactly this duration.And for a multisession from phone call records, the duration should be 24 * 3600 * 8000 = 691200000 = 0x2932E000 samples. In this situation, by the way, the current playback time of the multisession on the panel below, which is a relative time, will exactly coincide with the value of the absolute time of the current phone call (or a group of calls by day). The next word highlighted in yellow indicates the number of audio clips in the multisession. In the example, this value equals one, but in the case of phone calls, the number of such clips will be equal to the number of audio files. Looking ahead, the last statement is not entirely correct. In fact, the number of audio clips may be slightly more than the number of audio files. One file can have two clips in the event thatif a new day has come during a telephone conversation. In this case, you will have to "transfer" the recording to a new track, and one clip will not work. But such cases are rare in practice, since the transition to a new day occurs at night, when the activity of telephone calls is minimal. By the way, I did not take this point into account when forming the SVG diagram in the previous article. After the word of the value of the number of blocks follows, most likely, a "half word" of two bytes 0x0020, or 32 in decimal form. It could also be highlighted with a color fill, since, most likely, it means the bit depth of the mixing. In Adobe Audition, the status bar at the bottom says: 8000 Hz, 32-bit mixing. In addition to the three most essential words of the "hdr" content, there are other obscure bytes. For example, I don't even know the word "Master"what it refers to. Apparently this is the name of the main mixing bus. But the most interesting groups of bytes I circled in a gray frame. The fact is that this sequence is often found in other blocks of the multisession file. It is not by chance that I have combined exactly 8 bytes into a group, since, most likely, this is a real data type. In particular, this constant "00 00 00 00 00 00 F0 3F" HEX by the editor in the Double type is interpreted as 1.0e + 0, that is, as a unit. Most likely these are the values of loudness levels and other "twists", but specified not in decibels, but in the form of a coefficient. I must say right away that all bytes of any block that I could not recognize (or was not necessary) will be written to the generated multisession file without changes, as in the example.But the most interesting groups of bytes I circled in a gray frame. The fact is that this sequence is often found in other blocks of the multisession file. It is not by chance that I have combined exactly 8 bytes into a group, since, most likely, this is a real data type. In particular, this constant "00 00 00 00 00 00 F0 3F" HEX by the editor in the Double type is interpreted as 1.0e + 0, that is, as a unit. Most likely these are the values of loudness levels and other "twists", but specified not in decibels, but in the form of a coefficient. I must say right away that all bytes of any block that I could not recognize (or was not necessary) will be written to the generated multisession file without changes, as in the example.But the most interesting groups of bytes I circled in a gray frame. The fact is that this sequence is often found in other blocks of the multisession file. It is not by chance that I have combined exactly 8 bytes into a group, since, most likely, this is a real data type. In particular, this constant "00 00 00 00 00 00 F0 3F" HEX by the editor in the Double type is interpreted as 1.0e + 0, that is, as a unit. Most likely these are the values of loudness levels and other "twists", but specified not in decibels, but in the form of a coefficient. I must say right away that all bytes of any block that I could not recognize (or was not necessary) will be written to the generated multisession file without changes, as in the example.It is not by chance that I have combined exactly 8 bytes into a group, since, most likely, this is a real data type. In particular, this constant "00 00 00 00 00 00 F0 3F" HEX by the editor in the Double type is interpreted as 1.0e + 0, that is, as a unit. Most likely these are the values of loudness levels and other "twists", but specified not in decibels, but in the form of a coefficient. I must say right away that all bytes of any block that I could not recognize (or was not necessary) will be written to the generated multisession file without changes, as in the example.It is not by chance that I have combined exactly 8 bytes into a group, since, most likely, this is a real data type. In particular, this constant "00 00 00 00 00 00 F0 3F" HEX by the editor in the Double type is interpreted as 1.0e + 0, that is, as a unit. Most likely these are the values of loudness levels and other "twists", but specified not in decibels, but in the form of a coefficient. I must say right away that all bytes of any block that I could not recognize (or was not necessary) will be written to the generated multisession file without changes, as in the example.and as a coefficient. I must say right away that all bytes of any block that I could not recognize (or was not necessary) will be written to the generated multisession file without changes, as in the example.and as a coefficient. I must say right away that all bytes of any block that I could not recognize (or was not necessary) will be written to the generated multisession file without changes, as in the example.
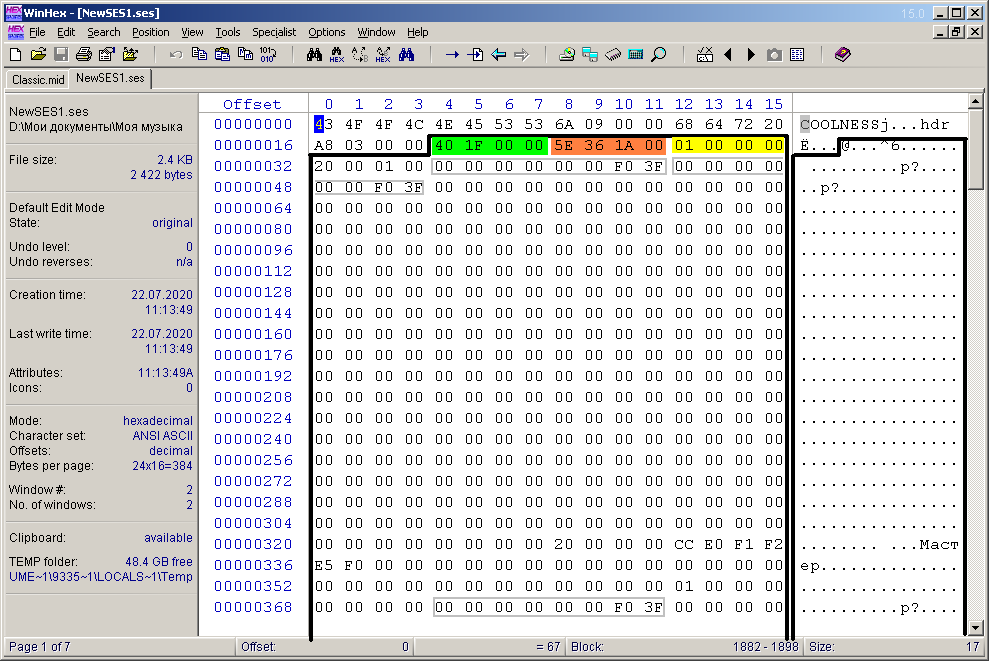
. 8. «hdr ».
I decided not to study the "stat" block of the current multisession state (the shortest). I created another sample multisession from one audio file, stretched it for 24 hours duration and made its full view (scale) horizontally. And vertically, the view of the tracks was scaled so that when the Adobe Audition window was expanded, 31 tracks would fit on the FullHD screen. This is the maximum number of days in one month. The multisession cursor was positioned at the very beginning. Then I saved this multisession to another file, and then pulled out the "stat" block with all its headers. I saved these bytes in the file "stat_31_full.BLK" for further use in developing the program. The view of the content of such a file is shown in Figure 9. The size of this file was 48 bytes (40 bytes of the block content + 4 bytes of the header + 4 bytes of the description of the size of the content).
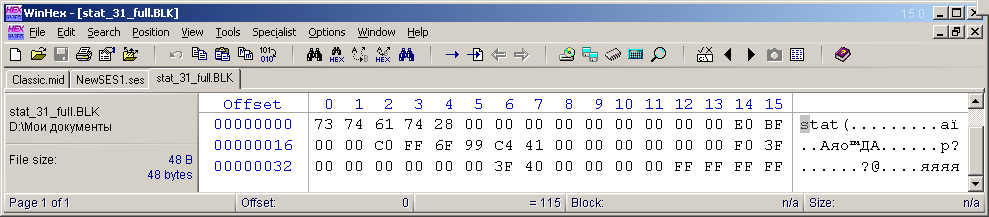
. 9. «stat» .
For a more visual description of the next three blocks in the course of writing this article, I decided to create a more complex multisession, consisting of two tracks, two files and three clips (Fig. 10). The first file "Incoming_Call - 20200622_124844 - + 74999545237.wav" has a duration of 281280 samples. The second file "Outgoing_Call - 20200621_231753 - + 79536170218.wav" has a duration of 63360 samples. The first track named "First" (renamed) contains two clips. The first clip is shifted from the beginning of the session by 10 seconds (by 80,000 samples). The clip is represented by the full contents of the first audio file, that is, the clip's duration is the same as the file's duration. The second clip is shifted by 50 seconds from the beginning of the session (by 50 * 8000 = 400000 samples). The clip is represented by the incomplete content of the second audio file. Within a given clip, audio starts from the beginning of the file,but only lasts 5 seconds (40,000 samples). That is, the clip length is 5 seconds. The second track named “Second” contains one clip. It is shifted from the beginning of the session by one second (by 8000 samples). This clip is represented by incomplete contents of the first audio file. Within this clip, audio does not start from the beginning, but after 3 seconds, but contains it to the very end. Thus, the offset of the audio data within this clip is 3 seconds (24,000 samples). And the length of a given clip is calculated as the difference between the duration of the corresponding audio and the offset of the audio data within the clip. In this case, the clip length is 281280-24000 = 257280 samples.This clip is represented by incomplete contents of the first audio file. Within this clip, audio does not start from the beginning, but after 3 seconds, but contains it to the very end. Thus, the offset of the audio data within this clip is 3 seconds (24,000 samples). And the length of a given clip is calculated as the difference between the duration of the corresponding audio and the offset of the audio data within the clip. In this case, the clip length is 281280-24000 = 257280 samples.This clip is represented by incomplete contents of the first audio file. Within this clip, audio does not start from the beginning, but after 3 seconds, but contains it to the very end. Thus, the offset of the audio data within this clip is 3 seconds (24,000 samples). And the length of a given clip is calculated as the difference between the duration of the corresponding audio and the offset of the audio data within the clip. In this case, the clip length is 281280-24000 = 257280 samples.In this case, the clip length is 281280-24000 = 257280 samples.In this case, the clip length is 281280-24000 = 257280 samples.
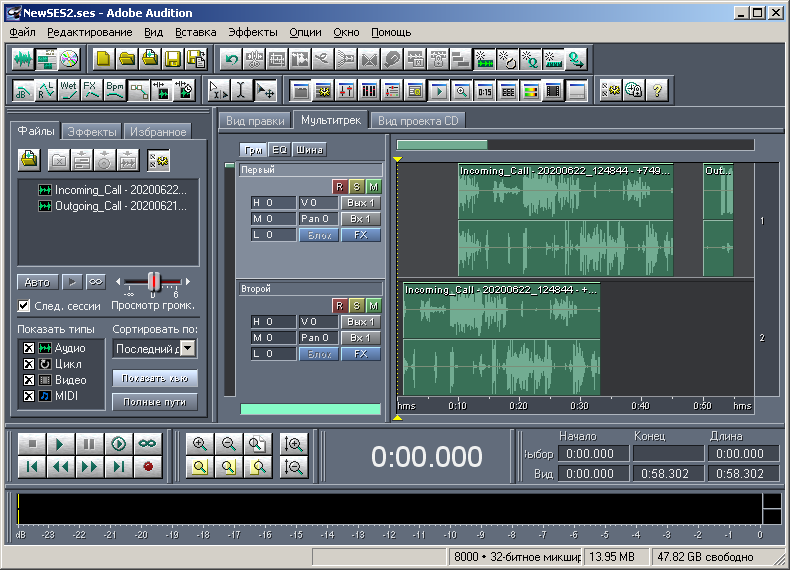
. 10. Adobe Audition 1.5 — 2.
Figure 11 shows the view of the contents of the "trks" track description block. The 4 bytes of the block header are highlighted in the red frame, and the size of the block contents is in the green one. This has already been discussed above. Next comes the contents of the block, the bytes of which are highlighted in the WinHex editor with a characteristic bluish fill. The size of the selection, the value of which is displayed in the lower right corner of the editor (also circled in green), coincides with the value from the bytes after the header and already in this example is 308 bytes. If in the first (previous) example from one track the block size was 156 bytes, and in the current one - 308 bytes, then the following conclusion can be drawn. Due to the assumption of the homogeneity and equivalence of tracks, the description areas of each track should have the same size. These areas, so to speak, are sub-blocks of the "trks" block.They are outlined in blue in the figure. It turned out that the size of one such subblock is 152 bytes. And at the very beginning of consecutive subblocks there is a subheading of four bytes, marked in the figure with a yellow fill. These four bytes are nothing more than the value of the number of tracks in a multisession, or the number of sub-blocks. And so, the size S of the contents of the "trks" block can be calculated by the formula S = 4 + 152 * n, where n is the number of tracks in the session. So it is: 4 + 152 * 1 = 156, and 4 + 152 * 2 = 308.the size S of the contents of the "trks" block can be calculated by the formula S = 4 + 152 * n, where n is the number of tracks in the session. So it is: 4 + 152 * 1 = 156, and 4 + 152 * 2 = 308.the size S of the contents of the "trks" block can be calculated by the formula S = 4 + 152 * n, where n is the number of tracks in the session. So it is: 4 + 152 * 1 = 156, and 4 + 152 * 2 = 308.
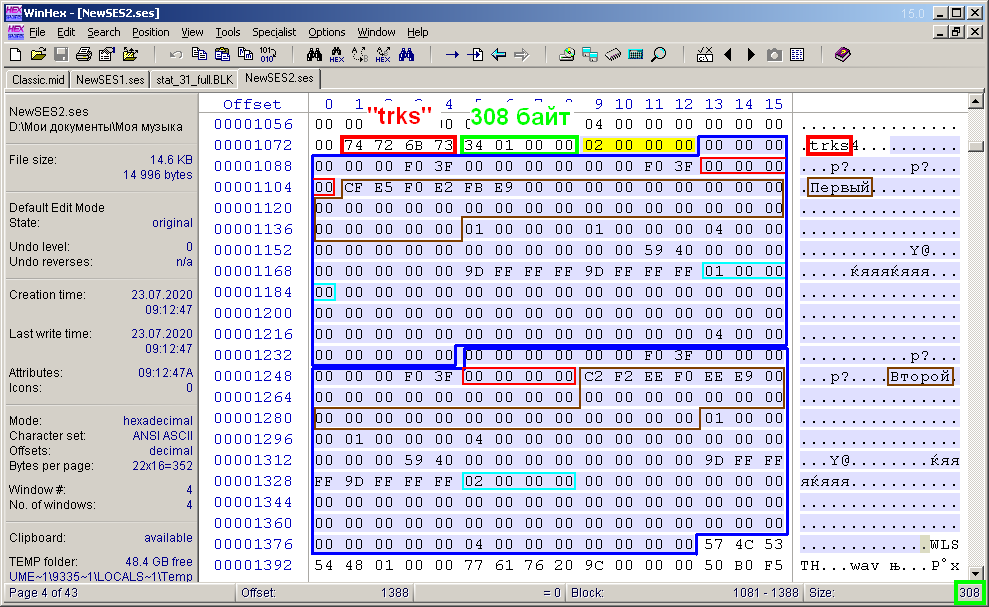
. 11. «trks».
Now let's move on to describing the contents of the subblock. There is a lot there, but I have deciphered only the most essential. There are just three parameters: 4 bytes of binary flags (circled in red), track name (circled in brown) and track ID (circled in blue). The track identifier is its sequence number. It is needed to indicate a link to a track in the description of audio clips (more on this later). The track name occupies an area of 36 bytes. This is the maximum number of characters in the track name, but it can be less, as in the current example. Unused bytes are zero. In a multisession with audio recordings of phone calls, the track names will match the recording of the corresponding dates. You can add the corresponding day of the week next to the date in two capital letters in abbreviated form.Four bytes of binary flags (32 flags in total) are intended to describe the binary parameters inherent in the track. In fact, there may be less than 32 of them. I decoded only part of the flags. Of these, at least three flags indicate whether the track is “R” (Record), “S” (Solo), or “M” (Mute). In the above example, none of these three buttons on the tracks are pressed, and the value of the binary flags is zero (0x00000000). But if you press the "R" button on the track (that is, put the track on record) and re-save the session, then the value of the binary flags will be 0x00000004, in other words, the third bit from the right (bit2) will become single. It is this bit that is responsible for the "record" property of the track. This property has no meaning in my project, since my multisession is designed for visual viewing and playback.However, I got the idea that the "R" button was pressed on those tracks that correspond to the weekend. This technique will make it easier to visualize the multisession.
The block of the list of audio files of the multisession "LISTFILE" (Fig. 12) consists of the following parts. As in the case with the track description block, it can also be divided into subblocks according to the number of files in the session. Similar to Figure 11, I've also highlighted the 8-byte block header in a red box and the size of its content in a green box. In this particular example, this value is 188 bytes. The content is highlighted by analogy with Fig. 11. It is divided into two areas highlighted with a blue line. These are the sub-blocks of the file list block.
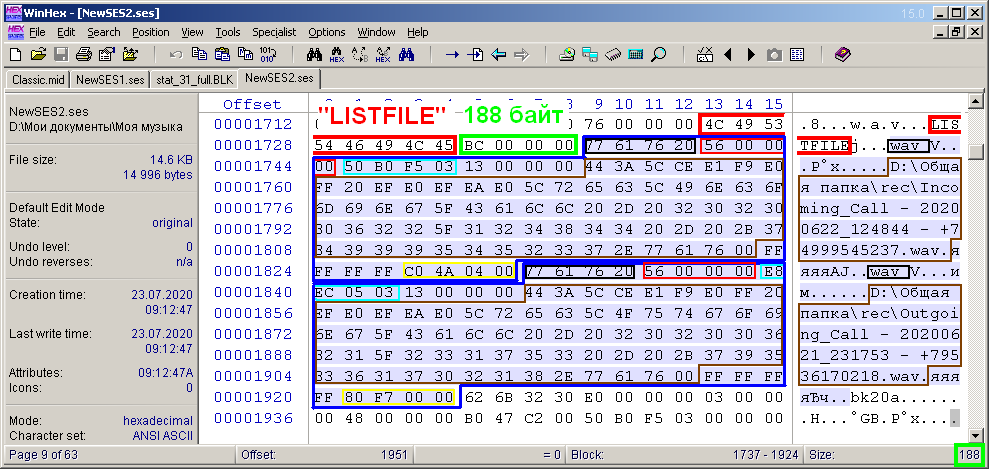
Figure: 12. Bytes of the block of description of audio files "LISTFILE".
Each sub-block corresponds to one audio file. The example uses two audio files, so the number of sub-blocks is appropriate. In contrast to the previous case with track descriptions, there is no subheading about the number of subblocks. The subblock contains 4 bytes of its "wav" header (highlighted in black) and 4 bytes indicating the size of further content (highlighted in magenta). For both sub-blocks, this value is the same in this example and is 0x56 (86) bytes. This is due to the fact that the files are located in the same path and have the same name. More precisely, fully qualified filenames have the same number of characters. Otherwise, the subunits would have different sizes. The sub-block content area (further bytes) contains the following information. A number that identifies the audio file is highlighted in a blue frame.Unlike the track ID, this number is not a file sequence number. As I understand it, when saving a multisession, it is assigned randomly or pseudo-randomly for each file. The main thing is that there is no coincidence among these values. I was convinced of this when I saved the multisession twice and compared the ses files by content. As a result, it turned out that the files differ just by these same bytes. And not only these. A random number is also assigned to the ID of the envelope layers in the “ep20” block. But in this block, as mentioned above, there is no need at all, and its description will not be considered in this article. Audio IDs are needed to link them to clips. This link takes place in the block with the description of clips.In my case, for a multisession with telephone conversations, the identifiers for the audio files will be a sequence of natural numbers, but starting not from zero, but, for example, from 1000. The next 4 bytes, which I did not highlight, in both subblocks have the value 0x13. Most likely, this value indicates the type of audio file format. You can conditionally consider this value a constant, since all audio files are of the same type. The following byte string describes the full name of the audio file, with a null terminator (such as a line terminator). The size of this chain is one more than the number of characters in the full name of the audio file. Next comes the constant 0xFFFFFFFF. It is followed by a value indicating the number of samples in this audio file (in Fig. 12 highlighted in a yellow frame). For the first file, this value is 0x44AC0, and for the second, it is 0xF780.They just correspond to the decimal values 281280 and 63360, respectively, which have already appeared above in the description of the second multisession example.
Finally, it remains to consider the description of the most difficult block - the block for describing audio clips "bk20" (Fig. 13). By analogy with the previous two figures, the title and size of the block content are highlighted.
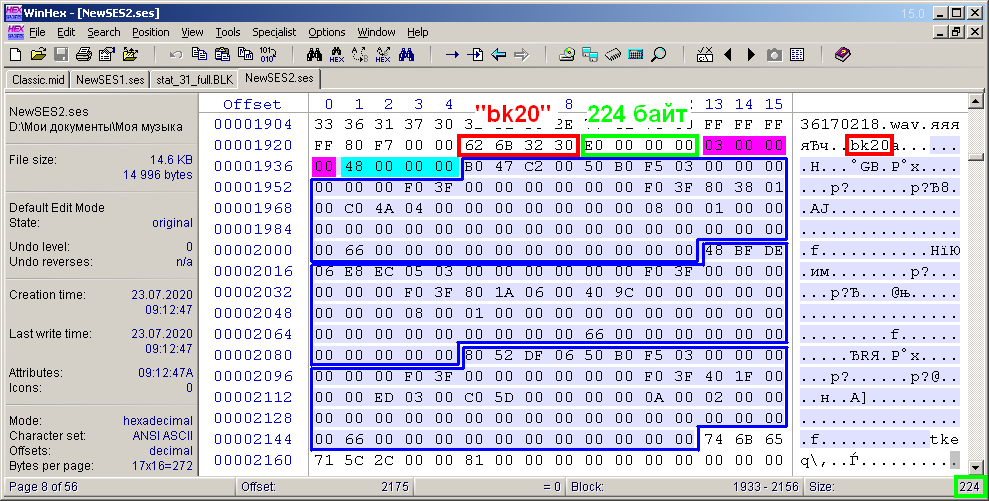
Figure: 13. Bytes of the block of description of audio clips "bk20".
In the content of the block, first of all, there are two subheadings, 4 bytes each. They are highlighted with magenta and cyan fills. The first subtitle is the number of clips in the session. There are three of them in the example. The second subtitle is the constant 0x48 (72). Apparently it indicates the size of each sub-block, and they just go further. Their number is the same as the number of clips in the session. Each such subblock describes the parameters of one clip. By the way, the size D of the content of the "bk20" block, it turns out, can be calculated by the formula D = 8 + 72 * b, where b is the number of audio clips in a multisession. In the figure, there are no explanatory byte allocations within the subblocks, since there are a lot of necessary parameters. They are listed in a separate table (Fig. 14). The blue fill marks those parameters that are necessary in my project, and the gray fill - unrecognized constants.This table also shows the parameter values for each of the three multisession clips from the last example.
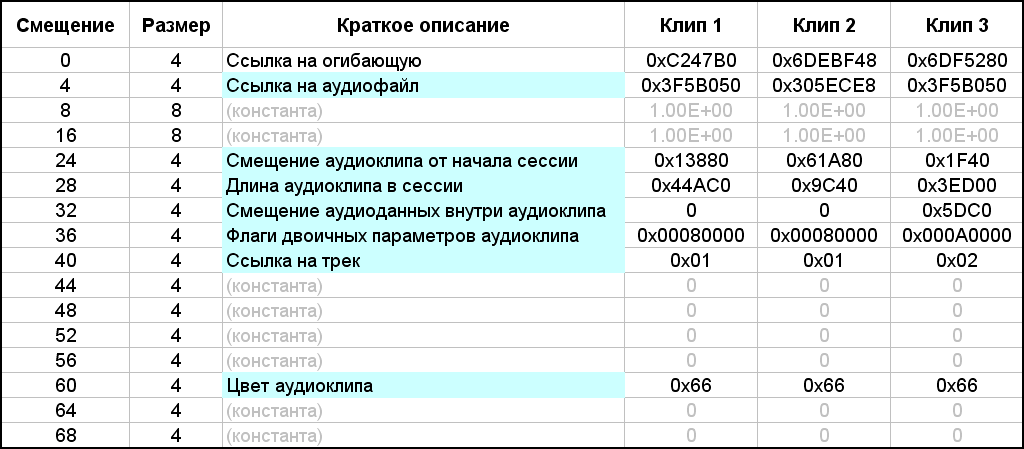
. 14. .
The first word (group of 4 bytes) is a reference to the envelope, which we don't need. The second parameter is a link to the audio file. The value of this parameter is equal to the value of the identifier of the audio file to which this audio clip corresponds. Then there are two real constants, which have already appeared earlier. They are followed by three coordinating parameters expressed in the number of samples: the offset of the clip from the beginning of the session, the length (duration) of the clip in the session, and the offset of the audio within the clip. Everything should be clear from the names of these parameters. A little earlier, when describing in detail the second example of a multisession, I indicated the numerical values of all offsets and durations. In Figure 14, the table lists the parameters for each clip in hexadecimal form. I entered these values into the table by rewriting them directly from Figure 13.But if you convert them to decimal form, then they will coincide with the corresponding values from the description of the second example (checked separately). It should be noted that the links to the audio file for the first and third clips have the same value 0x3F5B050, since both clips refer to the same audio file with the corresponding identifier. This is followed by a block of bytes of binary parameters (4 bytes). As in the case with the description of the tracks, I decoded only part of the bits. The default value is 0x00080000, that is, if translated into binary, then only one bit19 is "raised" to one, and the remaining 31 bits are equal to zero. Without this single bit, as practice has shown, the multisession refuses to load. In the current example, this value is characteristic of the first and second clips, but for the third one, for some reason, the value of the flags is equal to 0x000A0000.If you count, then in this value two bits are "raised": still bit19 and another bit17. I don’t know why it happened. I tried resetting bit17 to zero, changing the value of the entire parameter to 0x00080000, like the adjacent clips. As a result, the session in Adobe Audition opened without any visible changes. While working in Adobe Audition, I noticed clip properties such as "Fix in Time" and "Fix for Playback Only". It is logical to assume that certain bits in the block of binary parameters are responsible for storing these properties. There are also other binary properties for clips, but we do not need them. And the listed two properties will be very useful. The "Fix in time" property is useful because the clip will be protected from the possibility of accidental movement of the mouse pointer in the horizontal direction.But on such a clip, a symbol in the form of a lock in a circle will be visually drawn in the lower left corner, and this is unnecessary graphic information for viewing. The second property of the clip “Fix for playback only” is useful in that when the parameter “R” (Record) is activated on the corresponding track, the clip will not acquire a forced red color. For what I decided to use the parameter "R" on some tracks - it is written above. Empirically, I figured out that bit1 is responsible for the first property of the clip, and bit3 for the second. From all that has been said, the following follows. To set the Clip in Time property, you need to write the value 0x00080002 to the binary parameters. The Commit For Playback Only property is 0x00080008. For both properties, their logical sum is 0x0008000A. Dealt with binary parameters.After these bytes there is a link to the track on which the clip is located. In fact, the track identifier is registered, which coincides with its serial number. Adobe Audition 1.5, by the way, supports no more than 128 tracks, so this identifier fits into one byte, although it is listed as a 32-bit value. Then there are undeciphered zero constants (4 constants, 4 bytes each). Finally, the last significant parameter is the color of the clip. The Adobe Audition 1.5 editor allows you to set a color value from 0 to 239 to a clip in the corresponding dialog box or select it from a palette (Fig. 15). The color palette is not particularly pleasing, but other options are not given. The default clip color is 102 (0x66) (green).by the way, it supports no more than 128 tracks, so such an identifier fits into one byte, although it is listed as a 32-bit value. Then there are undeciphered zero constants (4 constants, 4 bytes each). Finally, the last significant parameter is the color of the clip. The Adobe Audition 1.5 editor allows you to set a color value from 0 to 239 to a clip in the corresponding dialog box or select it from a palette (Fig. 15). The color palette is not particularly pleasing, but other options are not given. The default clip color is 102 (0x66) (green).by the way, it supports no more than 128 tracks, so such an identifier fits into one byte, although it is listed as a 32-bit value. Then there are undeciphered zero constants (4 constants, 4 bytes each). Finally, the last significant parameter is the color of the clip. The Adobe Audition 1.5 editor allows you to set a color value from 0 to 239 to a clip in the corresponding dialog box or select it from a palette (Fig. 15). The color palette is not particularly pleasing, but other options are not given. The default clip color is 102 (0x66) (green).5 allows to set a color value from 0 to 239 to the clip in the corresponding dialog box or select it from the palette (Fig. 15). The color palette is not particularly pleasing, but other options are not given. The default clip color is 102 (0x66) (green).5 allows to set a color value from 0 to 239 to the clip in the corresponding dialog box or select it from the palette (Fig. 15). The color palette is not particularly pleasing, but other options are not given. The default clip color is 102 (0x66) (green).
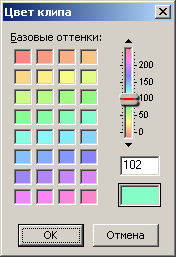
. 15. Adobe Audition 1.5.
The color parameter in the ses file is 32-bit, and in fact there are only 240 colors, which fits in one byte. The other three most significant bytes are zero. I had an idea that if I try to edit these bytes for different values, then when opening a multisession, new colors will appear on the clip. But this trick didn't work. As discussed in the previous article, colors in a chart are useful for visually highlighting a particular feature of a phone call. A multisession of audio recordings of phone calls will resemble a similar diagram, so the color of the clips will be very helpful. The clip color parameter is followed by two words of zeros. This completes the description of the subunit. These eight bytes of zeros are the last in the sub-block of the last block. Therefore, they will also be the last in the entire ses file.
While thinking about the project, I came up with another idea: to add markers (cue points) to the multisession, placing them every hour and signing the appropriate marks to them. If we compare this idea with the previous article, then this is a complete analogy of the vertical lines on the diagram, drawn every hour. In order for the cue points to be present in the multisession, it is necessary to take into account the sixth block called "cues". I did not begin to understand the bytes of this block. By analogy with the "stat" block, in the created multisession for 24 hours, I placed 23 cue points manually every hour and gave them the appropriate names. Then I saved the multisession as a separate ses file, cut out the contents of the "cues" block and saved it to the "cues_24h.BLK" file. This file will be taken into account when developing the program. The bytes of this file are shown in Figure 16. I don't know why,but I saved exactly the content, without the title and the content size field (as opposed to "stat_31_full.BLK"). These two words will be added in the program code. And the content size is 556 bytes. Of these, 4 bytes are occupied by the subtitle (the number of cue points) and 23 subblocks of 24 bytes each. In Figure 16, the content bytes of the first sub-block are filled in. I decided to make the names of cue points (labels) as follows: 01h, 02h,…, 23h.
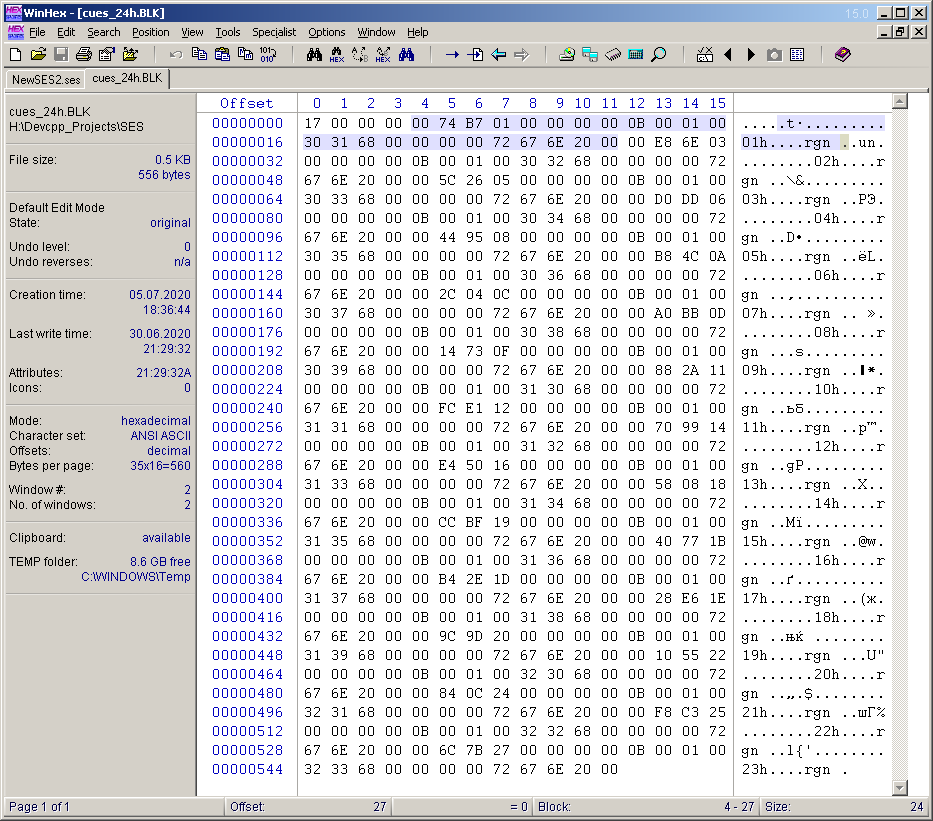
. 16. «cues» .
This concludes the description of the multisession format. Now we have the necessary knowledge base to start writing a program for creating a multisession. Writing a program is an easier task than learning and decrypting the ses format. I completed the program in two evenings, and I spent at least one week studying the format. Moreover, I wrote the program using previously used functions, in particular, working with files and directories. Therefore, the main support for writing the program was not reference books or the Internet, but my past projects, which I also wrote about on Habré. From the Internet, I took only one function that returns the day of the week by date. But before citing the text of the program, I decided to share some more information, which I initially did not want to write about in this article.
The idea to form a multisession from telephone recordings came to me when I was working in a more recent version of Adobe Audition 3.0, which supports audio input / output via ASIO. When saving the multisession, I found that it can be saved in two formats at choice: the usual classic SES and the new XML format, which was not in previous versions of the program. Having saved the session in XML format, I immediately opened this file in notepad, where I found a description of a bunch of parameters linked together in a complex hierarchical structure. For the convenience of viewing this hierarchy, I used the WMHelp XmlPad program. Figure 17 shows a screenshot of this program with a trial simple multisession file open in it. On the left is the document hierarchy. The active (selected) element of the hierarchy is the length parameter of the first audio file,standing in the first subunit of the audio file description block.
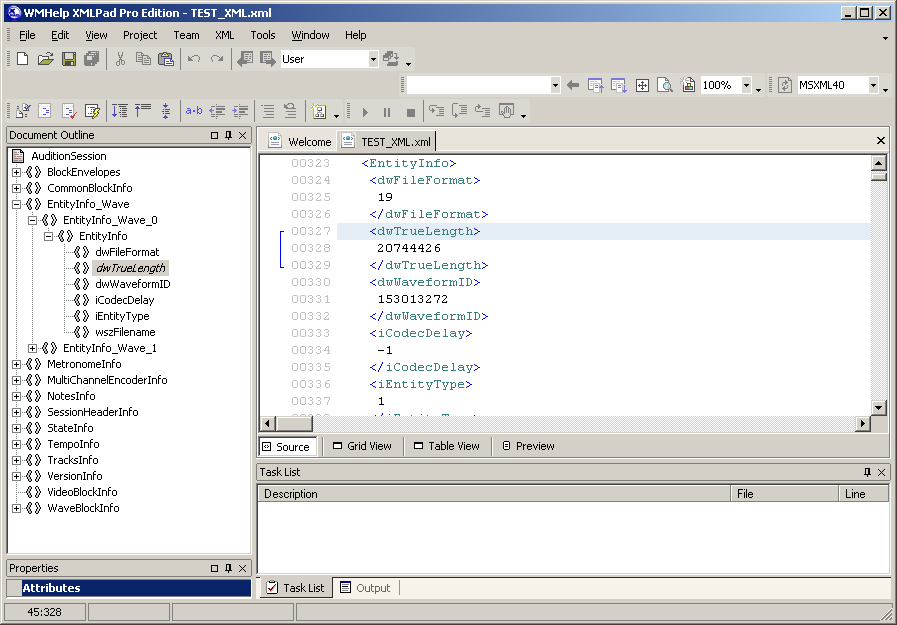
. 17. XML Adobe Audition 3.0.
I decided to study this particular format, and in the future programmatically generate the required XML text, getting the desired multisession at the output. There was even an idea to use Excel for this purpose. The difficulty was that about 95% of the entire XML file is occupied by the track description block. There is a colossal number of parameters, which I could not exclude without harming the multisession. The fact is that in this version of Adobe Audition there are many more functions related to tracks. Logically, there is no need for these functions for my simple multisession. However, by excluding the corresponding fields from the XML document, the session ceases to live. And I would have to "pull" this huge chunk of text in the description of each track for the simplest session. This is the only inconvenience when generating a multisession XML file. Knowledge,the multisession variants obtained during the study of textual XML, of course, were useful during the study of binary ses. And even in XML, I could not decrypt some parameters. The fields of each parameter have an abbreviated name in English, but even so, I did not always understand what this parameter was. The main thing is that I was able to study and decipher the basic necessary parameters, their hierarchical blocks and fields. Then I was tormented for a long time by the question: how to open such a session in an older version of Adobe Audition? New versions of the programs have a very sophisticated interface (almost 3D), which is very inconvenient for visualizing a multisession like diagrams. And because of this "three-de" in Adobe Audition 3.0 with a fully expanded window on the FullHD screen, a maximum (at minimum scale) of 28 tracks fits. And in Adobe Audition 1.5, 37 would fit (Fig.18, scale 1: 2). In total, 31 tracks need to be shown on the screen.
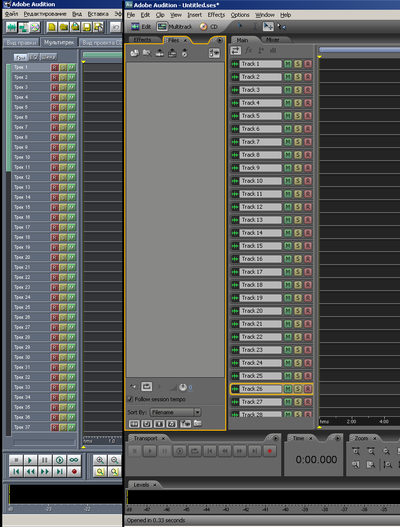
. 18. Adobe Audition .
But most of all I finished off the sound quality when playing a multisession with a frequency of 8000 Hz in the new version of the program. The sound is not very good, harmonic distortion is present. This is due to the fact that the sound is output at a different sample rate (48 kHz), and ASIO cannot do otherwise. The situation does not change when you select another output device "Audition 3.0 Windows Sound" in the settings. The new version of the program does not support classical "DirectSound" output devices (I call version 3.0 new). Figure 19 shows the audio spectrum when playing back 8 kHz audio (or session) in Adobe Audition 3.0 with an inverted spectrum harmonic distortion present. Those frequencies are circled in green, which should sound ideally (and nothing else). And the frequencies are circled in red,which are additional distortion. This effect is most likely due to the lack of filtering after the upsampling procedure. It was after this that I decided to take up the study of the SES binary format of the simpler and more enjoyable Adobe Audition 1.5 program. I hoped that after learning the "human" XML format from a newer version of the program, it would not be difficult for me to figure it out, given my experience with binary files. And so it happened: I pretty quickly "promoted" the SES format. And the main thing is that backward compatibility, looking ahead, works quite well: a session formed for version 1.5 opens successfully in version 3.0. Above, I pointed out the disadvantages of Adobe Audition 3.0 related to sound quality and graphical interface. But this version of the program has advantages in multisession navigation. For instance,there is a possibility of operative listening to one audio clip in a multisession by clicking on it with the mouse and then shifting to the right.
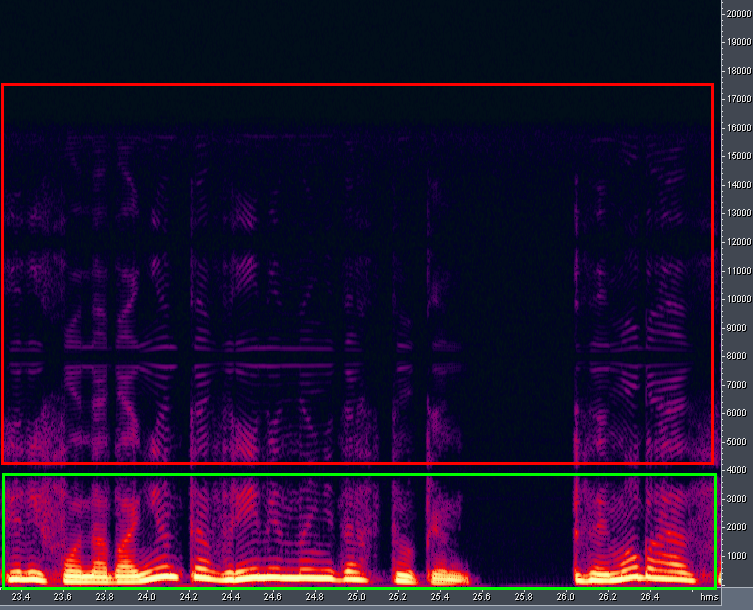
Figure: 19. Harmonic distortion during playback.
Now I will give the text of the program under the spoiler. The program, of course, does not have a graphical interface, since it is not required for this task. The text of the program is provided with detailed comments, so no additional explanation is needed. The program is launched on the command line and within a second processes a list of four hundred files, forming a multisession file. There are four parametric variables inside the program that, if desired, allow you not to generate cue markers, not to put an "R" on tracks on weekends, not to set the "Fix in time" property on clips, and to select the criterion for coloring clips (by call type or by phone numbers) ... These three variables would have to be excluded from the program text and "brought out", that is, in a separate file with program parameters.
C program source code
/********************************************************************
"RMC" ,
wav .
, .
yyyy-mn,
. .
(.. -),
.
, ,
"RMC" "I:".
*********************************************************************/
#include <windows.h>
#include <stdio.h>
#include <string.h>
DWORD wr; // , ;
DWORD ww; // , ;
DWORD wi; // , ;
// ( );
int Date( int D, int M, int Y ){
int a, y, m, R;
a = ( 14 - M ) / 12;
y = Y - a;
m = M + 12 * a - 2;
R = 6999 + ( D + y + y / 4 - y / 100 + y / 400 + (31 * m) / 12 );
return R % 7;
}
// ;
HANDLE openInputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_READ, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
// ;
HANDLE openOutputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_WRITE, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
// ;
void filepos(HANDLE f, __int64 p){
LONG HPos;
LONG LPos;
HPos = p>>32;
LPos = p;
SetFilePointer (f, LPos, &HPos, FILE_BEGIN);
}
// 32- ;
void write32(HANDLE f, signed long int a){
WriteFile(f, &a, 4, &ww, NULL);
}
// ;
void fill(HANDLE f, signed long int a, unsigned char c){
unsigned char i;
for(i=0;i<c;i++){
write32(f,a);
}
}
int main(){
HANDLE out; // Adobe Audition;
HANDLE stat; // "stat" (+ );
HANDLE cues; // "cues";
HANDLE lf; // "LISTFILE";
HANDLE blk; // "bk20";
char* week[7]={"", "", "", "", "", "", ""}; // -;
unsigned char dm[]={31,29,31,30,31,30,31,31,30,31,30,31}; // ;
unsigned char p_cues=1; //: (cues);
unsigned char p_R=1; //: "R" ( ) ;
unsigned char p_lock=1; //: ;
unsigned char p_color=2; // ;
unsigned char flg; // , . ;
unsigned long int lfsize=0; // "LISTFILE";
unsigned long int blksize=0; // "bk20";
unsigned long int smp; // ;
unsigned long int offset; // ;
unsigned int cfile=0; // ;
unsigned int cblk=0; // ;
char name[100]; // ( ...);
char fullname[100]; // ;
char infld[8]; // ;
char number[11]; // . ;
unsigned char len; // ;
printf("Input yyyy-dd name of folder:\n"); // ;
scanf("%s",infld); // ;
WIN32_FIND_DATA fld; // ;
HANDLE hf; // ( , );
char buf1[48],buf2[556]; // "stat" "cues";
char str[16]; // ;
unsigned long int outpos=0; // ;
unsigned char byte; // "LISTFILE" "bk20";
unsigned char i; // ;
unsigned char mn,d,dw,h,m,s; // -;
unsigned char cdm; // ;
int yy; // ;
yy=2000+(infld[2]-48)*10+(infld[3]-48); // ;
mn=(infld[5]-48)*10+(infld[6]-48); // ;
sprintf(name,"I:\\RMC\\%s.ses",infld); // ( );
out=openOutputFile(name); // ;
WriteFile(out, "COOLNESS", 8, &wi, NULL); // : ;
write32(out,0); // ( , );
WriteFile(out, "hdr ", 4, &wi, NULL); //, : ;
write32(out,936); // , 936;
write32(out,8000); // ;
write32(out,24*3600*8000); // (. 24 );
write32(out,0); // ( );
write32(out,0x00010020);
write32(out,0);
write32(out,0x3ff00000);
write32(out,0);
write32(out,0x3ff00000);
filepos(out,328); // ;
write32(out,0x20);
WriteFile(out, "", 6, &wi, NULL); // ;
filepos(out,376); // ;
write32(out,0x3ff00000);
filepos(out,892); // ;
write32(out,0x0430041c);
write32(out,0x04420441);
write32(out,0x04400435);
filepos(out,956); // ;
stat=openInputFile("stat_31_full.BLK"); // ,
ReadFile(stat, &buf1, 48, &wr, NULL); // ;
WriteFile(out, buf1, 48, &wi, NULL);
CloseHandle(stat);
if(mn==2){ // ,
if(!(yy%4)){ // ,
cdm=29; // 29 ,
}else{
cdm=28; // - 28;
}
}else{ // ,
cdm=dm[mn-1]; // ;
}
WriteFile(out, "trks", 4, &wi, NULL); // ;
write32(out,4+cdm*152); // ;
write32(out,cdm); // ;
outpos=1016; // ;
for(i=0;i<cdm;i++){ //
dw=Date(i+1,mn,yy); // ;
write32(out,0); // ses, ;
write32(out,0x3ff00000);
write32(out,0); // 8- double;
write32(out,0x3ff00000);
if((dw%7==5||dw%7==6)&&p_R){ // - , "R",
write32(out,4); // "R",
}else{
write32(out,0); // - ;
}
sprintf(str,"%02d.%02d.%i %s",i+1,mn,yy,week[dw]); // , ;
WriteFile(out, str, strlen(str), &wi, NULL);
filepos(out,1072+152*i); // (i+1)- ;
write32(out,1); // , ;
write32(out,1);
write32(out,4);
write32(out,0);
write32(out,0);
write32(out,0x40590000);
write32(out,0);
write32(out,0);
write32(out,0xffffff9d);
write32(out,0xffffff9d);
write32(out,i+1); // , ;
fill(out,0,11);
write32(out,4);
write32(out,0);
outpos+=152; // ;
}
if(p_cues){ // , "cues";
WriteFile(out, "cues", 4, &wi, NULL); // ,
write32(out,556); // - ;
cues=openInputFile("cues_24h.BLK"); // , ;
ReadFile(cues, &buf2, 556, &wr, NULL); //( , "stat");
WriteFile(out, buf2, 556, &wi, NULL);
CloseHandle(cues);
outpos+=564;
}
DeleteFile("LISTFILE"); // ( )
DeleteFile("bk20"); // "LISTFILE" "bk20",
lf=openOutputFile("LISTFILE"); // ()
blk=openOutputFile("bk20"); // ;
WriteFile(lf, "LISTFILE", 8, &wi, NULL); // ;
WriteFile(blk, "bk20", 4, &wi, NULL);
write32(lf,0);
write32(blk,0);
write32(blk,0);
write32(blk,0x48); // , ;
sprintf(name,"I:\\RMC\\%s\\*.wav",infld); // wav ;
hf=FindFirstFile(name,&fld); // ;
do{ // ;
len=strlen(fld.cFileName); // ;
for(i=10;i>=1;i--){ // 10 ;
number[10-i]=fld.cFileName[len-i-4]; // ;
}
number[10]=0; // , ;
cfile+=1; // ;
sprintf(fullname,"I:\\RMC\\%s\\%s",infld,fld.cFileName); // ;
d=(fld.cFileName[22]-48)*10+(fld.cFileName[23]-48); // () ;
h=(fld.cFileName[25]-48)*10+(fld.cFileName[26]-48); // ;
m=(fld.cFileName[27]-48)*10+(fld.cFileName[28]-48); // ;
s=(fld.cFileName[29]-48)*10+(fld.cFileName[30]-48); // ;
offset=(h*3600+m*60+s)*8000; // ;
smp=(fld.nFileSizeLow-44)/4; // ( );
WriteFile(lf, "wav ", 4, &wi, NULL); // ;
write32(lf,17+strlen(fullname)); // ( );
write32(lf,1000+cfile); // ( , 1000 );
write32(lf,0x14); // ( );
WriteFile(lf, fullname, strlen(fullname), &wi, NULL); // ( );
WriteFile(lf, "\0", 1, &wi, NULL); // ;
write32(lf,0xffffffff); //;
write32(lf,smp); // ;
lfsize+=(25+strlen(fullname)); // "LISTFILE";
cblk+=1; // ;
write32(blk,0); // , ;
write32(blk,1000+cfile); // ();
write32(blk,0); // ;
write32(blk,0x3ff00000);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,offset); // ;
if(((24*3600*8000)-offset)>smp){ // ( ) ,
write32(blk,smp); // ,
}else{
write32(blk,(24*3600*8000)-offset); // ;
}
write32(blk,0); // ;
if(p_lock){ // ,
write32(blk,0x0008000a); // (3 32 ),
}else{
write32(blk,0x00080008); // (2 32 );
} // - " ";
write32(blk,d); // ( );
fill(blk,0,4); // ;
switch(p_color){ // ;
case 1: // ;
switch(fld.cFileName[0]){ // ;
case 'I': // "I" ( ),
write32(blk,0); // ;
break;
case 'O': // "O" ( ),
write32(blk,102); // ( );
break;
default: // - ,
write32(blk,102); // ;
break;
}
break;
case 2: // ;
flg=0; // ;
if(!strcmp("9530000000",number)){ // - - ,
write32(blk,05); // - -,
flg=1; //( );
}
#include "numbers_and_colors.cpp" // - ();
if(!flg){ // ( ),
write32(blk,102); // ;
}
break;
}
write32(blk,0);
write32(blk,0);
if(((24*3600*8000)-offset)<=smp){ // ( ) ( ),
cblk+=1; // ;
write32(blk,0); // , ;
write32(blk,1000+cfile);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,0); // ,
write32(blk,smp-((24*3600*8000)-offset)); // ,
write32(blk,(24*3600*8000)-offset); // , ;
if(p_lock){
write32(blk,0x0008000a);
}else{
write32(blk,0x00080008);
}
write32(blk,d+1); // () ();
fill(blk,0,4);
switch(p_color){ // ;
case 1: // ;
switch(fld.cFileName[0]){ // ( );
case 'I': // ,
write32(blk,0); // ;
break;
case 'O': // ,
write32(blk,102); // , ;
break;
default: // - ( ),
write32(blk,102); // ;
break;
}
break;
case 2: // ;
flg=0;
if(!strcmp("9530000000",number)){ // - - ,
write32(blk,05); // - -,
flg=1; //( );
}
#include "numbers_and_colors.cpp" // ( );
if(!flg){ // ,
write32(blk,102); // ;
}
break;
}
write32(blk,0);
write32(blk,0);
}
}while(FindNextFile(hf,&fld)); // wav ;
filepos(lf,8);
write32(lf,lfsize); // "LISTFILE", ;
filepos(blk,4);
blksize=8+72*cblk; // "bk20", ;
write32(blk,blksize); // "bk20";
write32(blk,cblk); // ;
blksize+=8; // "bk20", . ;
lfsize+=12; // "LISTFILE", . ;
CloseHandle(lf); // . ;
CloseHandle(blk); // . ;
lf=openInputFile("LISTFILE"); // . ;
do{ // , ( );
ReadFile(lf, &byte, 1, &wr, NULL);
if(wr){
WriteFile(out, &byte, 1, &wi, NULL);
}
}while(wr);
CloseHandle(lf); // . ;
blk=openInputFile("bk20"); // . ;
do{ // , ( );
ReadFile(blk, &byte, 1, &wr, NULL);
if(wr){
WriteFile(out, &byte, 1, &wi, NULL);
}
}while(wr);
CloseHandle(blk); // . ;
outpos=outpos+blksize+lfsize; // ;
filepos(out,8);
write32(out,outpos-12); // ;
filepos(out,28);
write32(out,cblk); // ;
CloseHandle(out); // ! ;
printf("c_files: %i\nc_block: %i\n",cfile,cblk); // ( );
system("PAUSE");
return 0;
}
Now you can show screenshots of the results. There will be several of them: at different viewing scales, in different versions of the program and with different coloring criteria. The catalog "2020-05" was processed, that is, the records for May of the current year. A total of 446 records were processed. The number of blocks is the same, since there are no records with the transition to a new day.
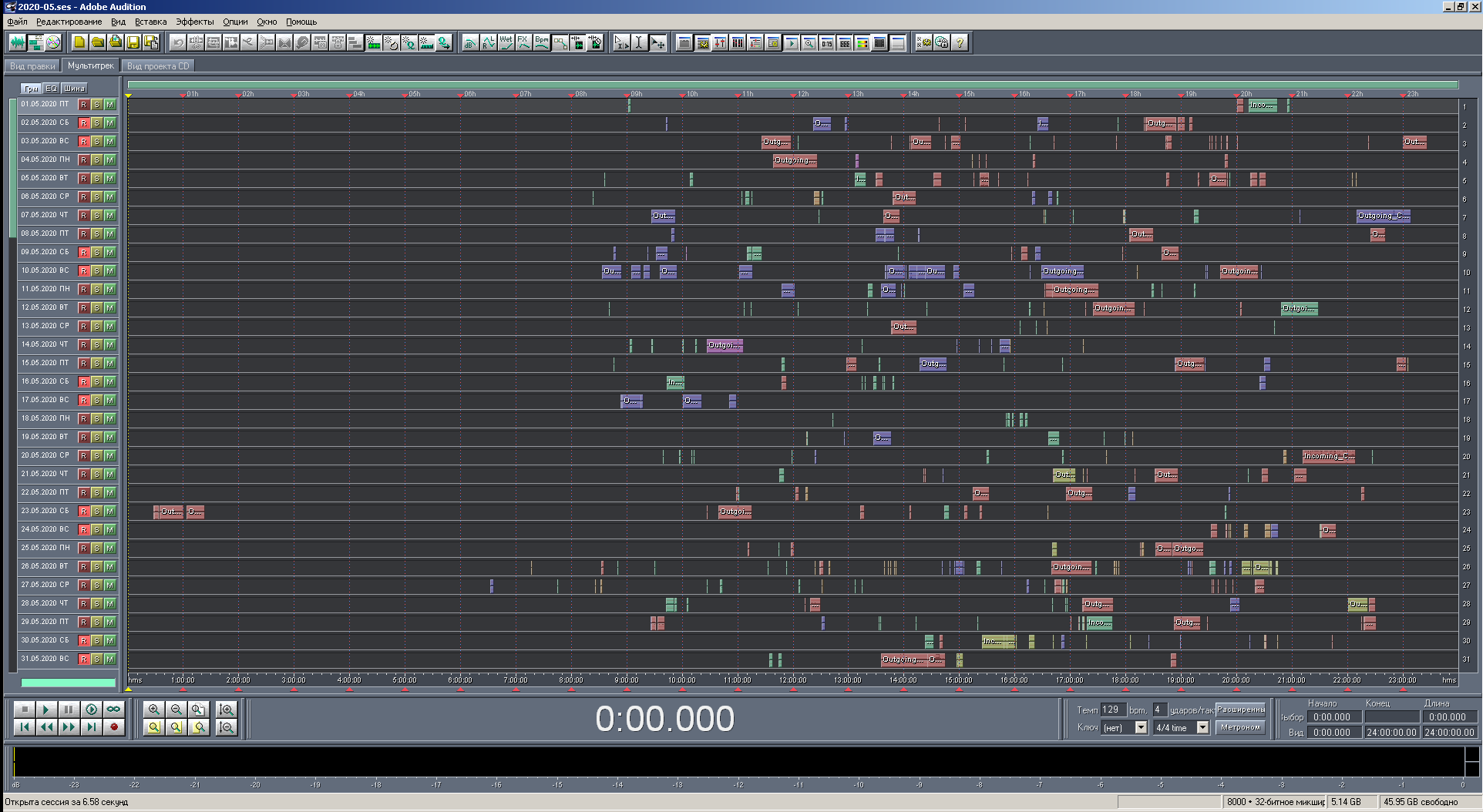
Figure: 20. View of the multisession in full scale with coloring by phone. numbers.
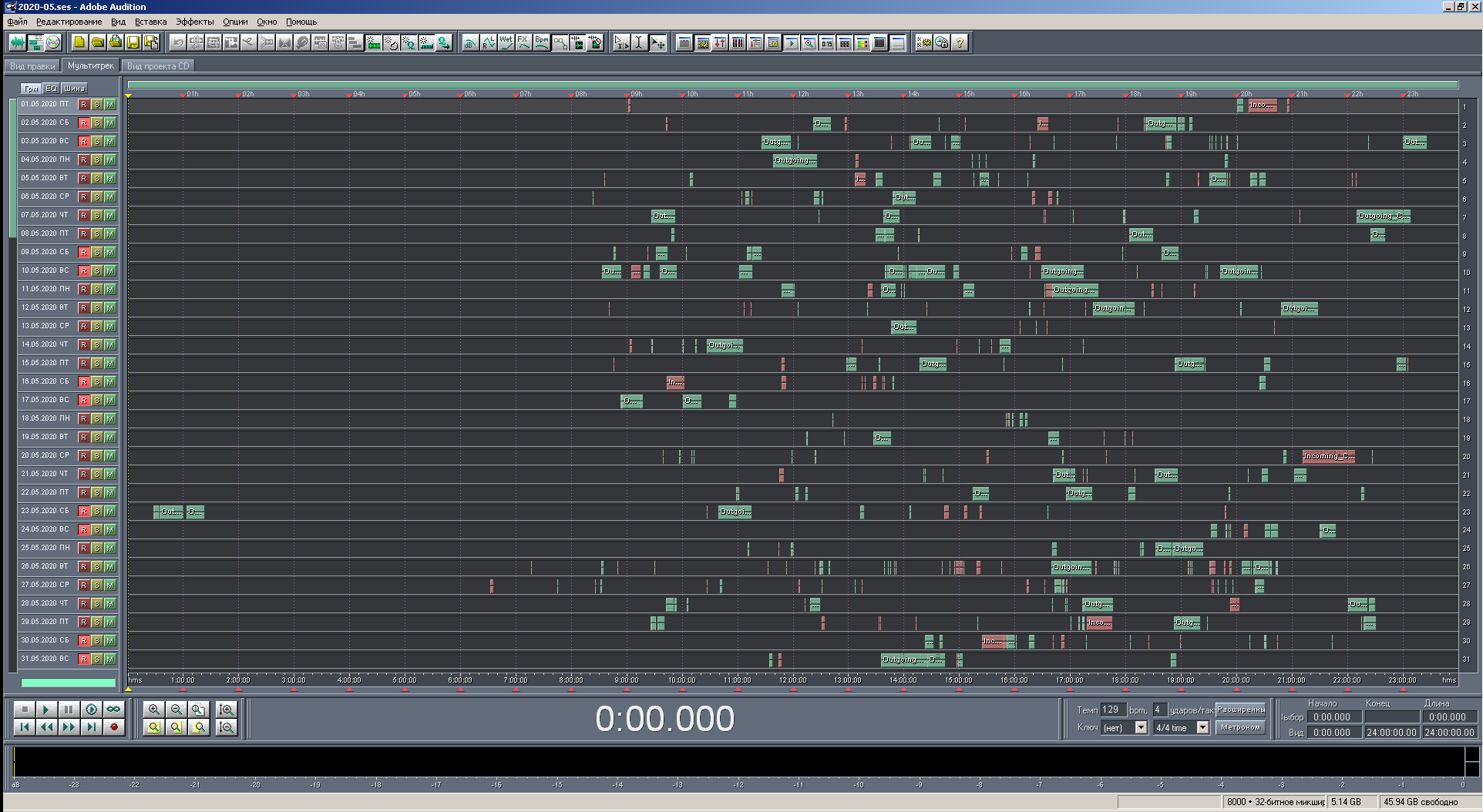
Figure: 21. View of multisession in full scale with coloring by call type.
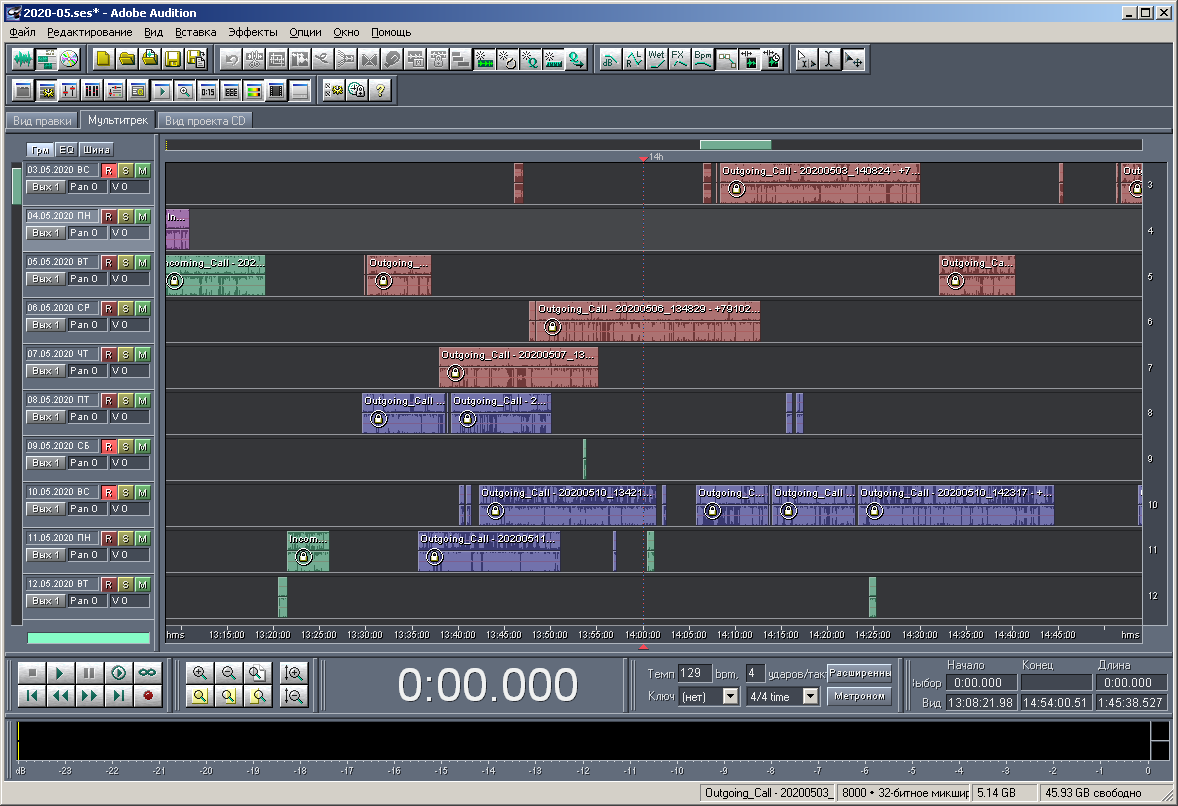
Figure: 22. View of a multisession on a medium scale.
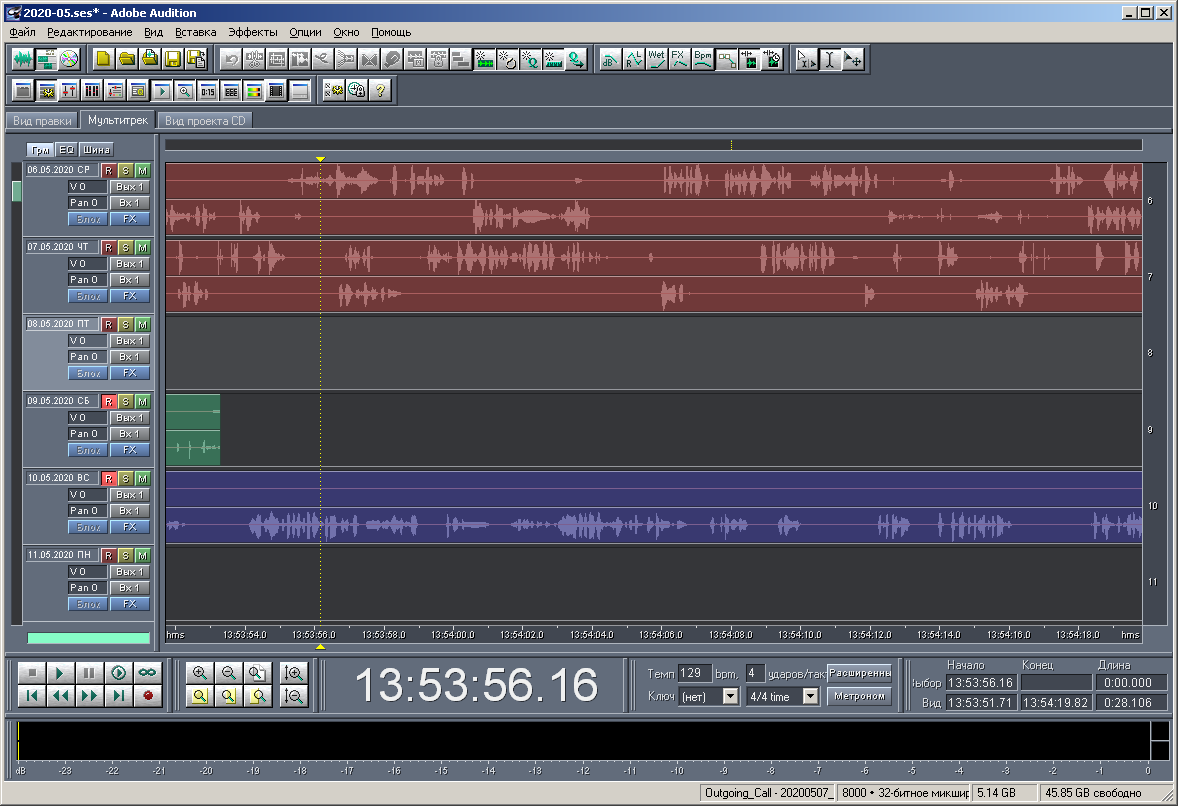
Figure: 23. View of a multisession on a large scale.
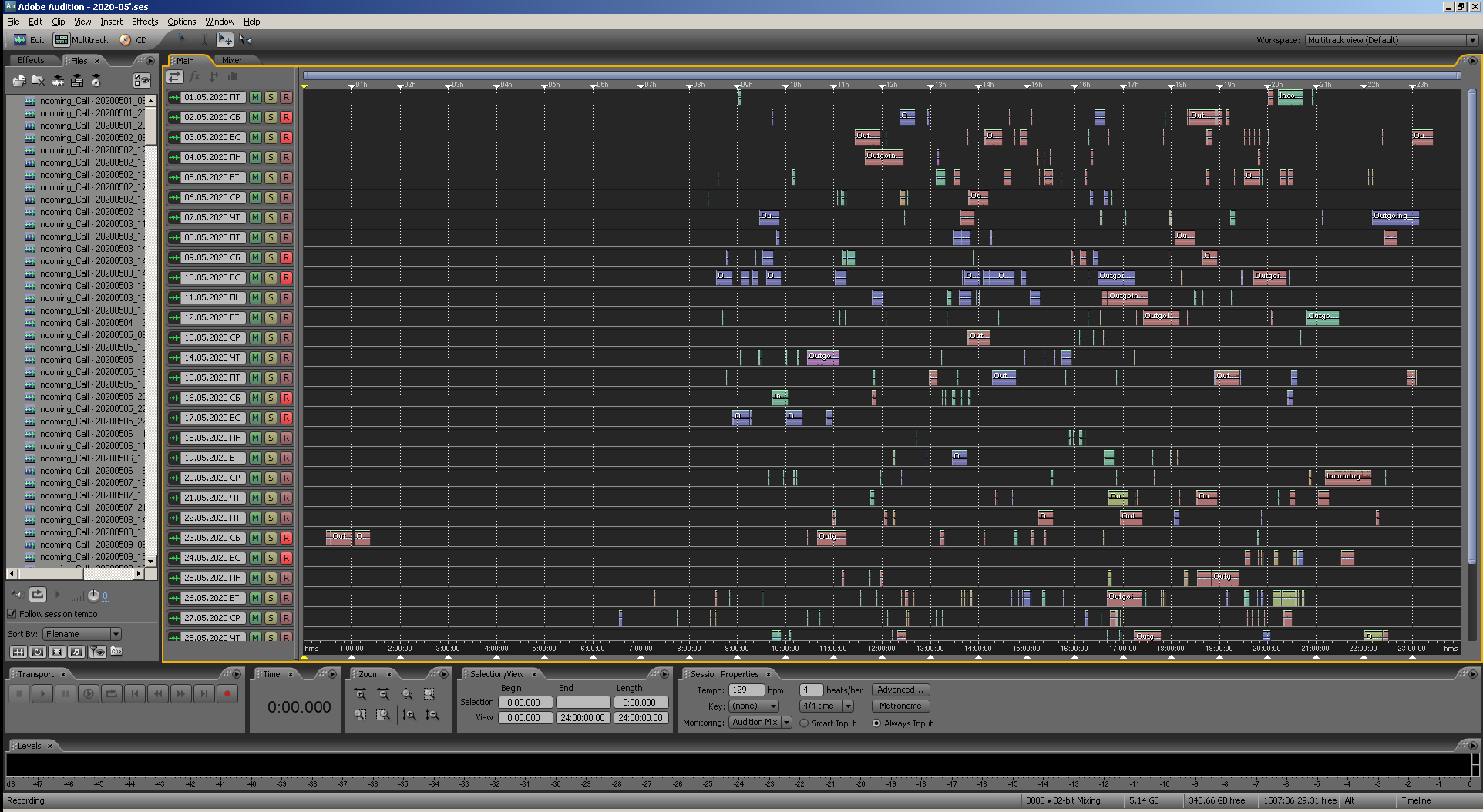
Figure: 24. View of the same multisession in Adobe Audition 3.0.