
This article will describe the experience of creating a neural network for face recognition, for sorting all photos from a VK conversation to find a specific person. Without any experience in writing neural networks and minimal knowledge of Python.
Introduction
We have a friend, whose name is Sergei, who loves to photograph himself in an unusual way and send in a conversation, and also spices these photos with corporate phrases. So one of the evenings on the discord, we had an idea - to create a public in VK, where we could post Sergey with his quotes. The first 10 posts in the postponement were easy, but then it became clear that there was no point in going over all the attachments in a conversation with your hands. So it was decided to write a neural network to automate this process.
Plan
- Get links to photos from a conversation
- Download photos
- Writing a neural network
Before starting development
, Python pip. , 0, ,
1. Getting links to photos
So we want to get all the photos from the conversation, the messages.getHistoryAttachments method is suitable for us , which returns the materials of the dialogue or conversation.
Since February 15, 2019, Vkontakte has denied access to messages for applications that have not passed moderation. As a workaround, I can suggest vkhost , which will help you get a token from third-party messengers
With the received token on vkhost, we can collect the API request we need using Postman . You can, of course, fill everything with pens without it, but for clarity we will use
it.Fill in the parameters:
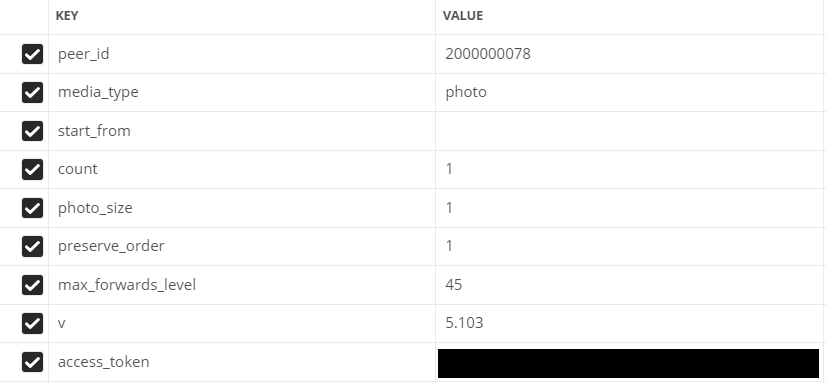
- peer_id - destination identifier
For a conversation: 2,000,000,000 + conversation id (can be seen in the address bar).
For user: user id. - media_type - media type
In our case, photo
- start_from - offset to select multiple items.
Let's leave it empty for now.
- count - the number of received objects
Maximum 200, that's how much we will use
- photo_sizes - flag to return all sizes in the array
1 or 0. We use 1
- preserve_order - flag indicating whether attachments should be returned in their original order
1 or 0. We use 1
- v - vk api version
1 or 0. We use 1
Filled fields in Postman
Go to writing code
For convenience, all the code will be split into several separate scripts.
Will use the json module (to decode the data) and the requests library (to make http requests)
Code Listing if there are less than 200 photos in a conversation / dialogue
import json
import requests
val = 1 #
Fin = open("input.txt","a") #
# GET API response
response = requests.get("https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from=&count=10&photo_size=1&preserve_order=1&max_forwards_level=45&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
# GET ,
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
Fin.write(str(link)+"\n") #
val += 1 #
If there are more than 200 photos
import json
import requests
next = None #
def newfunc():
val = 1 #
global next
Fin = open("input.txt","a") #
# GET API response
response = requests.get(f"https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from={next}&count=200&photo_size=1&preserve_order=1&max_forwards_level=44&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
if items['response']['items'] != []: #
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
val += 1 #
Fin.write(str(link)+"\n") #
next = items['response']['next_from'] #
print('dd',items['response']['next_from'])
newfunc() #
else: #
print(" ")
newfunc()It's time to download links
2. Downloading images
To download photos we use the urllib library
import urllib.request
f = open('input.txt') #
val = 1 #
for line in f: #
line = line.rstrip('\n')
# "img"
urllib.request.urlretrieve(line, f"img/{val}.jpg")
print(val,':','') #
val += 1 #
print("")
The process of loading all the images is not the fastest, especially if the photos are 8330. Space for this case is also required, if the number of photos is the same as mine or more, I recommend freeing up 1.5 - 2 GB for this . The

rough work is finished, now you can start yourself interesting - writing a neural network
3. Writing a neural network
After looking through many different libraries and options, it was decided to use the Face Recognition library
What can it do?
From the documentation, consider the most basic features of
search faces in photos
may find any number of people in the photo, even copes with fuzzy

identification on individual photos
can recognize who belongs to the person in the picture

for us the most suitable method will be the identification of persons
Training
From the requirements for the library, Python 3.3+ or Python 2.7 is required.
Regarding the libraries, the above-mentioned Face Recognition and PIL will be used to work with images.
The Face Recognition library is not officially supported on Windows , but it worked for me. Everything works stably with macOS and Linux.
Explanation of what is happening
To begin with, we need to set a classifier to search for a person, by whom further verification of photos will already occur.
I recommend choosing the clearest possible photo of a person in frontal view.When uploading a photo, the library breaks the images into the coordinates of a person's facial features (nose, eyes, mouth and chin)

Well, then the matter is small, it remains only to apply a similar method to the photo that we want to compare with our classifier. Then we let the neural network compare facial features by coordinates.
Well, the actual code itself:
import face_recognition
from PIL import Image #
find_face = face_recognition.load_image_file("face/sergey.jpg") #
face_encoding = face_recognition.face_encodings(find_face)[0] # ,
i = 0 #
done = 0 #
numFiles = 8330 # -
while i != numFiles:
i += 1 #
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) #
pil_image = Image.fromarray(unknown_picture) #
#
if len(unknown_face_encoding) > 0: #
encoding = unknown_face_encoding[0] # 0 ,
results = face_recognition.compare_faces([face_encoding], encoding) #
if results[0] == True: #
done += 1 #
print(i,"-"," !")
pil_image.save(f"done/{int(done)}.jpg") #
else: #
print(i,"-"," !")
else: #
print(i,"-"," !")
It is also possible to run everything according to in-depth analysis on a video card, for this you need to add the model = "cnn" parameter and change the code fragment for the image with which we want to search for the right person:
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
face_locations = face_recognition.face_locations(unknown_picture, model= "cnn") # GPU
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) # Result
No GPU. By time, the neural network went through and sorted 8330 photos in 1 hour 40 minutes and at the same time found 142 photos, 62 of them with the image of the desired person. Of course there have been false positives on memes and other people.
C GPU. The processing time took much more, 17 hours and 22 minutes, and I found 230 photos of which 99 are the person we need.
In conclusion, we can say that the work was not done in vain. We have automated the process of sorting 8,330 photos, which is much better than going through it yourself.
You can also download the entire source code from github