
In the modern world of Big Data, Apache Spark is the de facto standard for developing batch data processing tasks. In addition, it is also used to create streaming applications operating in the micro batch concept, processing and sending data in small portions (Spark Structured Streaming). And traditionally it has been part of the overall Hadoop stack, using YARN (or, in some cases, Apache Mesos) as the resource manager. By 2020, its traditional use for most companies is under a big question due to the lack of decent Hadoop distributions - the development of HDP and CDH has stopped, CDH is underdeveloped and has a high cost, and the rest of the Hadoop providers have either ceased to exist or have a vague future.Therefore, the growing interest among the community and large companies is the launch of Apache Spark using Kubernetes - becoming the standard in container orchestration and resource management in private and public clouds, it solves the problem of inconvenient resource scheduling of Spark tasks on YARN and provides a steadily developing platform with many commercial and open source distributions for companies of all sizes and stripes. In addition, on the wave of popularity, the majority have already managed to acquire a couple of their installations and increase their expertise in using it, which simplifies the move.it solves the awkward scheduling of Spark tasks on YARN and provides a steadily evolving platform with many commercial and open source distributions for companies of all sizes and stripes. In addition, on the wave of popularity, the majority have already managed to acquire a couple of their installations and increase their expertise in using it, which simplifies the move.it solves the awkward scheduling of Spark tasks on YARN and provides a steadily evolving platform with many commercial and open source distributions for companies of all sizes and stripes. In addition, on the wave of popularity, the majority have already managed to acquire a couple of their installations and increase their expertise in using it, which simplifies the move.
Starting with version 2.3.0, Apache Spark acquired official support for running tasks in the Kubernetes cluster, and today, we will talk about the current maturity of this approach, the various options for its use and the pitfalls that will be encountered during implementation.
First of all, we will consider the process of developing tasks and applications based on Apache Spark and highlight typical cases in which you need to run a task on a Kubernetes cluster. When preparing this post, OpenShift is used as a distribution kit and the commands that are relevant for its command line utility (oc) will be given. For other Kubernetes distributions, the corresponding commands of the standard Kubernetes command line utility (kubectl) or their analogs (for example, for oc adm policy) can be used.
The first use case is spark-submit
In the process of developing tasks and applications, the developer needs to run tasks to debug data transformation. Theoretically, stubs can be used for these purposes, but development with the participation of real (albeit test) instances of finite systems has shown itself in this class of problems faster and better. In the case when we debug on real instances of end systems, two scenarios are possible:
- the developer runs the Spark task locally in standalone mode;
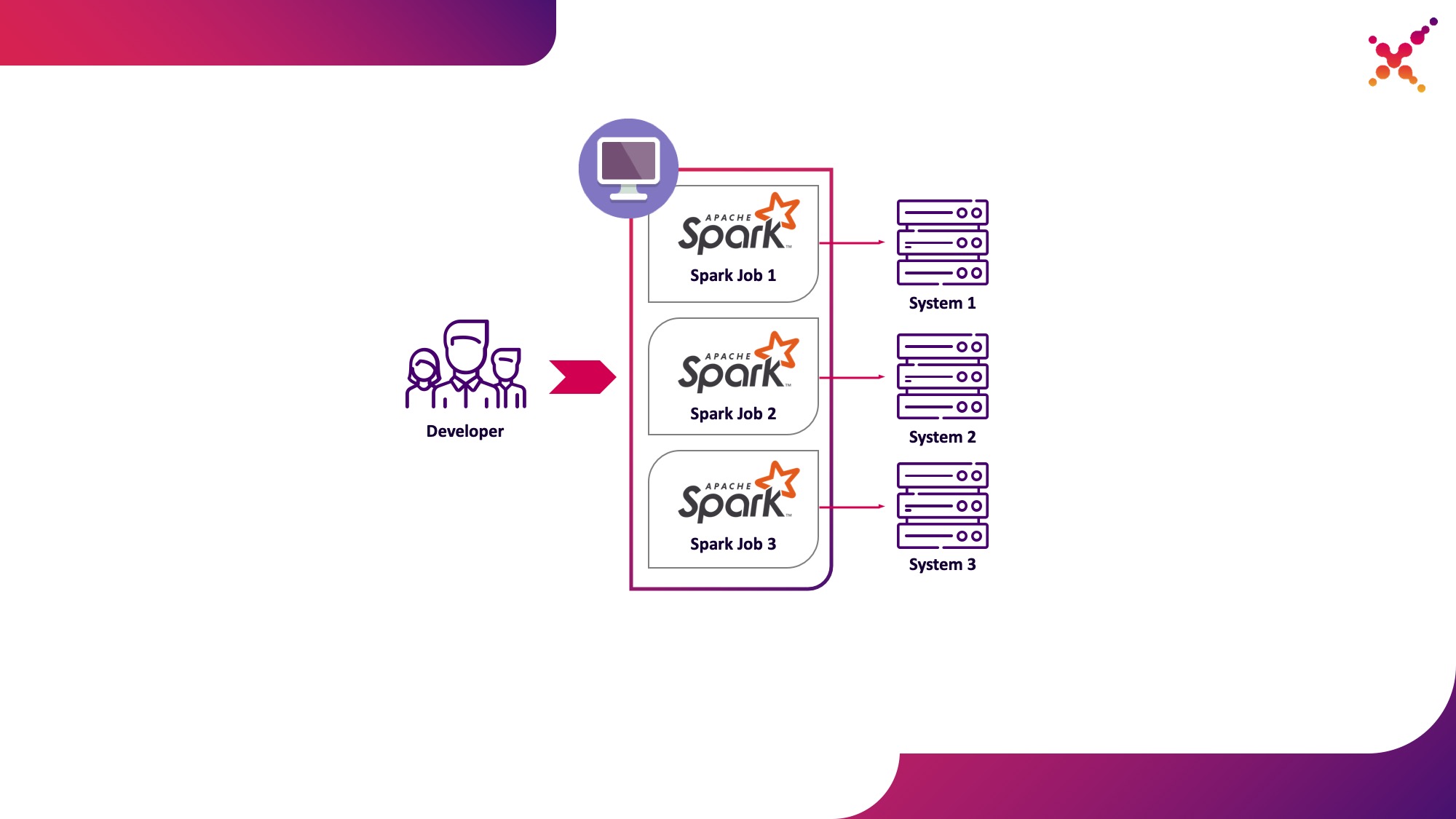
- a developer runs a Spark task on a Kubernetes cluster in a test loop.

The first option has the right to exist, but it entails a number of disadvantages:
- for each developer, it is required to provide access from the workplace to all the copies of the end systems he needs;
- the working machine requires sufficient resources to run the developed task.
The second option is devoid of these disadvantages, since the use of a Kubernetes cluster allows you to allocate the necessary pool of resources for running tasks and provide it with the necessary access to instances of end systems, flexibly providing access to it using the Kubernetes role model for all members of the development team. Let's highlight it as the first use case - running Spark tasks from a local development machine on a Kubernetes cluster in a test loop.
Let's take a closer look at the process of configuring Spark to run locally. To start using Spark, you need to install it:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
We collect the necessary packages for working with Kubernetes:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
The complete build takes a lot of time, and to build Docker images and run them on the Kubernetes cluster, in reality, you only need jar files from the "assembly /" directory, so you can only build this subproject:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
To run Spark tasks in Kubernetes, you need to create a Docker image to use as the base image. 2 approaches are possible here:
- The generated Docker image includes the executable code for the Spark task;
- The created image includes only Spark and the necessary dependencies, the executable code is hosted remotely (for example, in HDFS).
First, let's build a Docker image containing a test example of a Spark task. For building Docker images, Spark has a utility called "docker-image-tool". Let's study the help on it:
./bin/docker-image-tool.sh --help
It can be used to create Docker images and upload them to remote registries, but by default it has several disadvantages:
- without fail creates 3 Docker images at once - for Spark, PySpark and R;
- does not allow you to specify the name of the image.
Therefore, we will use a modified version of this utility, shown below:
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}" \
-t $(image_ref $IMAGE_REF) \
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
Using it, we build a base Spark image containing a test task for calculating the Pi number using Spark (here {docker-registry-url} is the URL of your Docker image registry, {repo} is the name of the repository inside the registry, which coincides with the project in OpenShift , {image-name} is the name of the image (if three-level image separation is used, for example, as in the Red Hat OpenShift integrated image registry), {tag} is the tag of this version of the image):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
Log in to the OKD cluster using the console utility (here {OKD-API-URL} is the OKD cluster API URL):
oc login {OKD-API-URL}
Let's get the token of the current user for authorization in the Docker Registry:
oc whoami -t
Log in to the internal Docker Registry of the OKD cluster (use the token obtained with the previous command as the password):
docker login {docker-registry-url}
Upload the built Docker image to the Docker Registry OKD:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
Let's check that the assembled image is available in OKD. To do this, open the URL with a list of images of the corresponding project in the browser (here {project} is the name of the project inside the OpenShift cluster, {OKD-WEBUI-URL} is the URL of the OpenShift Web console) - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / images / {image-name}.
To run tasks, a service account must be created with the privileges of running pods as root (we will discuss this point later):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
Run spark-submit to publish the Spark task to the OKD cluster, specifying the created service account and Docker image:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
Here:
--name is the name of the task that will participate in the formation of the Kubernetes pod name;
--class - the class of the executable file, called when the task starts;
--conf - Spark configuration parameters;
spark.executor.instances The number of Spark executors to run.
spark.kubernetes.authenticate.driver.serviceAccountName The name of the Kubernetes service account used when launching pods (to define the security context and capabilities when interacting with the Kubernetes API);
spark.kubernetes.namespace - Kubernetes namespace in which the driver and executor pods will run;
spark.submit.deployMode - Spark launch method ("cluster" is used for standard spark-submit, "client" for Spark Operator and later versions of Spark);
spark.kubernetes.container.image The Docker image used to run the pods.
spark.master - URL of the Kubernetes API (the external is specified so that the call occurs from the local machine);
local: // is the path to the Spark executable inside the Docker image.
Go to the corresponding OKD project and study the created pods - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods.
To simplify the development process, another option can be used, in which a common base Spark image is created that is used by all tasks to run, and snapshots of the executable files are published to an external storage (for example, Hadoop) and specified when calling spark-submit as a link. In this case, you can run different versions of Spark tasks without rebuilding Docker images, using, for example, WebHDFS to publish images. We send a request to create a file (here {host} is the host of the WebHDFS service, {port} is the port of the WebHDFS service, {path-to-file-on-hdfs} is the desired path to the file on HDFS):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
This will receive a response of the form (here {location} is the URL that must be used to download the file):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
Load the Spark executable file into HDFS (here {path-to-local-file} is the path to the Spark executable on the current host):
curl -i -X PUT -T {path-to-local-file} "{location}"
After that, we can make spark-submit using the Spark file uploaded to HDFS (here {class-name} is the name of the class that needs to be launched to complete the task):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
It should be noted that in order to access HDFS and ensure the operation of the task, you may need to change the Dockerfile and the entrypoint.sh script - add a directive to the Dockerfile to copy dependent libraries to the / opt / spark / jars directory and include the HDFS configuration file in SPARK_CLASSPATH in the entrypoint. sh.
Second use case - Apache Livy
Further, when the task is developed and it is required to test the result obtained, the question arises of launching it within the CI / CD process and tracking the status of its execution. Of course, you can run it using a local spark-submit call, but this complicates the CI / CD infrastructure since it requires installing and configuring Spark on the CI server agents / runners and setting up access to the Kubernetes API. For this case, the target implementation has chosen to use Apache Livy as the REST API for running Spark tasks hosted inside the Kubernetes cluster. It can be used to launch Spark tasks on the Kubernetes cluster using regular cURL requests, which is easily implemented based on any CI solution, and its placement inside the Kubernetes cluster solves the issue of authentication when interacting with the Kubernetes API.
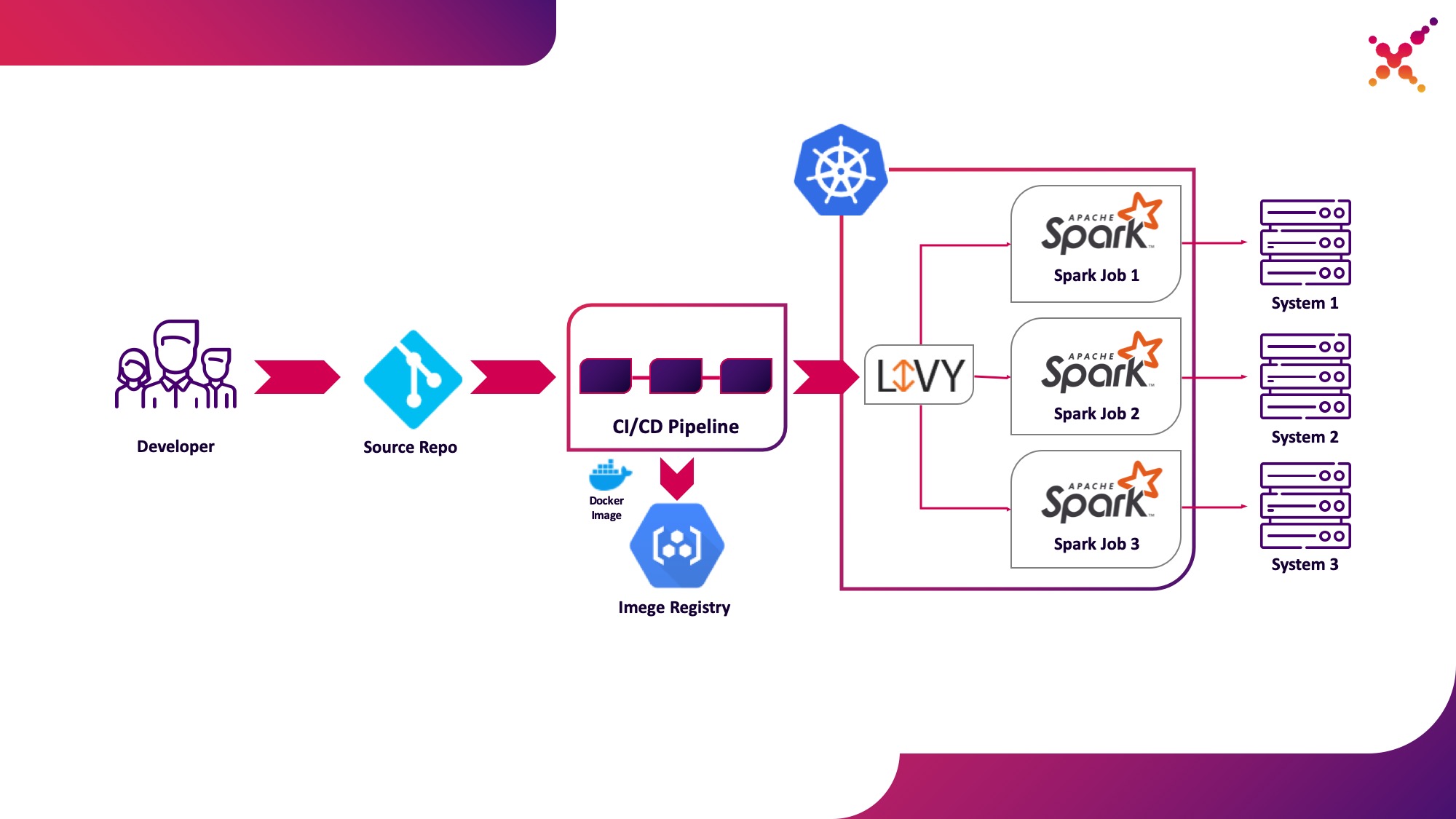
Let's highlight it as the second use case - running Spark tasks as part of the CI / CD process on a Kubernetes cluster in a test loop.
A little about Apache Livy - it works as an HTTP server providing a Web interface and a RESTful API that allows you to remotely launch spark-submit by passing the required parameters. Traditionally it was shipped as part of the HDP distribution, but can also be deployed to OKD or any other Kubernetes installation using the appropriate manifest and a set of Docker images, for example, this one - github.com/ttauveron/k8s-big-data-experiments/tree/master /livy-spark-2.3 . For our case, a similar Docker image was built, including Spark version 2.4.5 from the following Dockerfile:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash && \
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz && \
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz && \
rm spark-2.4.5-bin-hadoop2.7.tgz && \
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip && \
unzip apache-livy-0.7.0-incubating-bin.zip && \
rm apache-livy-0.7.0-incubating-bin.zip && \
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy && \
mkdir /var/log/livy && \
ln -s /var/log/livy /opt/livy/logs && \
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
The generated image can be built and uploaded to your existing Docker repository, for example, the internal OKD repository. To deploy it, the following manifest is used ({registry-url} is the URL of the Docker image registry, {image-name} is the name of the Docker image, {tag} is the tag of the Docker image, {livy-url} is the desired URL at which the server will be available Livy; the "Route" manifest is used if Red Hat OpenShift is used as the Kubernetes distribution, otherwise the corresponding Ingress or Service manifest of type NodePort is used):
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
After its application and successful launch of the pod, the Livy graphical interface is available at the link: http: // {livy-url} / ui. With Livy, we can publish our Spark task using a REST request, for example from Postman. An example of a collection with requests is presented below (in the "args" array, configuration arguments can be passed with the variables required for the task being launched):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar\", \n\t\"className\": \"org.apache.spark.examples.SparkPi\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-1\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t}\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"hdfs://{host}:{port}/{path-to-file-on-hdfs}\", \n\t\"className\": \"{class-name}\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-2\",\n\t\"proxyUser\": \"0\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t},\n\t\"args\": [\n\t\t\"HADOOP_CONF_DIR=/opt/spark/hadoop-conf\",\n\t\t\"MASTER=k8s://https://kubernetes.default.svc:8443\"\n\t]\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
Let's execute the first request from the collection, go to the OKD interface and check that the task has been successfully launched - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods. In this case, a session will appear in the Livy interface (http: // {livy-url} / ui), within which, using the Livy API or a graphical interface, you can track the progress of the task and study the session logs.
Now let's show how Livy works. To do this, let's examine the logs of the Livy container inside the pod with the Livy server - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods / {livy-pod-name}? Tab = logs. From them you can see that when you call the Livy REST API in a container named "livy", a spark-submit is executed, similar to the one we used above (here {livy-pod-name} is the name of the created pod with the Livy server). The collection also provides a second request that allows you to run tasks with remote hosting of the Spark executable using the Livy server.
Third use case - Spark Operator
Now that the task has been tested, the question arises of running it regularly. The native way to regularly run tasks in the Kubernetes cluster is the CronJob entity and you can use it, but at the moment, the use of operators to control applications in Kubernetes is very popular, and for Spark there is a fairly mature operator, which, among other things, is used in Enterprise-level solutions (e.g. Lightbend FastData Platform). We recommend using it - the current stable version of Spark (2.4.5) has quite limited options for configuring the launch of Spark tasks in Kubernetes, while in the next major version (3.0.0) full support for Kubernetes is announced, but its release date remains unknown. Spark Operator compensates for this shortcoming by adding important configuration options (for example,mounting ConfigMap with the configuration of access to Hadoop in Spark pods) and the ability to regularly run the task on a schedule.
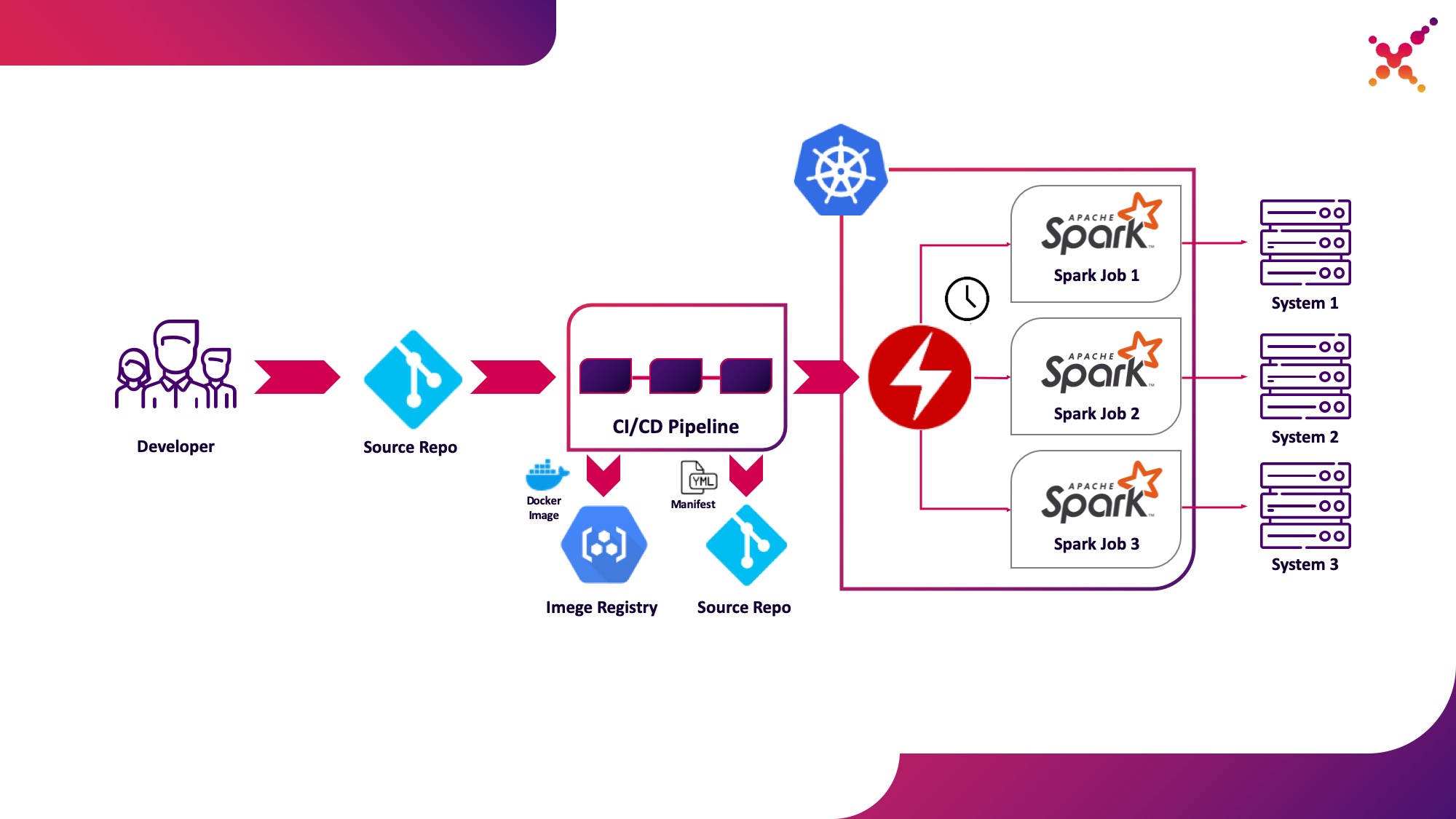
Let's highlight it as the third use case - regularly running Spark tasks on a Kubernetes cluster in a production loop.
Spark Operator is open source and is developed as part of the Google Cloud Platform - github.com/GoogleCloudPlatform/spark-on-k8s-operator . Its installation can be done in 3 ways:
- As part of the Lightbend FastData Platform / Cloudflow installation;
- With Helm:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator
- (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). — Cloudflow API v1beta1. , Spark Git API, , «v1beta1-0.9.0-2.4.0». CRD, «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
If the operator is installed correctly, an active pod with the Spark operator will appear in the corresponding project (for example, cloudflow-fdp-sparkoperator in the Cloudflow space for installing Cloudflow) and the corresponding Kubernetes resource type named "sparkapplications" will appear. You can examine the available Spark applications with the following command:
oc get sparkapplications -n {project}
To run tasks with Spark Operator, you need to do 3 things:
- create a Docker image that includes all the required libraries, as well as configuration and executable files. In the target picture, this is an image created at the CI / CD stage and tested on a test cluster;
- publish the Docker image to the registry accessible from the Kubernetes cluster;
- «SparkApplication» . (, github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/v1beta1-0.9.0-2.4.0/examples/spark-pi.yaml). :
- «apiVersion» API, ;
- «metadata.namespace» , ;
- «spec.image» Docker ;
- «spec.mainClass» Spark, ;
- «spec.mainApplicationFile» jar ;
- the dictionary "spec.sparkVersion" must indicate the version of Spark used;
- the "spec.driver.serviceAccount" dictionary must contain a service account within the appropriate Kubernetes namespace that will be used to launch the application;
- the dictionary "spec.executor" should indicate the amount of resources allocated to the application;
- the "spec.volumeMounts" dictionary must specify the local directory in which the local Spark task files will be created.
An example of generating a manifest (here {spark-service-account} is a service account inside the Kubernetes cluster for running Spark tasks):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
This manifest specifies a service account for which, prior to publishing the manifest, you need to create the necessary role bindings that provide the necessary access rights for the Spark application to interact with the Kubernetes API (if needed). In our case, the application needs the rights to create Pods. Let's create the required role binding:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
It is also worth noting that the specification of this manifest can specify the "hadoopConfigMap" parameter, which allows you to specify a ConfigMap with a Hadoop configuration without having to first place the corresponding file in the Docker image. It is also suitable for regularly launching tasks - using the "schedule" parameter, you can specify the launch schedule for this task.
After that, we save our manifest to spark-pi.yaml file and apply it to our Kubernetes cluster:
oc apply -f spark-pi.yaml
This will create an object of type "sparkapplications":
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
This will create a pod with an application, the status of which will be displayed in the created "sparkapplications". It can be viewed with the following command:
oc get sparkapplications spark-pi -o yaml -n {project}
Upon completion of the task, the POD will transition to the "Completed" status, which will also be updated to "sparkapplications". Application logs can be viewed in a browser or using the following command (here {sparkapplications-pod-name} is the name of the pod of the running task):
oc logs {sparkapplications-pod-name} -n {project}
Spark tasks can also be managed using the specialized sparkctl utility. To install it, we clone the repository with its source code, install Go and build this utility:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
Let's examine the list of running Spark tasks:
sparkctl list -n {project}
Let's create a description for the Spark task:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Let's run the described task using sparkctl:
sparkctl create spark-app.yaml -n {project}
Let's examine the list of running Spark tasks:
sparkctl list -n {project}
Let's examine the list of events of the started Spark task:
sparkctl event spark-pi -n {project} -f
Let's examine the status of the running Spark task:
sparkctl status spark-pi -n {project}
In conclusion, I would like to consider the discovered disadvantages of operating the current stable version of Spark (2.4.5) in Kubernetes:
- , , — Data Locality. YARN , , ( ). Spark , , , . Kubernetes , . , , , , Spark . , Kubernetes (, Alluxio), Kubernetes.
- — . , Spark , Kerberos ( 3.0.0, ), Spark (https://spark.apache.org/docs/2.4.5/security.html) YARN, Mesos Standalone Cluster. , Spark, — , , . root, , UID, ( PodSecurityPolicies ). Docker, Spark , .
- Running Spark tasks with Kubernetes is still officially in experimental mode, and there may be significant changes in the artifacts used (config files, Docker base images, and startup scripts) in the future. Indeed, when preparing the material, versions 2.3.0 and 2.4.5 were tested, the behavior was significantly different.
We will wait for updates - a fresh version of Spark (3.0.0) has recently been released, which brought tangible changes to the work of Spark on Kubernetes, but retained the experimental status of support for this resource manager. Perhaps the next updates will really make it possible to fully recommend abandoning YARN and running Spark tasks on Kubernetes without fearing for the security of your system and without the need to independently refine functional components.
Fin.