
According to a well-known joke, all memoirs in bookstores should be located in the "Science Fiction" section. But in my case, this is true! A long time ago,
3D Talking Heads - This is a tongue-sticking and winking bronze bust of Max Planck; a monkey that copies your facial expressions in real time; this is a 3D model of the quite recognizable head of the vice president of Intel, created completely automatically from video with his participation, and much more ... But first things first.
Synthetic video: MPEG-4 compatible 3D Talking Heads is the full name of the project carried out at Intel's Nizhny Novgorod Research and Development Center in 2000-2003. The development was a set of three main technologies that can be used both together and separately in many applications related to the creation and animation of synthetic three-dimensional speaking characters.
- Automatic recognition and tracking of facial expressions and movements of the human head in the video sequence. At the same time, not only the angles of rotation and tilt of the head in all planes are assessed, but also the external and internal contours of the lips and teeth during conversation, the position of the eyebrows, the degree of eye coverage and even the direction of gaze.
- Automatic animation in real time of almost arbitrary three-dimensional models of heads in accordance with the animation parameters obtained using the recognition and tracking algorithms from the first point as well as from any other sources.
- Automatic creation of a photorealistic 3D model of a specific person's head using either two prototype photos (front and side views), or a video sequence in which a person turns his head from one shoulder to another.
And another bonus - technology, or rather, some tricks of realistic rendering of "talking heads" in real time, taking into account the limitations of hardware performance and software capabilities that existed in the early 2000s.
And the link between these three and a half points, as well as the link to Intel, are four letters and one number: MPEG-4.
MPEG-4
Few people know that the MPEG-4 standard, which appeared in 1998, in addition to coding ordinary, real video and audio streams, provides for the coding of information about synthetic objects and their animation - the so-called synthetic video. One of these objects is a human face, more precisely, a head defined as a triangulated surface - a mesh in 3D space. MPEG-4 defines 84 special points on a person's face - Feature Points (FP): corners and midpoints of lips, eyes, eyebrows, nose tip, etc.
Facial Animation Parameters (FAP) are applied to these special points (or to the entire model as a whole in the case of turns and tilts), describing the change in the position and facial expression in comparison with the neutral state.
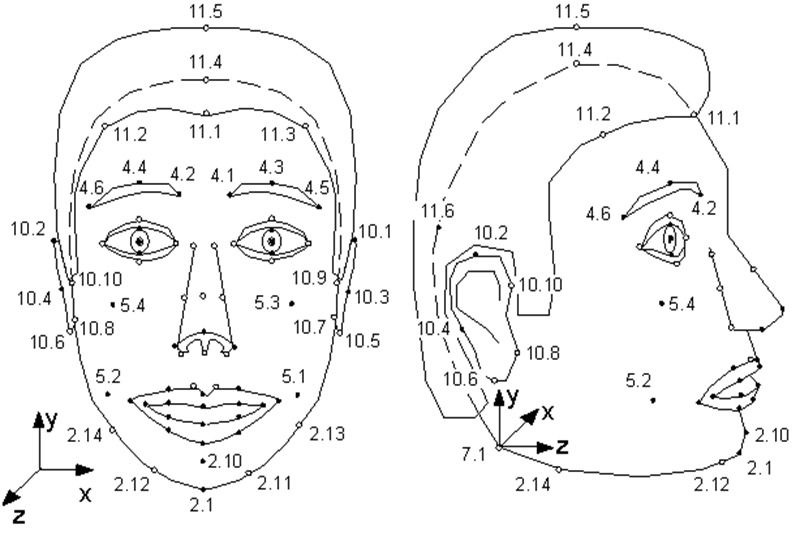
Illustration from the MPEG-4 specification. Singular points of the model. As you can see, the model can sniff and wiggle her ears.
That is, the description of each frame of synthetic video showing a speaking character looks like a small set of parameters by which the MPEG-4 decoder must animate the model.
Which model? MPEG-4 has two options. Either the model is created by the encoder and transmitted to the decoder once at the beginning of the sequence, or the decoder has its own proprietary model, which is used in the animation.
At the same time, the only MPEG-4 requirements for the model: storage in VRML-format and the presence of special points. That is, a model can serve as a photorealistic copy of a person whose FAP is used for animation, as well as a model of any other person, and even a talking kettle - the main thing is that he, in addition to a nose, has a mouth and eyes.

One of our MPEG-4 compatible models is the most smiling.
Besides the main object "face", MPEG-4 describes independent objects "upper jaw", "lower jaw", "tongue", "eyes", on which special points are also set. But if some model does not have these objects, then the corresponding FAPs are simply not used by the decoder.

- Model, model, why do you have such big eyes and teeth? - To better animate yourself!
Where do personalized animation models come from? How do I get FAP? And finally, how to implement realistic animation and rendering based on these FAPs? MPEG-4 does not give any answers to all these questions - just like any video compression standard does not say anything about the shooting process and the content of the films it encodes.
How far has progress come? Until unprecedented miracles!
Of course, both the model and animation can be created manually by professional artists, spending dozens of hours on it and receiving tens of hundreds of dollars. But this significantly narrows the scope of the technology, making it inapplicable on an industrial scale. And there are many potential uses for the technology, which actually compresses high-definition video frames to several bytes (oh, it's a pity that not any video). First of all, networking - games, education and communication (video conferencing) using synthetic characters.
Such applications were especially relevant 20 years ago, when the Internet was still accessed using modems, and the gigabit unlimited Internet seemed to be something like teleportation. But, as life shows, in 2020, the bandwidth of Internet channels in many cases is still a problem. And even if there is no such problem, say, we are talking about local use, synthetic characters are capable of a lot. For example, "resurrect" in a film a famous actor of the last century, or give an opportunity to look into the eyes of the now popular and still disembodied voice assistants. But first, the process of transition from a real video of a speaking person to a synthetic one should become automatic, or at least, with minimal human participation.
This is exactly what was implemented in Nizhny Novgorod Intel. The idea arose first as part of the implementation of the MPEG Processing Library, developed at one time by Intel, and then grew not just into a full-fledged spin-off, but into a real fantastic blockbuster.
Moreover, completely "made in Russia" - this project, it seems, was the only one for the entire existence of Russian Intel, there was no curator in Intel USA. Justin Ratner (head of the research division of Intel Labs) liked the idea during his visit to Nizhny Novgorod, and he gave the go-ahead to

Synthetic Valery Fedorovich Kuryakin, producer, director, scriptwriter, and in some places the stuntman of the project - at that time the head of the Intel development group.
First, the combination of such different technologies in one small project, on which only three to seven people worked at the same time, was fantastic. In those years, at least a dozen companies already existed in the world that were engaged in both face recognition and tracking, and the creation and animation of "talking heads". All of them, of course, had achievements in some areas: some had excellent model quality, some showed very realistic animations, some were successful in recognition and tracking. But not a single company has been able to offer the entire set of technologies that allows you to completely automatically create a synthetic video in which a model, very similar to its prototype, copies well its facial expressions and movements.
The Intel 3D Talking Heads project was the first and at that time the only implementation of a full cycle of video communication based on all the elements of the MPEG-4 synthetic profile.

Conveyor of the project for the production of synthetic clones of the 2003 model
. Secondly, the combination of the hardware that existed at that time and the technological solutions implemented in the project, as well as plans for their use, was fantastic. So, at the start of the project, I had a Nokia 3310 in my pocket, there was a Pentium III-500MHz on my desktop, and algorithms that were especially critical to performance for real-time work were tested on a Pentium 4-1.7GHz server with 128 Mb of RAM.
At the same time, we hoped that soon our models would work in mobile devices, and the quality would be no worse than that of the heroes of the photorealistic computer animated film " Final Fantasy " released at that time (2001) .

$ 137 million was the cost for a film created on a render farm of ~ 1000 Pentium III computers. Poster from www.thefinalfantasy.com
But let's see what happened with us.
Face recognition and tracking, FAP acquisition.
This technology was presented in two versions:
- real-time mode (25 frames per second on the already mentioned Pentium 4-1.7GHz processor), when a person directly standing in front of a video camera connected to a computer is tracked;
- ( 1 ), .
At the same time, the dynamics of changes in the position / state of the human face was monitored in real time - we could approximately estimate the angles of rotation and tilt of the head in all planes, the approximate degree of opening and stretching of the mouth and raising of eyebrows, and recognize blinking. For some applications, such a rough estimate is sufficient, but if you need to accurately track a person's facial expressions, then more complex algorithms are needed, which means slower ones.
In offline mode, our technology made it possible to assess not only the position of the head as a whole, but absolutely accurately recognize and track the outer and inner contours of the lips and teeth during a conversation, the position of the eyebrows, the degree of eye coverage, and even the displacement of the pupils - the direction of the gaze.
For recognition and tracking, a combination of well-known computer vision algorithms was used, some of which had already been implemented in the newly released OpenCV library - for example, Optical Flow, as well as our own original methods based on a priori knowledge of the shape of the corresponding objects. In particular - on our improved version of the method of deformable templates , for which the project participants received a patent .
The technology was implemented in the form of a library of functions that received video frames with a human face as input and output the corresponding FAPs.
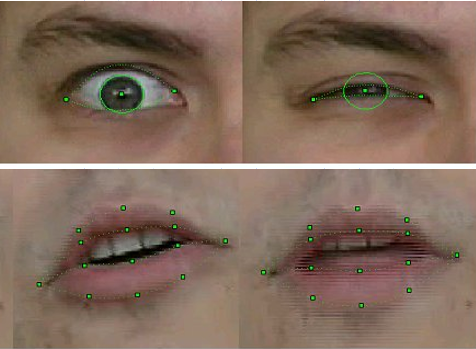
Quality of recognition and tracking FP sample 2003
The technology was imperfect, of course. Recognition and tracking failed if the person in the frame had a mustache, glasses or deep wrinkles. But over three years of work, the quality has improved significantly. If in the first versions for motion recognition models when shooting a video had to stick special marks on the corresponding FP points of the face - white paper circles obtained with an office punch, then in the final of the project nothing of the kind was required, of course. Moreover, we managed to quite steadily track the position of the teeth and the direction of gaze - and this is at the resolution of video from webcams of that time, where such details were hardly distinguishable!

This is not chickenpox, but footage from the "childhood" of recognition technology. Intel Principle Engineer, and at that time - novice Intel employee Alexander Bovyrin teaches a synthetic model to read poetry
Animation
As has been said many times, the animation of a model in MPEG-4 is completely determined by the FAP. And everything would be simple, if not for a couple of problems.
First, the fact that the FAPs from the video sequences are extracted in 2D, and the model is 3D, and it is required to somehow complete the third coordinate. That is, a welcoming smile in profile (and users should be able to see this profile, otherwise there is little sense in 3D) should not turn into an ominous grin.
Secondly, as it was also said, FAPs describe the movement of singular points, of which there are about eighty in the model, while at least a somewhat realistic model as a whole consists of several thousand vertices (in our case, from four to eight thousand), and algorithms are needed that calculate the displacement of all other points in the model based on the FP displacements.
That is, it is clear that when the head is turned at an equal angle, all points will turn, but when smiling, even if it is up to the ears, the “indignation” from the shift of the corner of the mouth should gradually fade away and move the cheek, but not the ears. Moreover, it should happen automatically and realistically for any model with any mouth width and mesh geometry around it. To solve these problems, animation algorithms were created in the project. They were based on a pseudomuscular model, which simply describes the muscles that control facial expressions.
And then, for each model and each FAP, the "zone of influence" was preliminarily automatically determined - the vertices involved in the corresponding action, the movements of which were calculated taking into account anatomy and geometry - maintaining the smoothness and connectivity of the surface. That is, the animation consisted of two parts - preliminary, performed offline, where certain coefficients for mesh vertices were created and entered into the table, and online, where, taking into account the data from the table, real-time animation was applied to the model.

Smiling is not easy for a 3D model and its creators
Creation of a 3D model of a specific person.
In the general case, the task of reconstructing a three-dimensional object from its two-dimensional images is very difficult. That is, the algorithms for solving it have long been known to mankind, but in practice, due to many factors, the result is far from the desired one. And this is especially noticeable in the case of reconstruction of the shape of a person's face - here you can recall our first models with eyes in the shape of an eight (the shadow from the eyelashes in the original photos was unsuccessful) or a slight bifurcation of the nose (the reason cannot be restored after years).
But in the case of MPEG-4 talking heads, the task is greatly simplified, because the set of human facial features (nose, mouth, eyes, etc.) is the same for all people, and the external differences by which we all (and computer vision programs) distinguish people from each other "geometric" - the size / proportions and location of these features and "texture" - colors and relief. Therefore, one of the profiles of synthetic MPEG-4 video, calibration, which was implemented in the project, assumes that the decoder has a generalized model of an “abstract person” that is personalized for a specific person using a photo or video sequence.
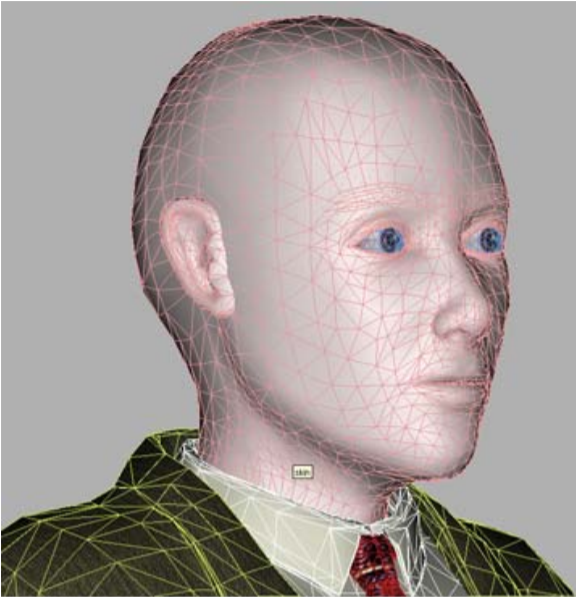
Our "spherical man in a vacuum" - a model for personalization
That is, global and local deformations of the 3D mesh occur to match the proportions of the prototype's facial features highlighted in its photo / video, after which the prototype's "texture" is applied to the model - that is, the texture created from the same input images. The result is a synthetic model. This is done once for each model, of course offline, and of course, not so easy.
First of all, registration or rectification of input images is required - bringing them to one coordinate system that coincides with the coordinate system of the 3D model. Further, it is necessary to detect special points on the input images, and, based on their location, deform the 3D model, for example, using the method of radial basis functions, after which, using panorama stitching algorithms , generate a texture from two or more input images, that is, "mix" them in the correct proportion to obtain maximum visual information, as well as compensate for the difference in lighting and tone, which is always present even in photos taken with the same camera settings (which is not always the case), and very noticeable when combining these photos.

This is not a still from horror movies, but the texture of a 3D model by Pat Gelsinger , created with his permission when the project was demonstrated at the Intel Developer Forum in 2003.
The initial version of the technology for personalizing the model based on two photos was implemented by the project participants themselves at Intel. But upon reaching a certain level of quality and realizing the limitations of their capabilities, it was decided to transfer this part of the work to the research group of Moscow State University, which had experience in this area. The result of the work of researchers from Moscow State University under the leadership of Denis Ivanov was the application "Head Calibration Environment", which performed all the above operations to create a personalized model of a person from his photo in full face and profile.
The only subtle point is that the application was not integrated with the face recognition unit described above, which was developed in our project, so the special points in the photo necessary for the algorithms to work had to be marked manually. Of course, not all 84, but only the main ones, and given that the application had an appropriate user interface, this operation took only a few seconds.
Also, a fully automatic version of the model reconstruction from a video sequence was implemented, in which a person turns his head from one shoulder to another. But, as you might guess, the quality of the texture extracted from the video was significantly worse than the texture created from photographs of digital cameras of that time with a resolution of ~ 4K (3-5 megapixels), which means that the resulting model looked less attractive. Therefore, there was also an intermediate version using several photos of different head rotation angles.

The top row is virtual people, the bottom row is real.
How good was the achieved result? The quality of the resulting model should be assessed not in statics, but directly on the synthetic video by its similarity to the corresponding video of the original. But the terms “similar and not similar” are not mathematical, they depend on the perception of a particular person, and it is difficult to understand how our synthetic model and its animation differ from the prototype. Some people like it, some don't. But the result of three years of work was that when demonstrating the results at various exhibitions, the audience had to explain in which window the real video was in front of them, and in which - the synthetic one.
Visualization.
To demonstrate the results of all the above technologies, a special MPEG-4 synthetic video player was created. The player received as input a VRML file with a model, a stream (or file) with FAP, as well as streams (files) with real video and audio for synchronized display with synthetic video with support for the "picture in picture" mode. When demonstrating a synthetic video, the user was given the opportunity to zoom in on the model, as well as look at it from all sides, simply by turning the mouse at an arbitrary angle.

Although the player was written for Windows, but taking into account possible porting in the future to other OSs, including mobile ones. Therefore, the "classic" OpenGL 1.1 without any extensions was chosen as the 3D library.
At the same time, the player not only showed the model, but also tried to improve it, but not to retouch it, as is now customary with photo models, but, on the contrary, to make it as realistic as possible. Namely, staying within the framework of the simplest Phong lighting and having no shaders, but having strict performance requirements, the player's rendering unit automatically created synthetic models: mimic wrinkles, eyelashes capable of realistically narrowing and dilating pupils; put glasses of a suitable size on the model; and also using the simplest ray tracing, he calculated the lighting (shading) of the tongue and teeth when speaking.
Of course, now such methods are no longer relevant, but remembering them is quite interesting. So, for the synthesis of mimic wrinkles, that is, small bends of the skin relief on the face, visible during the contraction of the facial muscles, the relatively large sizes of the triangles of the model mesh did not allow creating real folds. Therefore, a kind of bump mapping technology was applied - normal mapping. Instead of changing the geometry of the model, the direction of the normals to the surface in the right places changed, and the dependence of the diffuse component of illumination at each point on the normal created the desired effect.

This is synthetic realism.
But the player didn't stop there. For the convenience of using technologies and transferring them to the outside world, the Intel Facial Animation Library object library was created, containing functions for animation (3D transformation) and visualization of the model, so that anyone who wants (and has a FAP source) calls several functions - "Create Scene", " CreateActor ”,“ Animate ”could animate and show his model in his application.
Outcome
What did participation in this project give me personally? Of course, the opportunity to collaborate with wonderful people on interesting technologies. They took me into the project for my knowledge of methods and libraries for rendering 3D models and optimizing performance for x86. But, naturally, it was not possible to limit ourselves to 3D, so we had to go to other dimensions. To write a player, it was necessary to deal with VRML parsing (there were no ready-made libraries for this purpose), to master native work with streams in Windows, ensuring the joint work of several threads with synchronization 25 times per second, not forgetting about user interaction, and even to think over and implement interface. Later, this list was supplemented by participation in the improvement of face tracking algorithms. And the need to constantly integrate and simply combine components written by other team members with the player,and also presenting the project to the outside world greatly improved my communication and coordination skills.
What did Intel's participation in this project give? As a result, our team has created a product that can serve as a good test and demonstration of the capabilities of Intel platforms and products. Moreover, both hardware - CPU and GPU, and software - our heads (both real and synthetic) have contributed to the improvement of the OpenCV library.
In addition, we can safely say that the project left a visible mark in history - as a result of its work, its participants wrote articles and presented reports at specialized conferences on computer vision and computer graphics, Russian ( GraphiCon ), and international.
And 3D Talking Heads demo applications have been shown by Intel at dozens of trade shows, forums and congresses around the world.
In the intervening time, technology, of course, has advanced a lot, making it easier to automatically create and animate synthetic characters. There were Intel Real Sense chamber depth definition, and neural networks based on large data learned how to generate realistic images of people, even non-existent.
But, nevertheless, the developments of the 3D Talking Heads project, posted in the public domain, continue to be viewed until now.
Look at our young, almost twenty-year-old, synthetic MPEG-4 speaker and you: