I decided to check the birthday paradox using data that is available from VK.
What is the birthday paradox?
Try to answer the question: How many people in a room are needed for two people to have the same birthday with a probability of 0.5? (date and month). The birthday paradox answers this question.
In order to solve the problem, it is worth highlighting several prerequisites:
- The model will not have February 29 => 365 days a year in the model
- Each of the 365 days is equally probable.
Of course, it is not entirely realistic that birthdays are equally probable - there are seasonal effects that affect the dates of birth of children, I think you yourself can guess what ...
Most people intuitively answer the question of the problem: 180. Looks logical, 180 people are needed in order to have probability of 0.5 identical birthdays (365 days in total). Everyone who has never heard of the birthday paradox is about this intuition. The correct answer is actually much less than 180, and even 150, and even 100: 23.
At least 1 matching birthday is required - so I can find the probability that there are no matching birthdays:...
The idea is this: I take the first person and remember his birthday, then the second and calculate the probability that his birthday does not coincide with the birthday of the first; further than the third and I calculate the probability that his birthday does not coincide with the birthdays of the first and second.
Solving the equation, it turns out that 23 people are needed and the probability of coinciding birthdays will be 0.5073, with 100 people, the probability is 0.9999.
Let's see the paradox on VK data?
In theory, with 23 people, the probability of coinciding birthdays is 0.5073, with 50 people 0.97, and with 100 0.99. Let's check it through the VK API.
1. I choose a large community in VK. I decided to take the MDK group on Vkontakte ...
First, I create a csv file with the columns that I need.
with open('vk_data.csv', 'w') as new_file:
# csv
fieldnames = ['id', 'bdate', 'bmonth', 'byear', 'dandm']
csv_writer = csv.DictWriter(new_file, fieldnames=fieldnames, delimiter=',')
csv_writer.writeheader()
newDict = dict()I log in to VK via the API and set the public I need
vk_session = vk_api.VkApi('username', 'password')
vk_session.auth()
vk = vk_session.get_api()
vk_group = vk.groups.getMembers(group_id = 'mudakoff', fields = 'bdate')
We start parsing VKontakte, their API allows you to parse only 1000 users, so I create a loop.
for i in range(0, 20):
vk_group = vk.groups.getMembers(group_id = 'mudakoff', offset = 1000 * i, fields = 'bdate')
for k in range(0, 1000):
try:
new_file.write(str(vk_group['items'][k]["id"]) + ',' + str(vk_group['items'][k]["bdate"]).replace('.', ','))
new_file.write('\n')
except:
passIn theory, we assumed that birthdays are equally probable, but what happens in practice? I will build a histogram of birthdays.
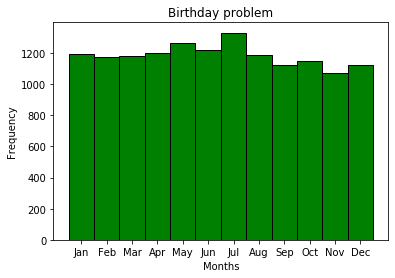
Birthdays by month are not equiprobable events, which is generally quite logical - this is just a prerequisite for solving the birthday problem. Obviously, there will be different seasonal events, for different locations. For some reason, July is the most popular month for the birthday of MDK subscribers.
I will empirically estimate the probability that in a group of 50 arbitrary people there are at least two with the same birthday. To do this, I wrote a cycle during which a sub-sample of 50 lines occurs from the table. For these 50 lines inside the condition, I checked the birthdays match. If it matched, then I remembered it in the counter variable, which I will subsequently divide by the cycle length to get the probability.
fifty = df["dandm"].sample(n = 50)
for i in range(0, 1000):
fifty = df["dandm"].sample(n = 50)
for j in fifty.duplicated():
if j == True:
counter = counter + 1
break
print(':', counter / 1000)The probability is obtained in the region of 0.97, which coincides with the theoretical data.
Output
It was interesting to see how theory relates to empiricism, and in this case the data confirm the theory. It should be noted that the result is representative, as the sample is large enough - 20,000 people.
Resources
- Harvard University. Birthday Problem, Properties of Probability | Statistics 110. URL: www.youtube.com/watch?v=LZ5Wergp_PA&t=150s . Accessed: 07/08/2020
- Birthday Problem. URL: en.wikipedia.org/wiki/Birthday_problem . Accessed: 07/08/2020>