 Hi, my name is Kostya Kardamanov, I work in the Yandex development technology department. I usually greet candidates with the same phrase for an interview. And today I would like to tell you how and why we conduct system design interviews with backend developers. I must say right away that this type of interview is not very applicable for front-end developers, mobile developers and ML-engineers, so we will not discuss these specialties here.
Hi, my name is Kostya Kardamanov, I work in the Yandex development technology department. I usually greet candidates with the same phrase for an interview. And today I would like to tell you how and why we conduct system design interviews with backend developers. I must say right away that this type of interview is not very applicable for front-end developers, mobile developers and ML-engineers, so we will not discuss these specialties here.
The technical level of a candidate is assessed by only two types of interviews: sections with a codeand a section of computer systems design. We assign the first type to all applicants, regardless of their level, but candidates who apply for the position of senior specialist need to check not only the ability to write effective and workable code, but also the ability to develop complex systems in general.
What is information systems design
The main goal of any IT company is to produce services that solve user problems. We must be able to collect the elements of the system into a single mechanism that will effectively fulfill the goal, and if the first type of interviews is aimed primarily at checking the required minimum, then the interview about systems design checks the adequacy of the candidate's skills in achieving the final goal. To a user far from IT, the principles and structure of systems may seem infinitely complex, but we, their developers, must have (not necessarily detailed) understanding of the principles of functioning and the role of each component.
An experienced reader can say that the world is full of paid and free solutions, from which I can assemble a system as from the parts of a designer, why should I understand the structure of these parts? If I need a database, I will take PostgreSQL and store my data in it, I use nginx to process HTTPS requests, and I implement the service on a popular framework for writing HTTP services in my favorite programming language. Probably, this will be a great solution if you are going to write a service for a small audience, but the services of a large company are usually a little more complex and heavily loaded.
For example, when choosing a database, you have to decide whether you need a classic relational DBMS or a noSQL solution? Perhaps a simpler key-value storage will be enough for the system: you will not have to spend time on setting up, and the response time of such a system will be several times less, which will have a positive effect on the speed of the application. What specific database should you choose if KVS is enough for you? Aerospike? Redis? Couchbase? Memcached? Maybe you need to consider HBase as well in this class? You need to be aware of the existence of all these types of storage, their main differences and areas of application in order to be able to make intelligent choices.
When choosing a specific component, you should also have an idea of its structure, main advantages and principles of operation. Otherwise, it may turn out that Memcached is used to store persistent data, and in Redis, in the future (after a few years of the project's life), it will be necessary to store several terabytes of relatively rarely changed data - the properties and guarantees provided by the system are more important to us than a specific name. On the other hand, the system should be minimally complex and cheap to develop and operate. If you can use a ready-made solution to perform the desired function, then it would be unwise to spend resources on developing your own alternative - in each case, you must approach the choice carefully and deliberately.
In the realities of the activities of companies of the scale of Yandex, it usually turns out that all the solutions used very quickly cease to fit on one server, and, given the requirements of high availability, they are necessarily located in several locations. And once the system becomes distributed, the complexity of its design and implementation increases by orders of magnitude. On Habré there is an informative story about how much needs to be taken into account when implementing distributed systems.
A good designer must represent the system in four dimensions: not only understand the purpose and interrelationship of its components, evaluate the system's ability to perform specified functions and withstand design loads right now, but also imagine its development over time for several years ahead - how easily components can be replaced when need, how the requirements for functionality and data volume may change in the future, what part of the system will need to be upgraded, what can become a bottleneck (that is, which part is most sensitive to the load) and what can cause a failure.
The ability to maintain the system's performance in abnormal conditions, thinking through failure scenarios and measures to prevent them is also the responsibility of the developer. Remember at least misconceptions about distributed computing - judgments formed more than 20 years ago have not become less relevant. Operating and ensuring high availability of services is now a separate large area of expertise known as SRE . Like TDD, which has become the de facto standard in the development of modules and components, project metrics are becoming an incredibly important aspect in the design and operation of complex systems. They not only show the performance of the system at the moment, but allow you to adjust the development plans of the system based on the conclusions from the retrospective analysis of these metrics. In general, the metrics first approach has been used in system design for a long time - first you need to define or build the metric that you are improving, and only then start changing the system.
In addition to all this, you must be able to clearly, clearly and reasonably express your opinion so that the developers in the team can understand and discuss it: the times are long gone when a person could single-handedly design and implement a system of the level of those currently being developed in large IT companies. This skill is needed by any developer applying for the role of an architect. Even if you are the only technical leader on a small project, and you do not need to coordinate changes with others, it is still important to explain the reasons and factors behind a particular decision to less experienced developers. Otherwise, how can they gain experience and develop qualitatively?
Programmers, developers, engineers and architects
There is no consensus on whether the words "programmer" and "developer" can be considered synonymous. I am among those who see a significant difference. The first term is closer to the word "coder" and does not seem to imply an integrated approach to creating projects in the form described above. And the developer is obliged to think about all of the above. I would even say that it should be a development engineer, because engineering is an area of activity related to the application of research results in practice. By the way, here is a very interesting interpretation of developer job titles from valyard...
At the same time, the position of an architect is rarely found in Yandex (as well as projectswith a duration of implementation of 139+ years), and the design of the main services is the result of the collective work of different specialists. Both inexperienced engineers and experts alike, albeit to varying degrees, contribute to the development of projects. On the other hand, we do not need simple executors typing code "under dictation": it is easier and faster to implement the idea on our own, since modern development tools have greatly simplified this task. That is, we are all developers. So how is one developer different from another? Why are some invited to take additional tests, while others are not? From the point of view of the impact of the decisions of the engineer on the project, specialists can be divided into three categories: junior, experienced and senior developer.
The first category includes those who have recently started their careers in IT, already have technical knowledge, but the lack of experience and additional skills does not allow them to implement complex solutions. Experienced developers can perform complex tasks, have a good understanding of the system architecture as a whole, and can make decisions about the development of components. Senior developers are people whose activities significantly affect the project not only by the volume of changes made, but also by their quality, which is measured according to the criteria listed above. Such a person can be called an architect too.
Since the volume of changes made to the system by senior developers is very large, there is more and the risk of potential problems. When considering candidates for such positions, we want to make sure that the person is able to cope with the responsibilities assigned to him.
Many believe that the engineering position has a "ceiling": one day, for further professional growth, you need to start managing people and become a leader. This is not the case with us - in many teams there are people who have become de jure or de facto technical leaders. Engineers in our company have the same career opportunities and, accordingly, material growth opportunities with managers. A senior developer at some point becomes an expert, his decisions begin to influence, if not the entire company as a whole, then certainly a significant part of it. And the number of such people in the company is proportional to the number of managers with a similar level of responsibility.
Process
So, we figured out the subject area and terminology. How do senior developer interviews go? In a very limited period of time, it is required to assess many of the candidate's competencies. To do this, we give an assignment for the development of a complex, high-load and fault-tolerant system. As a basis for the task, we take a real-life system - for example, Yandex Go. In the process of solving the task, you will have to talk a lot, but we expect that the candidate will be the main participant in the conversation - the interviewer in technical interviews plays a secondary role and takes the initiative only in extreme cases.
The basic plan for a system design interview is simple enough, as is the list of criteria by which the solution to the problem will be judged. Try to remember them and stick to them during the conversation.
,
, URL. Facebook . RPS, , .
: , ,
In real life, system design decisions often occur in a data-constrained environment. I have already talked about how important project metrics are for its proper development. Of course, analysts and product managers will try to provide you with the most complete information, but this may not be enough. If the input is not enough, you can and should put forward sound hypotheses based on the information that you already know: for example, how many people live on the planet and how many of them use the Internet.
Determine the key functional requirements for the future system: what properties it should have in the database, and which ones can be sacrificed, what are the requirements for response time, availability. I recommend that you write down the received requests so that you do not miss any of them during the conversation.
:
— ?
— 500 . RPS .
— HTTP HTTPS?
— , HTTPS.
— ?
— — , — .
— ?
— , .
— ?
— 150 95% .
— ?
— .
— ?
— ; .
— ?
— .
— ?
— .
— ?
— , — ( ).
, API,
When the requirements for the system are ready, you need to understand how it will process data - what users send to the system and what they receive in response. Having received answers to these questions, we will be able to understand how the program interface of the system should look like. In describing data flows, we will begin to define what core services and components the system should consist of, and API requirements will allow us to refine their characteristics. Try to write out the basic entities and signatures of the basic API methods - this will help you further describe the system and structure the solution.
In our example, there are several main functional blocks:
- (control plane)
API , . , API:
—
—
—
— ,
-, REST API — UI, API .
HTTP(S)- ID ,HTTP 302 Moved Permanently
.
, random. 32 , — 20 . alphanumerics , 36 , 6 4 . , 7 5 .
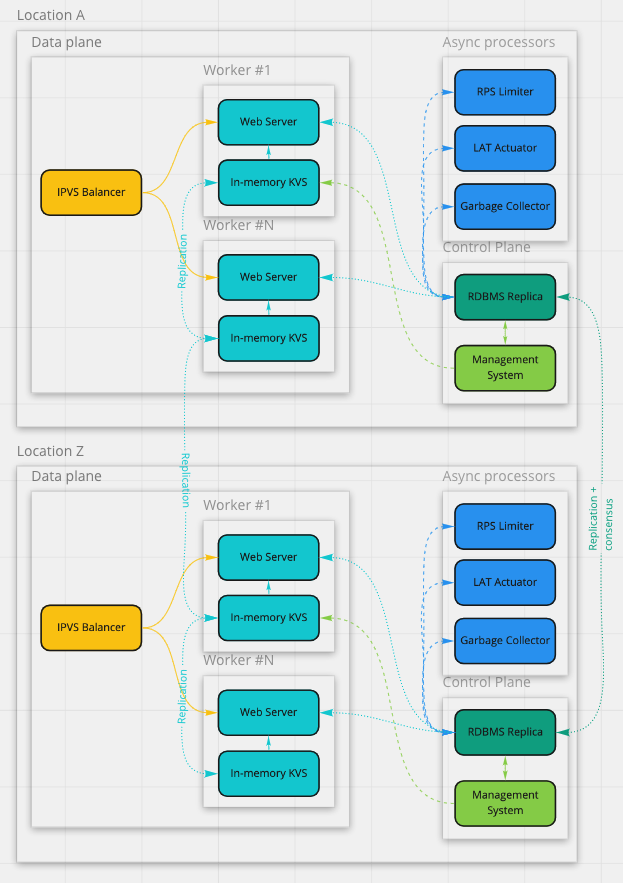
. ( 1-2 RPS), , , . KV-, . NoSQL-, (in-memory KV store).- (data plane)
HTTP- -, . . HTTP- DNS, L3- IPVS round robin health checks.
. RPS limiter', . , , : (snapshot) . : — - ( ). .
, . multiple producers single consumer. , KV store.
, ,
Once you have completed your top-level diagram, you can start adding details to it. For example, if a centralized storage is supposed in the system, the subtleties of the choice of which we have already described earlier, then you need to describe the conceptual model of the data stored in it. According to the detailed project diagram, it will be possible to determine the most loaded and performance-critical components that should be given increased attention from a development point of view - to think over which data structures and algorithms should be used in them.
That being said, try to keep the system balanced in terms of complexity. If you think that for some components you can use a standard solution or a well-known framework, suggest it - do not complicate the system unnecessarily.
At this stage, it may be necessary to write down the data storage structure or describe the proposed algorithm (at least in pseudocode) for the most complex component of the system.
For our example, we will describe the device and scheme of operation of each of the functional blocks that we defined in the previous step:
- (control plane)
— RPS , RESTful-. . IPVS- data plane: data plane , control plane .
- , (race condition).
.
CREATE TABLE Account ( account_id INTEGER NOT NULL PRIMARY KEY, login VARCHAR NOT NULL UNIQUE, type BOOLEAN NOT NULL )
— , , — .
CREATE TABLE Link ( link_id INTEGER NOT NULL PRIMARY KEY, account_id INTEGER NOT NULL REFERENCES Account, ttl INTEGER, created DATETIME NOT NULL, accessed DATETIME NOT NULL, url VARCHAR NOT NULL )
— , , — .
managed- , . — , . CPU. primary hot standby-.
Link
( //) KV store. KV store. — :
CREATE TABLE Oplog ( id INTEGER NOT NULL SERIAL PRIMARY KEY, link_id INTEGER NOT NULL, account_id INTEGER NOT NULL, optime DATETIME NOT NULL, url VARCHAR NOT NULL )
.
, : , . , , - . , . — (majority) KV store. KV store, , , .- (data plane)
- - :
- ID KV store URL
account_id
.account_id
. RPS limiter, . read-only-account_id -> RPS
, . — , . — . , ,HTTP 429 Too Many Requests
.- HTTP-. , , . , . , - — , .
account_id -> counter
RPS limiter . (set) .
- , KV store read-only- ,
link_id -> {url, account_id}
. 100 RPS , ( 100 ) CPU. , , .- secondary- KV store, , . (L1) LRU- -: KV store (L2) , L1-, .
- (LAT actuator)
, - KV store , . , ,UPDATE
,UPDATE Link SET accessed = now() WHERE link_id IN (...)
. ,SELECT ... FOR UPDATE
.- RPS limiter
— gRPC- , — . , , — . . :
— , .
— .
:
— . — .
— data plane, (, primary- ). , - , — .
— . , data plane, ( ).
: - , 100 , RPS limiter' . :
CREATE TABLE RPSLimit ( account_id INTEGER NOT NULL REFERENCES Account, balance SMALLINT NOT NULL, -- limit SMALLINT NOT NULL -- )
, , , . , . — , . : , (, protobuf), . , :
CREATE TABLE RPSLimitSnapshot ( data BYTEA NOT NULL )
RPS limiter' :
— . LAT actuator. , , .
— . (leaky bucket): , (balance
) ; ; (balance
limit
)account_id
. . , , burst budget — .
— , . .
, :
,
When the service schema becomes clear enough, you can proceed to assessing the required computing resources. If a component involves intensive calculations or processing a large amount of data, it is necessary to estimate the processor time spent on executing algorithms, the amount of RAM, data storage, and network bandwidth. Here you will definitely need to remember latency numbers every programmer should know... It may turn out that the computing power of modern servers will not be enough to accommodate one or more system components. Then you have to make a difficult decision - either change the basic algorithm / data structure, or go to horizontal scaling. The latter option usually appears to be more beneficial in the long run. But any solution has its own price, in this case you will have to pay with the complication of the system design and additional operating costs.
Let's carry out such an analysis for our example.
- (control plane)
, REST API , CPU ( ). CPU — , . , managed- primary- . .- (data plane)
— CPU: HTTP over SSL , plain HTTP. SSL handshakes , SSL session . , . ~20 . KV store, 100 RPS. KV store CPU , CPU, KV store . CPU-. . . , 25 « + KV store» ( ) .
. , . , 25 . . IPVS- 4 — , , ( ). 40 , — 43 . , .
:
- HTTP-. - 120 . , HTTP- 30 .
- :
— KV store localhost
—
— —
10 , .
, , , .
, : , , , ,
After making sure that the system is working, you can proceed to the final part of the main block of the conversation - operation.
First, describe how the system should be located topologically, how many data centers, CDNs will be required, how caching and balancing of requests will be arranged in such a topology.
Tell us how the system should survive the failures of single servers and entire data centers, with what metrics you can monitor its performance. You must have a plan of action in case you hit the main path of an assembly that contains a fatal error in one of the components or in the data; in case the standard load is exceeded by several times or even by orders of magnitude. Explain how to avoid denial of service in such a situation - what can be sacrificed for survival.
Describe how you intend to update the components of the system or the main repository, change the data schema; how to make sure that the next release does not contain problems in terms of component health or performance. In conclusion, recall the functional requirements for the system, written out at the very beginning of the conversation. Think about how you could further control them based on data coming from the system and external sources.
In relation to our problem, the following aspects can be discussed
We have already covered the main part about balancing queries above. Here you can additionally indicate that the load will be evenly distributed, since a simple round robin scheme is used at all balancing levels.
Failure scenarios
- IPVS-: , .
- - / KV store: . - . .
- secondary- : .
- primary- : , GET-.
- RPS limiter' : , .
- - :
— , . .
— IPVS- — , blacklist', .
— blacklist , .
— SSL- .
- :
— primary-
— secondary-
— KV store
— -
— IPVS-
— RPS limiter
—- (CPU, RAM, disk IO, network IO) .
- , .
- - . , .
- . , . SSD/NVMe-, , . . HDD . k- / .
, , , . , .
, k- -. . , .
If you have a little time left after the main part of the conversation, you can discuss something else. For example, the pros and cons of one of the proposed frameworks, bases, structures or algorithms, details of their device. Additional aspects of operation can be touched upon: monitoring and assessing the quality of the system from the point of view of users, localization and personalization of responses, testing circuits, rolling releases and continuous deployment, data versioning, fast data cuts for working under extreme loads, ways to find problems and debugging options in a running cluster.
Preparing for the interview
An interview, like any challenge, is a must to prepare if you want to increase your chances of success (otherwise why waste your time?). Even if you develop systems of this class every day, some of the moments may be forgotten; during your work, new systems and approaches to solving design problems could appear. So brush up on your knowledge. The preparation should start with a study of literature and reports on the design of real-life systems. You will find links to the necessary resources below.
When you feel ready for the interview, you can try practicing. Take a large piece of paper or a whiteboard and try to imagine the design of any complex system or service you know. It can be a data storage system, video hosting, search, a news feed from social networks, a messenger, an order processing system.
Try to think over its design according to the plan above. If possible, invite a familiar developer to listen to you. Even if he does not understand any part of the story, you will still find out how accessible and logical your description of the system is.
What materials can be used for preparation:
-
— — .
— — .
— Martin Kleppmann. Designing Data-Intensive Applications
— , , , — Site Reliability Engineering. Google -
, HighLoad++. -
The System Design Primer — . — , . - Courses
There are many different video courses available on the topic of System Design Interview. Unfortunately, most of them are paid, and the proposed solutions are often not the best. Therefore, I will not advise anything specific, whether to pass them or not - decide for yourself. They will not be able to guarantee or even significantly increase the likelihood of success. But, probably, they will add self-confidence to you.
A good theoretical background and a little practice in the field of systems design will definitely come in handy in your life and help you grow professionally. I wish you creative success.