Semantic succession recognition problem(textual entailment), or implications (natural language inference), in natural language texts consists in determining whether a part of the text (premise, antecedent) can be implied or contradict (or not contradict) another fragment of the text (consequence, consequent). While this issue is often considered an important test of comprehension in machine learning (ML) systems and has been deeply studied for simple texts, much less effort has gone into applying such models to structured data such as websites, tables, databases, etc. Nevertheless, the recognition of semantic succession is especially important when the contents of the table need to be accurately summarized and presented to the user, and it is important for such applications where high accuracy is required: in question-answer systems andvirtual assistants .
In the article “ Understanding tables with intermediate pre-training, ” published in EMNLP 2020 , the authors presented the first pre-training methods adapted for table analysis, allowing models to learn better, faster, and with less data. The authors build on their earlier TAPAS model , which was an extension of the bidirectional model based on the BERT Transformer with special embeddings for finding answers in tables. New TAPAS pre-training methods provide better metrics on multiple datasets including tables. In TabFact, for example, the gap between the results of the performance of this task by the model and the person is reduced by about 50%. The authors also systematically test methods for selecting appropriate inputs to improve efficiency, resulting in a fourfold increase in speed and memory reduction while retaining 92% of the results. All models for different tasks and sizes are released in the GitHub repository , where they can be tried out on a Colab laptop .
Semantic following
The semantic follow-up problem is more complex when applied to tabular data than to plain text. Consider, for example, a table from Wikipedia and a few sentences related to the table's content. Assessing whether a sentence follows or contradicts the data in the table may require looking at multiple columns and rows and possibly performing simple numerical calculations such as averaging, summing, differentiating, etc.
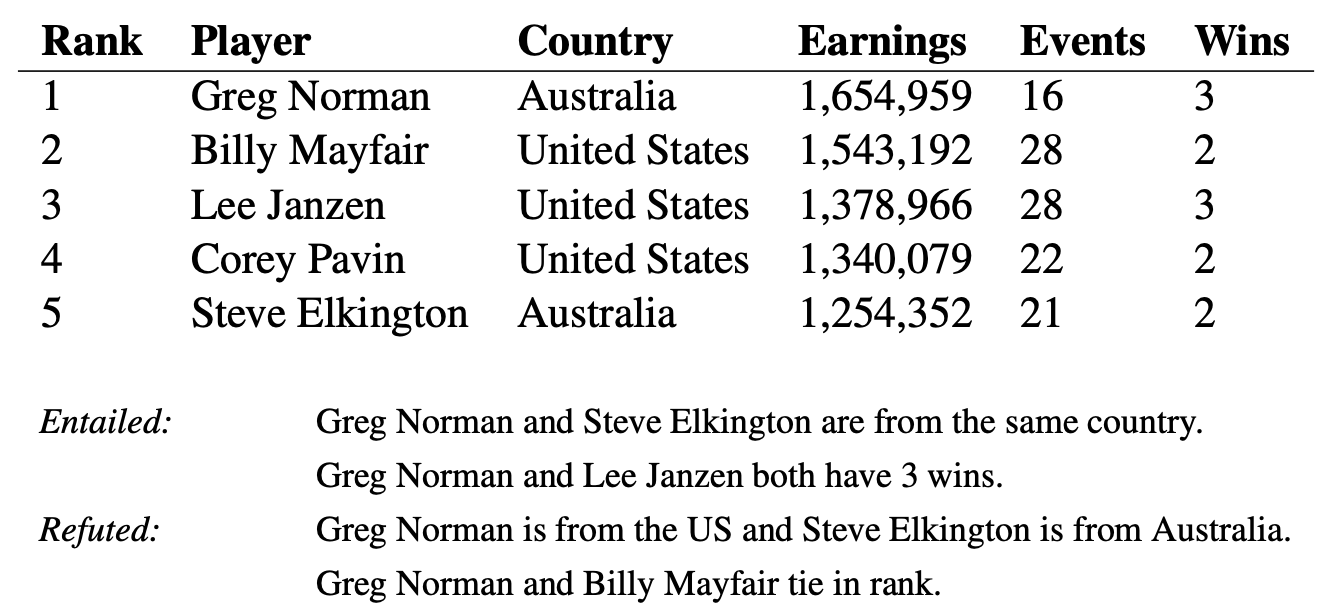
A table along with a few sentences from TabFact . The contents of the table can be used to confirm or deny a proposal.
Based on the methods used by TAPAS, the contents of the sentence and the table are coded together and then passed through the Transformer model, whereupon the probability that the sentence follows or contradicts the table is obtained.
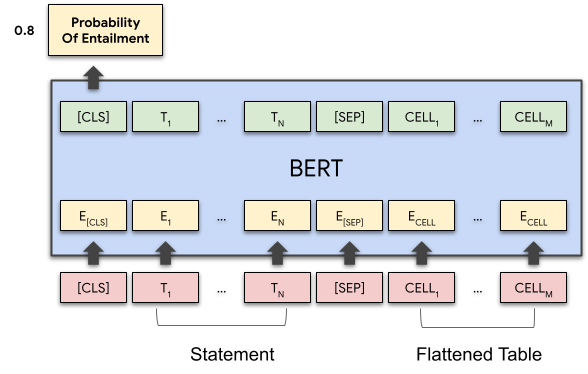
TAPAS BERT , . . .
— (.. «» «»), , , . , . , . , «Greg Norman and Billy Mayfair tie in rank» (« ») «tie» («»/«», «») , .
«» , . , . , TAPAS , . , : (counterfactual) (synthetic). ( — intermediate pre-training).
, (, ), . . , , . , . , , , , , .
, , , , (, « »), , (, « — »). , .

. , , , . , .
TabFact, TAPAS , , LogicalFactChecker (LFC) Structure Aware Transformer (SAT). TAPAS LFC SAT, (TAPAS + CS) , .
TAPAS + CS - SQA, . CS 4 , , .
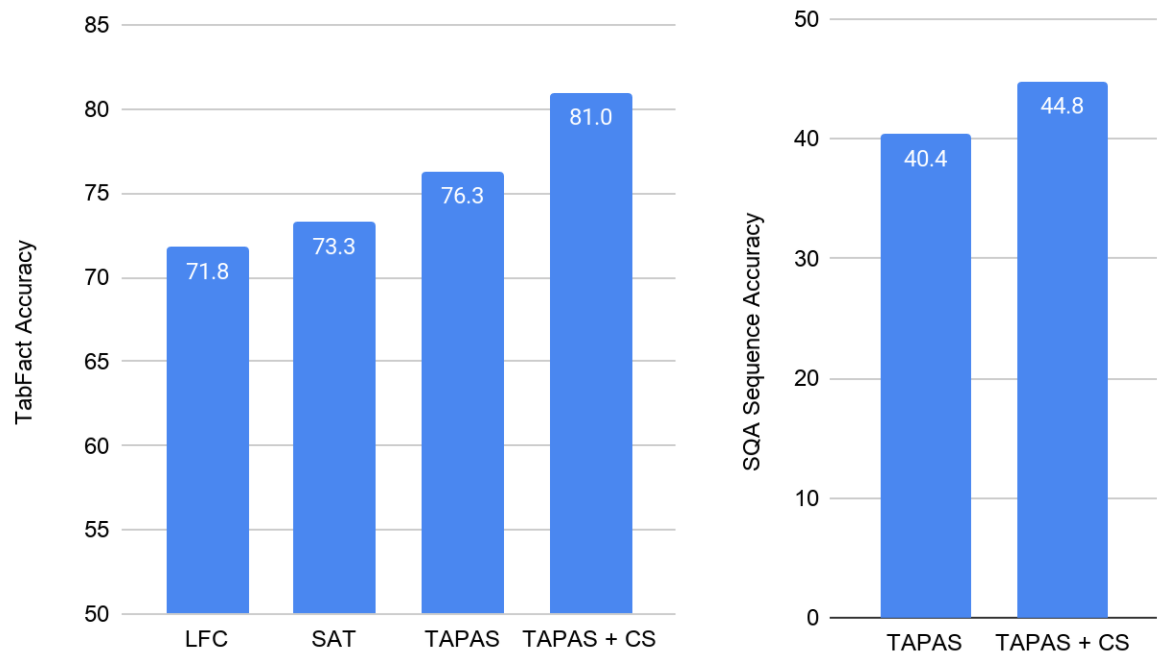
TabFact () SQA (). , .
, , , - TabFact. , ( ). , TAPAS + CS Table-Bert, 10% , .
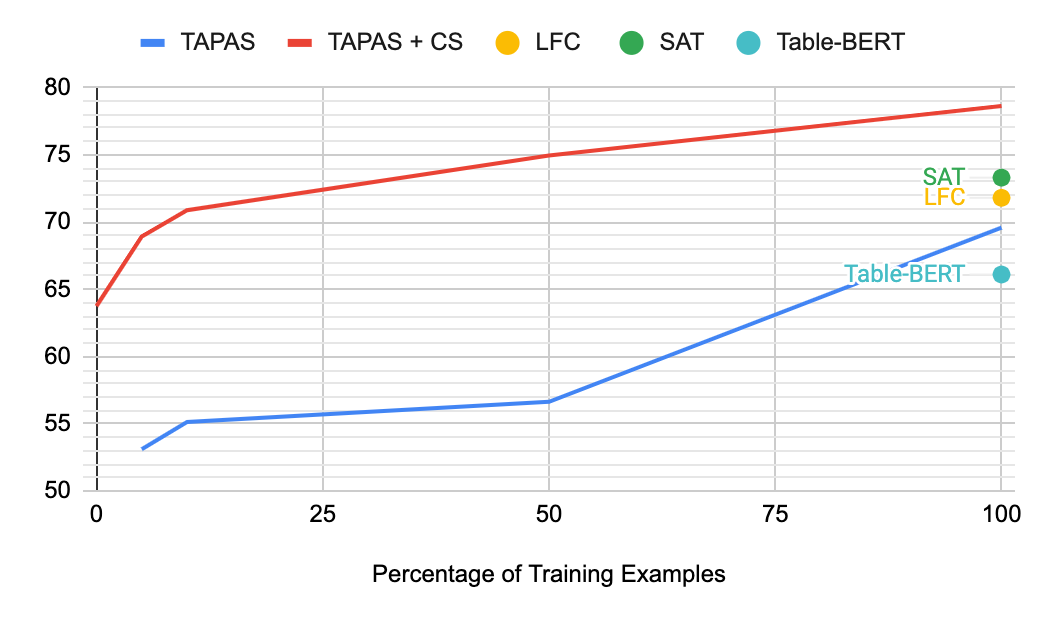
(Accuracy)
, , , . , .
, , , , . , , . , .
, , , 512 , ( , Reformer Performer, ). , TabFact. 256 , , . 128 - — 4 .
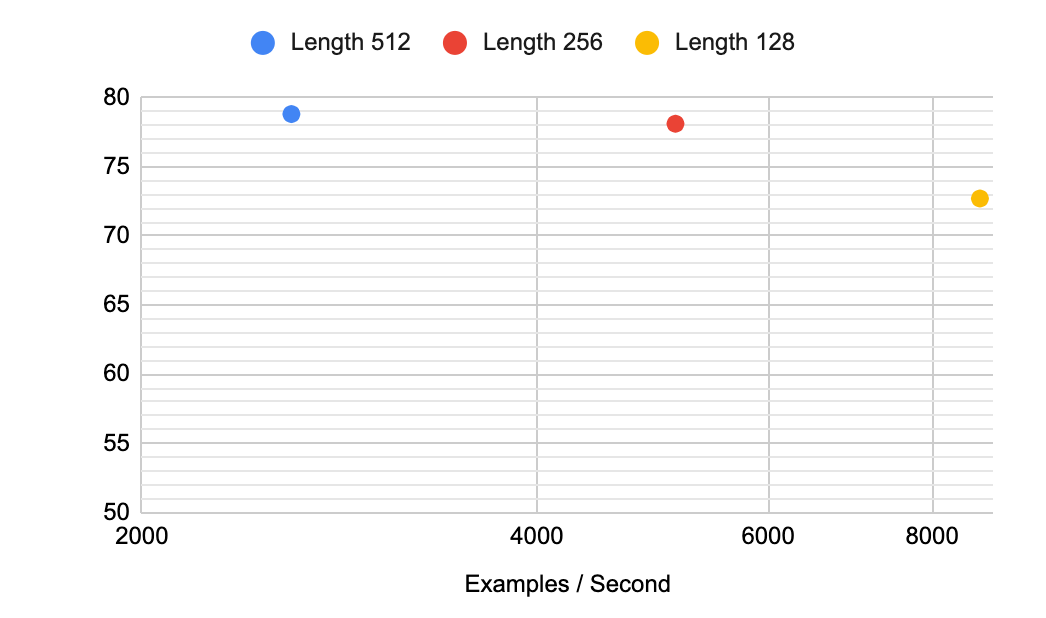
(Accuracy) TabFact .
, , .
The authors have published the new pre-learning models and methods in their GitHub repository , where you can try them out for yourself in colab . To make this approach more accessible, the authors also shared models of various sizes, down to " tiny ", in the hope that the results will help stimulate the development of technologies for understanding tabular data among a wider range of researchers.
Authors
- Original author - Julian Eisenschlos
- Translation - Ekaterina Smirnova
- Editing and layout - Sergey Shkarin