
I used to think that I didn't need comments if I was writing self-documenting code. However, I realized that I was writing comments and found them really helpful. To see how many comments I am writing and what they are, I wrote a script to analyze my git commits over the past six years. In total, seven percent of my approved lines contained comments. This post has details on what counts as good and bad comments, as well as additional statistics from my script.
Javadoc is the most useless
One of the reasons I was skeptical about comments was the predominance of Javadoc-style comments. This style of commenting exists in other languages as well. Here's a Python example I just came up with, but which is representative of this style:

The problem with most of these comments is that they convey very little information. It is often just repeating the method name and parameter names in a few words. These comments can be useful for externally exposed APIs, but in an application where you have access to all of the source code, they are mostly useless. If you are wondering what a method does or what is the valid input range for a parameter, you better just read the code to see what it does. These types of comments take up a lot of space but are not particularly valuable.
Self-documenting code
Instead of writing Javadoc comments, it is best to make the most of method names and variable names. Each name you use can help explain what it is about and how it is done. One good reason to write lots of small methods instead of one big one is that you have more places to use descriptive names, which I described here .
When to comment
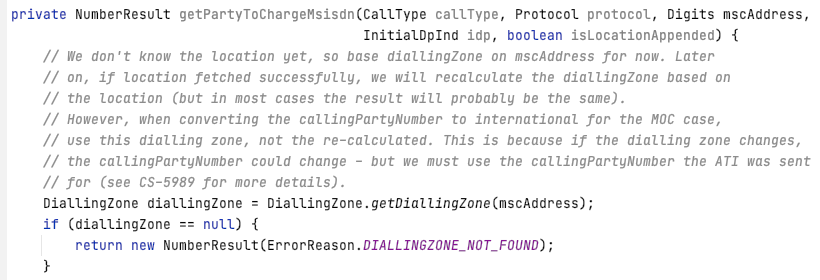
Writing self-documenting code will help you in the long run. However, there are times when it is helpful to have more information. For example, a comment about the use of dialing zones in the code below:
Another example:

You can often hear the advice “write a comment WHY, not WHAT”. While this probably covers most of my comments, this is not how I think about when to comment. Instead, I usually write a comment when there is something particularly tricky, either in the domain or in how the implementation is being done.
The standard advice from the “no comment required” crowd (which I once belonged to) is to rewrite the code so you don’t need to comment on it. However, this is not always possible. Sometimes a domain is just too complicated. Sometimes the effort to rewrite the code would be too big compared to adding a comment.
Another complaint about comments is that they will be out of sync with the code, thus hindering your understanding of the code, rather than helping it. Although it does happen sometimes, it was not a big problem for me. In almost all the cases I analyzed, the comments were still valid. They were also very helpful. Every time I came across one of these comments, I was happy that I wrote it. It doesn't take long to forget some of the details and nuances of the problem you are solving, and having a comment with some additional context and explanation was great.
Logs as comments
Sometimes you get a freebie comment if you register an explanatory message. In the example below, the log statement explains what happened, so there is no need for comments.

Comment analysis
When I first thought about checking how many comments are in all my commits, I thought one line would be enough to find the comments in all my Python commits (I only comment with #):
git log --author = Henrik -p | grep '^ + [^ +]' | grep '#' | wc -l
However, I soon realized that I needed more details. I wanted to distinguish between end-of-line comments and whole-line comments. I also wanted to know how many “comment blocks” (consecutive lines of comments) I had. I also decided to exclude test files from analysis. In addition, I want to make sure to exclude any commented out code that ended up there (unfortunately, there were several such cases). I ended up writing a python script to do the analysis. The input to the script was the output from git log --author = Henrik -p.
From the output, I saw that 1299 of the 17817 lines I added contained comments. There were 161 end-of-line comments and 464 one-line comments. The longest comment block was 11 lines, and there were 96 cases of comment blocks that had 3 or more consecutive lines.
conclusions
I used to think that writing well-named functions would mean no comments needed. However, looking at what I actually did, I noticed that I tend to add comments to complex or unintuitive parts of the code. Every time I revisit these parts of the program, I'm glad I made the effort to add a comment - they were very helpful!