For periodic events, a delay in the start of event processing is very important. More precisely, the maximum jitter. When the jitter is commensurate with the period of occurrence of the event, the system becomes unsuitable for processing periodic events.
Consider the following example. Let's say on the PCI bus we have a multichannel analog-to-digital conversion (ADC) card. The board is configured in such a way as to convert all channels for a certain period of time and add the conversion results to a previously provided buffer using DMA (Direct Memory Access) technology. The buffer is divided into 2 parts. At the end of the conversion cycle, the board generates an interrupt indicating the readiness of the first part of the buffer and goes to a new conversion cycle using the second part of the buffer to fix the results.
The task of the system is to respond to the interrupt, process the results obtained in the first part of the buffer and issue a control signal, depending on the calculated values, until the second part of the buffer is ready. If you do not have time to process the first part before the second is ready, the ADC board will again switch to the first part of the buffer and start rewriting the results that we have not yet had time to process. Typical double buffering scheme .
The interrupt handler, for obvious reasons, does not process data. It only sends a message to the user thread, which activates and processes the finished frame. The calculations associated with data processing are complex and require processor time, and the interrupt handler must be simple so as not to block the system for a long time.
The moment of the start of data processing in the user thread has jitter due to the delay in switching tasks, as well as the possible generation of interrupts from other peripheral devices and switching to processing other, higher priority threads with a subsequent return to the current one.
In pseudo-real-time systems, such a delay is not particularly regulated at all. For example, in the Linux kernel there are locks of the spin_lock_irqsave type that disable interrupt processing on a given processor core, tasklets, the processing of which can begin at the time of processing the frame data, and so on. The length of the availability period in such systems must be chosen with a large margin.
, . . . , , , .
, . . QNX Linux PREEMPT-RT.
QNX
, QNX. , .

QNX . . , QNX, . . , . . . , .
RT Linux
RT Linux, Linux, PREEMPT-RT, . Linux. RT Linux . , , spin_lock_t . .
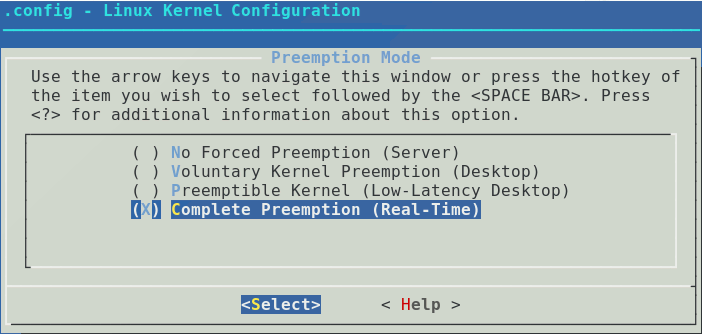
Linux , . Linux . . RT Linux QNX . . Linux . IT Linux. .
RT Linux . , , . , , . . . Linux .
. . , . , .
. i7-3770 CPU @ 3.40GH :
QNX Neutrino 6.5.0 SP1 32 bit
Ubuntu 18.04 LTS c 5.4.3-rt1 64 bit
.
#include <stdbool.h>
#include <stdint.h>
#include <string.h>
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#include <sched.h>
#include <sys/time.h>
#include <time.h>
#ifndef __linux__
#include <sys/neutrino.h>
#else
#include <atomic>
#endif
#include <cassert>
#include <iostream>
#include <fstream>
#include <ios>
#include <stdlib.h>
#define SIZEOF_ARRAY(a) (sizeof(a) / sizeof((a)[0]))
#define RING_BUFF_SIZE 4096
class CRingBuff
{
#ifdef __linux__
std::atomic<size_t> m_tail, m_head; //
#else
size_t m_tail, m_head;
#endif
uint8_t m_buff[RING_BUFF_SIZE];
inline size_t Capacity() const { return SIZEOF_ARRAY(m_buff); }
inline size_t Have() const { return m_head >= m_tail ? m_head - m_tail : Capacity() + m_head - m_tail; }
inline size_t Left() const { return Capacity() - Have(); }
public:
CRingBuff(): m_tail(0), m_head(0) {}
inline bool Empty() const { return m_head == m_tail; }
size_t putData( const uint8_t *data, size_t len );
size_t getData( uint8_t *data, const size_t max_size );
};
size_t CRingBuff::putData( const uint8_t * data, size_t len )
{
if (Left() <= len) // <=
return 0;
size_t capacity = Capacity();
if (m_head + len > capacity)
{
size_t del = capacity - m_head;
memcpy(m_buff + m_head, data, del);
memcpy(m_buff, data + del, len - del);
}
else
{
memcpy(m_buff + m_head, data, len);
}
m_head = (m_head + len) % capacity;
return len;
}
size_t CRingBuff::getData( uint8_t * data, size_t max_size )
{
if (Empty())
return 0;
size_t have = Have();
if (have > max_size)
have = max_size;
size_t capacity = Capacity();
if (m_tail + have > capacity)
{
size_t del = capacity - m_tail;
memcpy(data, m_buff + m_tail, del);
memcpy(data + del, m_buff, have - del);
}
else
{
memcpy(data, m_buff + m_tail, have);
}
m_tail = (m_tail + have) % capacity;
return have;
}
void dummy() {}
void do_something() // --
{
volatile int i;
for (i = 0; i < 21000; i++)
{
dummy();
}
}
struct sData
{
uint32_t t1, t2;
sData(): t1(0), t2(0) {}
};
CRingBuff RingBuff;
int iexit = 0;
const char sFileName[] = "elapsed.csv"; // Excel
//
void *flusher(void *arg)
{
uint32_t step(0);
while (!iexit)
{
if (!RingBuff.Empty())
{
uint8_t buff[RING_BUFF_SIZE];
size_t len = RingBuff.getData(buff, sizeof(buff));
if (!len)
{
printf("ringbuff logic 1 error\n");
exit(1);
}
if (len % sizeof(sData))
{
printf("ringbuff logic 2 error\n");
exit(1);
}
size_t sz = len / (sizeof(sData));
sData *ptr = reinterpret_cast < sData * >(buff);
for (size_t i = 0; i < sz; i++)
{
double t1 = ptr[i].t1 * 1e-7; // 100
double t2 = ptr[i].t2 * 1e-7;
printf("%u). duration: %f elapsed: %f\n", step, t1, t2);
std::ofstream myfile;
myfile.open(sFileName, std::ios::out | std::ios::app);
if (myfile.good())
{
myfile << step << ';' << t1 << ';' << t2 << ";\n";
myfile.close();
}
step++;
}
}
usleep(10 * 1000); // 10
}
return NULL;
}
#define USECS_PER_SEC (1000 * 1000)
#ifdef __linux__
inline uint64_t ClockCycles() // QNX , Linux .
{
unsigned int low, high;
asm volatile ("rdtsc\n":"=a" (low), "=d"(high));
return ((uint64_t) high << 32) | low;
}
#endif
//
class Cycles
{
uint32_t m_CyclesPerUs; // 1 .
uint32_t m_CyclesPer100Ns; // 100 .
CRingBuff m_Values;
public:
Cycles( uint32_t N ) : m_CyclesPerUs(1), m_CyclesPer100Ns(1)
{
if (N < 2)
{
N = 2;
}
uint32_t dc(0);
for (int i = 0; i < N; i++) // N 1
{
uint32_t c = (uint32_t)ClockCycles();
usleep(USECS_PER_SEC);
dc = (uint32_t)ClockCycles() - c;
printf("%d). Cycles: %u\n", i, dc);
dc /= USECS_PER_SEC;
m_Values.putData(reinterpret_cast<const uint8_t*>(&dc), sizeof(dc));
}
for (int i = 0; i < N - 1; i++) //
{
uint32_t val;
m_Values.getData(reinterpret_cast <uint8_t*>(&val), sizeof(val));
if (val != dc) //
{
printf("CyclesPerUs error %u %u\n", val, dc);
exit(1);
}
}
m_CyclesPerUs = (uint32_t)dc;
m_CyclesPer100Ns = m_CyclesPerUs / 10;
printf("Cycles_per_us:%u\nCycles_per_100ns:%u\n", m_CyclesPerUs, m_CyclesPer100Ns);
}
uint32_t getCycPerUs() const { return m_CyclesPerUs; }
uint32_t getCycPer100Ns() const { return m_CyclesPer100Ns; }
// 32 , .. 32-
static uint32_t getCycles() { return (uint32_t) ClockCycles(); }
uint32_t calc100Ns( const uint32_t cycles ) const { return cycles / m_CyclesPer100Ns; }
uint32_t calcUs( const uint32_t cycles ) const { return cycles / m_CyclesPerUs; }
};
const unsigned long sleep_us = 500;
int elapsed( void )
{
double clock_res;
// QNX
#ifndef __linux__
{
const unsigned long system_resolution_ns = 10 * 1000;
{
struct _clockperiod nres;
nres.fract = 0;
nres.nsec = system_resolution_ns;
if (ClockPeriod(CLOCK_REALTIME, &nres, NULL, 0) < 0)
{
printf("ClockPeriod error\n");
exit(1);
}
}
//
struct timespec res;
if (clock_getres(CLOCK_REALTIME, &res) < 0) {
printf(" get system resolution error\n");
exit(1);
}
clock_res = res.tv_sec * 1e9;
clock_res = clock_res + res.tv_nsec * 1e-9;
printf("clock_getres: %f sec\n", clock_res);
}
#endif
//
{
//
remove(sFileName);
pthread_t tid;
pthread_create(&tid, NULL, flusher, NULL);
struct sched_param sp;
#ifndef __linux__
sp.sched_priority = 255; // QNX
#else
sp.sched_priority = 99; // Linux
#endif
int rt = sched_setscheduler(0, SCHED_FIFO, &sp);
if (rt) {
printf("set scheduler error\n");
exit(1);
}
}
const uint32_t N(5);
Cycles cyc(N);
//
{
std::ofstream myfile;
myfile.open(sFileName, std::ios::out | std::ios::app);
if (myfile.good())
{
myfile << "Resolution (sec)" << ';' << "Cycles per us" << ';' <<"Cycles per 100ns" << ";\n";
myfile << clock_res << ';' << cyc.getCycPerUs() << ';' << cyc.getCycPer100Ns() << ";\n";
myfile << "Step" << ';' << "job (sec)" << ';' << "Sleep (sec)" << ";\n";
myfile.close();
}
}
uint32_t start = cyc.getCycles();
do
{
do_something(); //
sData data;
uint32_t mid = cyc.getCycles() - start;
data.t1 = cyc.calc100Ns(mid);
usleep(sleep_us - cyc.calcUs(mid));
uint32_t end = cyc.getCycles();
data.t2 = cyc.calc100Ns(end - start);
RingBuff.putData(reinterpret_cast < const uint8_t * >(&data), sizeof(data));
start = end;
} while (1);
return 0;
}
int main(int argc, const char **argv)
{
return elapsed();
}
500 . SCHED_FIFO. . . .
. QNX ClockCycles(). Linux rdtsc. 64 . 32- . 3.4 , 32- .
do_something(), usleep() 500 .
, usleep. . .. , 500 , . , . , .
. . . - do_something(), , . 500 . , .
")
, do_something(), , . do_something() 500 . .. .
. , .
QNX . 1 . 500 10 . , . .
Linux 1 (HZ=1000). . Linux HPET (High Precision Timer Support) . .
POSIX QNX Linux . ++. . CRingBuff, .
QNX Momentics IDE 4.7 gcc 4.4.2, C++11. QNX CRingBuff. . Ubuntu 64 bit -m32.
flusher . - elapsed.csv . GNU Octave, 500 (min, max), (avg), (med) , (std) err = 3*sigma . (r_err), (r_d), (r_max). stat_summary().
function stat_summary(name, data)
m = mean(data);
s = std(data);
mi = min(data);
ma = max(data);
printf("%40s [us]: min=%6.1f; max=%7.1f; avr=%6.1f; med=%6.1f; std=%7.3f; err=%6.3f; r_err=%6.2f %%; r_d=%6.2f %%; r_max=%6.2f %%\n", name, mi, ma, m, median(data), s, 3*s, 3 * s / m * 100.0, (ma - mi) / m * 100.0, (ma - m) / m * 100);
end
106 . , , . 100 .
elapsed.csv . , (2021-06-02 16:21).
210602 1621.qnx hw cycles.sleep [us]:
min= 492.2; max= 598.4; avr= 505.0; med= 506.9; std= 5.353; err=16.058;
r_err= 3.18 %; r_d= 21.03 %; r_max= 18.50 %
")
210604 1305.linux rt cycles.sleep [us]:
min= 492.9; max= 570.7; avr= 499.6; med= 499.5; std= 3.746; err=11.239;
r_err= 2.25 %; r_d= 15.57 %; r_max= 14.22 %
")
. , .
QNX c 10 . .
, Linux QNX. , . , . , .
Linux, PREEMPT-RT. .
210606 0934.linux srt native.sleep [us]:
min= 502.4; max= 4524.4; avr= 510.8; med= 505.4; std=128.778; err=386. 334;
r_err= 75.63 %; r_d=787.35 %; r_max=785.70 %
")
"!"
(510.8 ), 4524.4 . . .
. QNX - , Linux. . , RT Linux. , .
I also want to note the fact that the patch itself, like the Linux kernel, is actively developing. In addition to support for new versions of the kernel, improvements are being made in terms of realtime. In the past, I have used a patch for the 2.6.33.7 kernel. I think the results would have been different than today. As that time has come to use RT Linux.