
In this article, I will talk about one of the methods for eliminating the imbalance of predicted classes. It is important to clarify that many of the methods that build probabilistic models work fine without correcting the imbalance. However, when we move on to building improbability models or when we consider a classification problem with a large number of classes, it is worthwhile to attend to the problem of class imbalance.
, ́ , , , . , .
NearMiss — . ́ . , .
. pip cmd:
pip install pandas
pip install numpy
pip install sklearn
pip install imblearn
, - -.
import pandas as pd
import numpy as np
df = pd.read_csv('online_shoppers_intention.csv')
df.shape
(12330, 18)
«Revenue» 2 : True ( ) False ( ). , .
df['Revenue'].value_counts()
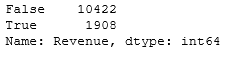
, , 85% 15%.
:
Y = df['Revenue']
X = df.drop('Revenue', axis = 1)
feature_names = X.columns
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3, random_state = 97)
:
print(' X_train: ', X_train.shape)
print(' Y_train: ', Y_train.shape)
print(' X_test: ', X_test.shape)
print(' Y_test: ', Y_test.shape)

.
from sklearn.linear_model import LogisticRegression
lregress1 = LogisticRegression()
lregress1.fit(X_train, Y_train.ravel())
prediction = lregress1.predict(X_test)
print(classification_report(Y_test, prediction))
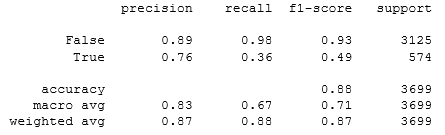
, 88%. «recall» , . , , .
NearMiss :
print(' - True: {}'.format(sum(y_train == True)))
print(' - False: {}'.format(sum(y_train == False)))
True: 1334
False: 7297
.
from imblearn.under_sampling import NearMiss
nm = NearMiss()
X_train_miss, Y_train_miss = nm.fit_resample(X_train, Y_train.ravel())
print(' - True: {}'.format(sum(Y_train_miss == True)))
print(' - False: {}'.format(sum(Y_train_miss == False)))
True: 1334
False: 1334
It can be seen that the method has leveled the classes, decreasing the dimension of the dominant class. Let's use logistic regression and display a report with the main classification indicators.
lregress2 = LogisticRegression()
lregress2.fit(X_train_miss, Y_train_miss.ravel())
prediction = lregress2.predict(X_test)
print(classification_report(Y_test, prediction))

The value of minority reviews rose to 84%. But due to the fact that the sample of the larger class was significantly reduced, the accuracy of the model decreased to 61%. So this method really helped to deal with class imbalance.