 We at ABBYY have been dealing with Natural Language Processing (NLP) problems for a long time
. Natural language processing technologies are at the heart of many of ABBYY's NLP solutions for searching and extracting data. With their help, we helped the industrial giant NPO Energomash
to make a search according to the documents accumulated at the enterprise for almost 100 years, and one of the large banks
usesour technology to monitor the gigantic news flow and manage risk. In this post, we will explain how our NLP technologies work internally for extracting information from solid text. We will not talk about text in tables and clearly structured forms, such as invoices, but about multi-page unstructured documents: lease agreements, medical records and much more.
We at ABBYY have been dealing with Natural Language Processing (NLP) problems for a long time
. Natural language processing technologies are at the heart of many of ABBYY's NLP solutions for searching and extracting data. With their help, we helped the industrial giant NPO Energomash
to make a search according to the documents accumulated at the enterprise for almost 100 years, and one of the large banks
usesour technology to monitor the gigantic news flow and manage risk. In this post, we will explain how our NLP technologies work internally for extracting information from solid text. We will not talk about text in tables and clearly structured forms, such as invoices, but about multi-page unstructured documents: lease agreements, medical records and much more.
We will then show you how this works in practice. For example, how to extract X entities from a 200-page bank agreement in X minutes. Either make sure the legal contract is correct, or get information on rare side effects quickly from a collection of medical articles. Our experience shows that companies need to obtain such data quickly and without errors, since the well-being of both business and people depends on it.
At the end of the post, we will mention several difficulties that we encountered while conducting such projects, and share our experience of how we managed to resolve them. Well, welcome to cat.
So what are we doing?
In general, natural language processing and analysis technologies allow a lot: filter spam in e-mail, create machine translation systems, recognize speech, develop and train chat bots. ABBYY's NLP technologies help banks, industrial and other organizations quickly extract and structure a large amount of information from business documents. Large companies have long been automating, or at least striving to reduce, the number of manual, routine operations. We are talking about searching in a paper document for the date, full name, amount, TIN, invoice number; reprinting data into corporate information systems, checking if everything is filled in correctly.
Recall that initially we were able to extract text from documents based on geometric features, in particular the structure and arrangement of lines and fields. Thus, it is still convenient to process information from structured questionnaires, strict forms, questionnaires, applications, census forms, etc. By the way, we talked on Habré about such a case - with the help of ABBYY FlexiCapture, the Ministry of Health of Bangladesh processed medical census questionnaires filled out by residents of the republic.
It is clear that important information is stored not only in forms, so we trained our NLP solutions to “extract” data from documents that have no structure at all or are extremely complex. Probably many people remember about ABBYY Compreno for natural language analysis and understanding. We have developed and improved the technology, and subsequently it formed the basis of many of our NLP solutions. One of the cases of using NLP is a project with monitoring news in several large Russian banks. In short, our engine is able to perform the work of a bank underwriter - a person who catches events about counterparties from a gigantic stream of information and assesses risks. Read more about it here .
Below we will talk about another aspect - the extraction of information from such unstructured documents as contracts, medical records, news from various sources.

How our NLP technologies work
Conceptually, document processing from the moment it is loaded into ABBYY FlexiCapture until the required fields are extracted looks like this:
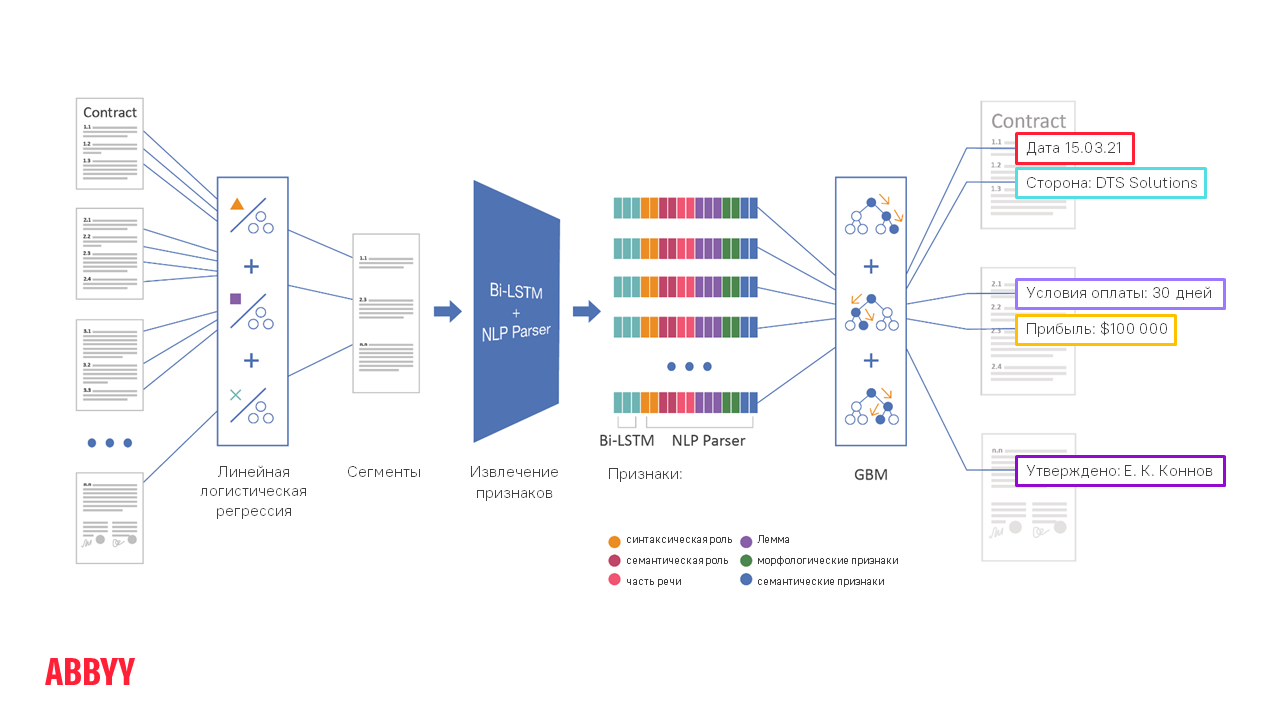
Let's say you need to extract the date and place of signing, as well as the names of participating companies from a 50-page contract. 50-page, Karl! And there are a lot of dates! How do I find the page the client is looking for? Technology helps to do this in several stages.
Segmentation stage
Next, the document is segmented , that is, we narrow the area for finding information and process not all 50 pages, but only, say, 5 segments per paragraph, where the date we need may be. So it is much easier for the algorithms to work, as well as to distinguish the required date from some other.
All stages to the right of segmentation on the diagram describe the operation of NLP algorithms - detailed study, reading and understanding of the text. These processes take 10-20 times longer than classification and segmentation, so it is not entirely correct to run them on an entire multi-page document. It is easier to "incite" them to a small amount of text.
How NLP Parser + Bi-LSTM Work
With their help, signs (features) are extracted from each sentence in the text. This is ABBYY Compreno technology, which works as part of FlexiCapture. The engine reads the text in detail and extracts a lot of generalizing features from it. He understands not only what is specifically formulated in this sentence, but also the meaning - what is actually meant.
Feature extraction is a lengthy step. There are high-level signs. Roughly speaking, they indicate that in this fragment, something like a name does something like an action with some object from some semantic class. Then, on the extracted high-level features, a fairly simple and classical ML-GBM method is applied. It is an ensemble of decision trees that provides a general solution and highlights the extracted fields. For GBM to learn quickly and extract quality information, it is important to have a sufficient number of documents for training. If there are few of them, then the quality of information extraction may decrease. This is due to the fact that the core of cases becomes smaller and, accordingly, the "machine" is worse at generalizing - to distinguish individual cases from frequent ones.

Where is it used?
Here are some examples from our practice - implemented projects, pilots or concept cases.
NLP for financial institutions

Customers often ask us to process invoices (invoices) and purchase orders. Some data (or fields), blocks with text or with an address, can be extracted using traditional methods, relying on keywords. But if you need to look inside a text block, then NLP is needed. It also happens that you need to "get" not the entire block with the address, but only a part of this address: street, state, city, postal code, country. Or you need to parse the dates and discount percentages if the invoice requires payment before a specific date. Our technologies help to take into account such variables: how much an order will cost if paid in advance or in bulk, and how much if paid late.
We also help the legal departments of large companies extract important data from service contracts, progress reports, NDAs (nondisclosure documents). Let's take as an example one of our projects dealing with commercial lease agreements. They were documents of 30 pages, data from the fields on each page the customer previously entered into the information system manually. This usually took an hour for one document. FlexiCapture completed the task in two minutes and, according to the client's calculations, saved him 5000 man-hours in a year.
Or take loan agreements. Loans are taken not only by people, but also by large companies. To do this, they provide the bank with a large package of documents. Let's say information about available commercial loans. And this is not some kind of mortgage for 6 million rubles, but a mortgage for 100 million dollars (for buildings, offices). And then the bank needs to extract 50-70 entities or conditions from such a 250-page document. It was processed manually for a long time, according to our customer's calculations - 2-3 hours per document. With FlexiCapture, everything was ready in 9 minutes. Not instantly, we understand. The reason is in the design of documents: they usually have a high density of text, and a large number of different entities must be extracted. Not a second thing :)
Loan Applications are often processed too. This is a preliminary document with questions that the bank sends to the client. The larger the loan amount, the more questions there are in such a questionnaire. For example, in the information on the place of work, the bank may ask you to indicate its identifier and legal address. Banks often require clarification of information about marital status, availability of loans, debts for utilities, alimony and other things that may interfere with the repayment of the loan. Sometimes the questions in Loan Applications are quite complex, so some companies help their customers translate from legal to public language in order to understand and describe in a human way what they want from the client.
In processing such completed documents, the main difficulty lies in the large number of fields (in our case, there were 105 of them). It is easy for a bank employee to get confused in them, but this cannot bring down the technology. FlexiCapture spends 5 minutes on everything, an employee - up to 2-3 hours. Feel the difference, as they say.
Healthcare
Part of ABBYY's projects are related to the extraction of information from medical documents.

For example, using NLP, you can process the Abstract of scientific medical articles. There is such a direction in pharmacology - Pharmacovigilance. It is investigating the side effects that new drugs can cause in patients that have not yet been described. Medical organizations collect information about such critical cases from patients and draw up detailed reports about them - Individual Case Safety Reports (ICSR). If a new tablet harms a person, then the manufacturer must quickly report this to the regulatory body, otherwise he could face a large fine. To avoid such consequences, highly qualified employees of pharmaceutical companies read ICSR in large quantities. Quite a tedious task.
It is much easier to puzzle technologies with these. As part of one of the Pharmacovigilance pilots, our technology extracted data from medical articles such as the patient's gender and age, information about the event that happened to him, and the name of the drug. Everything except the last one was extracted using machine learning. But for the names of the drugs, we used a simpler method - dictionaries. The bottom line is that the client asked to extract not all possible drugs from the articles, but drugs from a list with 80 names. In this case, the dictionary matching worked just fine. Dictionaries are also part of FlexiCapture NLP. Morphology is used to find the name of a drug. It does not matter in what form or register the word is written, especially in English there are not so many of them.
The processing of case histories is also automated, because there is a lot of information to go through. These are tables, receipts, and a description of the insurance company's decision. For example, one of the regulators in the United States accepts complaints from patients about insurance. It happens that the insurance company refuses to pay for the treatment. The reasons may be different, but the patient has the right to figure it out and apply to the government agency. And the regulator must analyze the information and issue a verdict, was the refusal really justified?
If tables are easily processed using FlexiLayout, then the pieces of text with the insurance decision not to process. We used NLP to extract the solution itself and its rationale from the text.
Medical histories need to be carefully analyzed when a patient is transferred from one hospital to another. Given that we live in a time of coronavirus, sometimes there are a lot of such patients, and it is difficult for hospital staff to cope with too much paperwork. The case in which we participated had nothing to do with the crown, but potentially our experience is still valuable.
Real Estate
- One of our potential clients rents a lot of land for construction and offices. Accordingly, the company enters into many lease agreements... She needs to automatically process such documents: extract dates and deadlines from them, so that later she can track whether they miss payments, when the lease ends, where the contract is automatically renewed, how much it all costs.
- Construction companies also have specialists such as portfolio analysts... They analyze contracts, find out how much a particular property costs and help assess how good it is and how much income it can bring to the owner. Like bank scoring. In the United States, by the way, you can sell or partially purchase a package of mortgages. This is a security, it can also rise or fall in price. For example, if real estate prices rise, then a mortgage that cost less can be refinanced. And if everything becomes cheaper, then the client tries to throw off this paper.
In such a contract, there is information that is extracted both with the help of NLP and without it. Tabular data - using FlexiLayout (this is what we could do before). And all other fields are paragraphs that are extracted by the segmenter, or fields within paragraphs that are extracted by extraction models.
The advantage of NLP technologies is that it is another mechanism by which more types of fields and documents can be processed.

- One of our clients is the home owner association, conditionally our SNT . If a new participant enters into such a SNT, then he is given a package of 9 types of documents - Deeds (this can be a sale and purchase agreement). Then the data from these completed documents must be processed, verified and entered into the information system. 8 of them are structured and processed by FlexiLayout. But the 9th with a catch. To complete this project, our company also needed to process unstructured acts.
Which is what we did using NLP. The documents themselves, on the one hand, are not too voluminous: 1-2 pages. On the other hand, they are very diverse and of poor quality. Despite this, our solution was able to extract the required information. This project is interesting in that its NLP part can be very small, but at the same time critical, because without it the project simply cannot be completed.
- NLP needs and to automate the process of contract approval (Contract Approval Automation). Companies often enter into a master agreement, a framework agreement that sets out the general terms for a number of future operations. For example, what the client must fulfill, in what time frame, what sanctions for delays, when to pay for services.
The process of automatically approving a contract looks like this: we extract a certain number of fields and conditions (clause) from the document. Fields are one or more words, and clause is one or more paragraphs that can contain long descriptions. A company needs to extract fields in order to index documents on them, put them in electronic storage, and then search them. On clause, Approval occurs - checking if the conditions are correct. The extracted technology terms are compared with the terms in the master agreement. If everything matches, then there are no risks for the company, you can automatically approve (review) and send the contract to the database. This makes life much easier for lawyers: instead of dealing with the same type of contracts, they can switch to more important tasks.The contract will have to be reviewed only if the system reveals any inconsistencies with the main document in the document.

What unites all NLP projects
In structured invoices, where we recognize the amount and address, it is immediately clear where the required fields are located, and the documents themselves occupy one or more pages. In the case of unstructured documents, it is not always possible to quickly determine what data and where to extract from - this is the main feature of NLP projects. In addition, the documents themselves occupy not one page, but 100-200 pages. Therefore, at the stage of developing requirements, we first ask the customer to compile a list of several dozen fields that need to be retrieved. Such projects require the participation of a subject matter expert - an expert in this field, who will answer the questions of what and in what case needs to be extracted from the document and what nuances to pay attention to.
Sometimes a customer asks to extract several hundred fields from a document at once. This approach is not constructive and leads to the fact that it takes more than one month to discuss the requirements for the project. That is why, as a rule, we start not with hundreds of fields, but with 10, clarify the requirements, demonstrate how everything will work. As a result, both us and the customer understand the further stages of the project and milestones.
Also, for any machine learning, ML-project, including NLP, a representative sample is needed - samples of customer documents on which the system will be trained. The more, the better.
Conclusion
Using these examples, we have shown how technology helps to save our main resource - time. In English, the scheme is called win-win: robots take on repetitive tasks, and employees free their hands in order to engage in more intelligent and interesting projects. Companies in which not specialists, but machines are engaged in routine, can build interaction with customers more efficiently, avoid mistakes in the processing of certain documents and increase profitability faster.