An in-memory database is not a new concept. But it is too closely associated with the words "cache" and "not persistent." Today I will explain why this is not necessarily the case. In-memory solutions have a much wider field of application and a much higher level of reliability than meets the eye.
In this article, I discuss the architectural principles of in-memory solutions. How can you take the best of the in-memory world - incredible performance - and not sacrifice the virtues of disk-based relational systems. First of all, reliability - how can you be sure that your data is safe.
This story condenses 10 years of experience with in-memory solutions into one text. The entry threshold is as low as possible. You don't need to have as many years of experience to benefit from reading, a basic understanding of IT is enough.
- Introduction
- History of development
- Tarantool today
- How the kernel works
- Lua
- Fiber and cooperative multitasking
- Database functionality
- Comparison with other systems
- Usage scenarios
- Conclusion and conclusions
- Links
Introduction
My name is Vladimir Perepelitsa, but I am better known as Mons Anderson. I am an architect and product manager for Tarantool. I have been using it for many years in production, for example when building an S3 compliant object storage [1]. Therefore, I know him well enough inside and outside.
In order to understand technology, it is helpful to plunge into history. We will find out what Tarantool was like, what it went through, what it is today, compare it with other solutions, consider its functionality, how it can work over the network, what is in the ecosystem around.
This example will allow us to understand what benefits you can get from in-memory solutions. You will learn how to avoid sacrificing reliability, scale and usability.
PS: this is a transcript of an open lesson, adapted for the article. If you prefer to listen to YouTube on 2x, a link to the video is waiting for you at the end of the article [2].
History of development
Tarantool was created by the internal development team of Mail.ru Group in 2008, initially without any scope for open source. However, after two years of operation within the company, we realized that the product was mature enough to share it in the public. This is how the open source history of Tarantool began.
commit 9b8dd7032d05e53ffcbde78d68ed3bd47f1d8081 Author: Yuriy Vostrikov <vostrikov@corp.mail.ru> Date: Thu Aug 12 11:39:14 2010 +0400
But why was it created?
Tarantool was originally developed for the My World social network. At that time, we were already a fairly large company. A MySQL cluster that stored profiles, sessions, and users cost a lot. So much so that in addition to productivity, we thought about money. From here was born the story "How to save a million dollars on the database" [3].
That is, Tarantool was made to save money on huge MySQL clusters. It went through a gradual evolution: it was just a cache, then a persistent cache, and then a full-fledged database .
Having earned an internal reputation in one project, it began to spread to others: mail, advertising banners, the cloud. As a result of widespread use within the company, new projects are often launched on Tarantool by default.
If you follow the history of the development of Tarantool, you can see the following picture. Tarantool was originally an in-memory cache. At its inception, it was almost no different from memcached.
To solve cold cache problems, Tarantool became persistent. Further replication was added to it. When we have a persistent cache with replication, this is already a key-value database. Indexes were added to this key-value database, that is, we were able to use Tarantool almost like a relational database.
And then we added Lua functions. Initially, these were stored procedures for working with data. Lua functions then evolved to a cooperative runtime and an application server.
Gradually, all this was overgrown with various additional chips, capabilities, and other storage engines. Today it is already a multi-paradigm database. More on this.
Tarantool today
Today Tarantool is a flexible data schema in-memory computing platform.
Tarantool can and should be used to create high-load applications. That is, to implement complex solutions for storing and processing data, and not just making caches. Moreover, it is not just a database, but a platform on which you can create something.
Tarantool comes in two versions. Available to most, the most understandable and well-known is the open source version. Tarantool is developed under a Simplified BSD license, hosted entirely on GitHub by the Tarantool organization.
There we have Tarantool itself, its core, connectors to external systems, topologies such as sharding or queues; modules, libraries, both from the development team and from the community. Community modules may well be hosted by us.
In addition to the open source version, Tarantool also has an enterprise branch. First of all, this is support, enterprise products, training, custom development and consulting. Today we are going to talk about the main functionality that all versions of the product have.
Tarantool is today a basic component for database-centric applications.
How does the kernel work?
The main idea around which Tarantool was born and developed is that data is in memory. This data is always accessed from one thread. The changes we make are written linearly in the Write Ahead Log.
Indexes are built on the data in memory. That is, we have indexed and predictable access to data. A snapshot of this data is saved periodically. What is written to disk can be replicated.
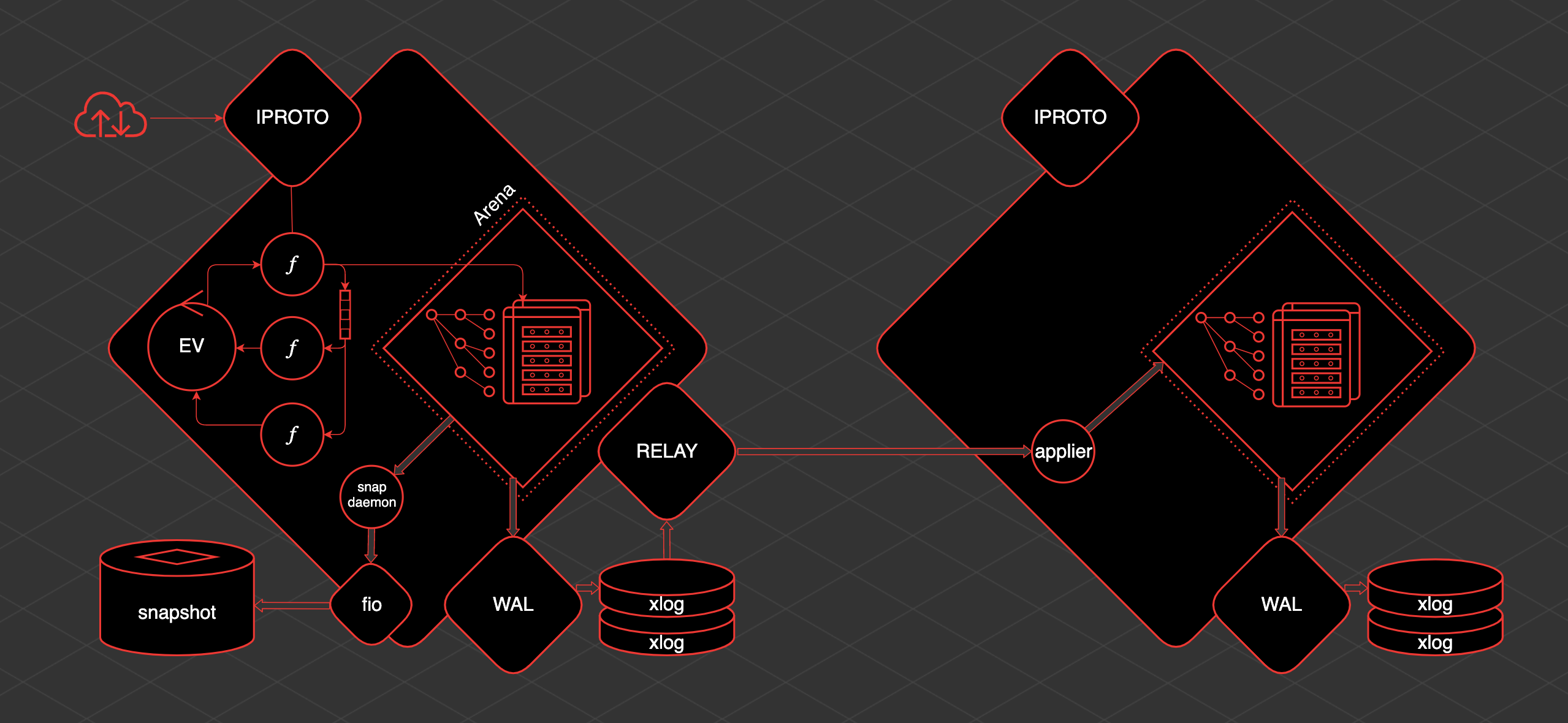
Tarantool has one main transactional thread. We call it the TX thread. Within this thread, there is Arena. This is an area of memory allocated by Tarantool for storing data. The data is stored in Tarantool in spaces.
Space is a set, a collection of storage units - taples. Tapl is like a row in a table. Indexes are built on this data. Arena and the specialized allocators that work within Arena are responsible for storing and organizing all this.
- Tapl = string
- Space = table
Also inside the TX thread there is an event loop, event loop. Fibers work within the event loop. These are cooperative primitives from which we can communicate with spaces. We can read data from there, we can create data. Also, fibers can interact with the event loop and with each other directly or using special primitives - channels.

In order to work with the user from the outside, there is a separate thread - iproto. iproto accepts requests from the network, processes the Tarantool protocol, passes the request to TX, and runs the user's request in a separate fiber.
When any data change occurs, a separate thread called WAL (from write ahead log) writes files called xlog.
When Tarantool accumulates a large amount of xlog, it can be difficult for it to start quickly. Therefore, to speed up the launch, there is a periodic saving of snapshot. To save snapshots, there is a fiber called the snapshot daemon. It reads the consistent contents of the entire Arena and writes it to disk in a snapshot file.
It is not possible to write directly to disk from Tarantool because of cooperative multitasking. You cannot block, and the disk is a blocking operation. Therefore, work with the disk is carried out through a separate thread pool from the fio library.

Tarantool has replication and is pretty simple to organize. If there is one more replica, then in order to deliver data to it, another thread is raised - relay. Its task is to read xlog and send them to replicas. The fiber applier is launched on the replica, which receives changes from the remote host and applies them to the Arena.
And these changes are exactly the same as if they were made locally, via WAL, they are written to the xlog. Knowing how it all works, you can understand and predict the behavior of this or that Tarantool section and understand what to do with it.
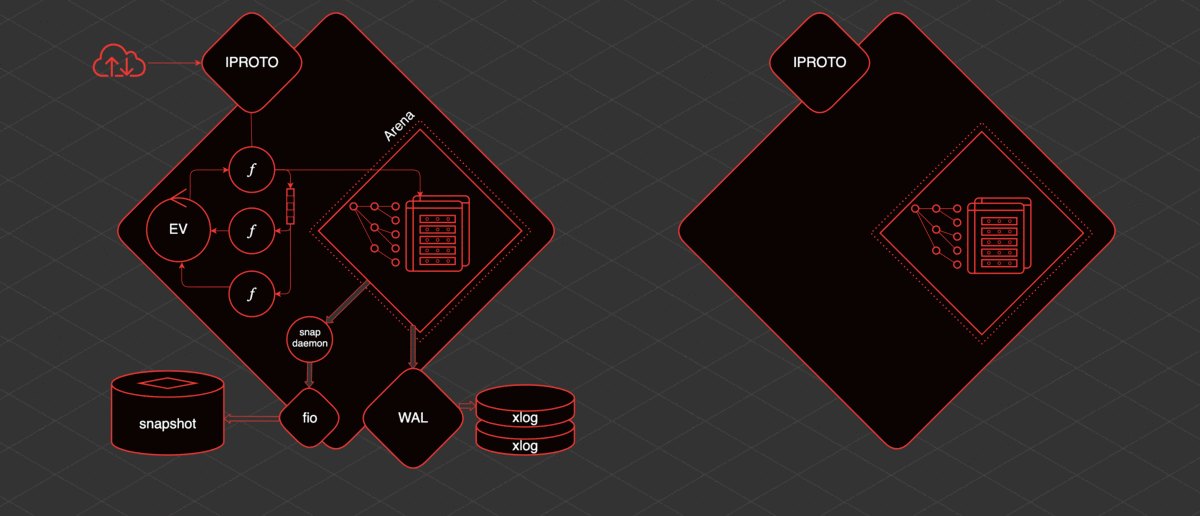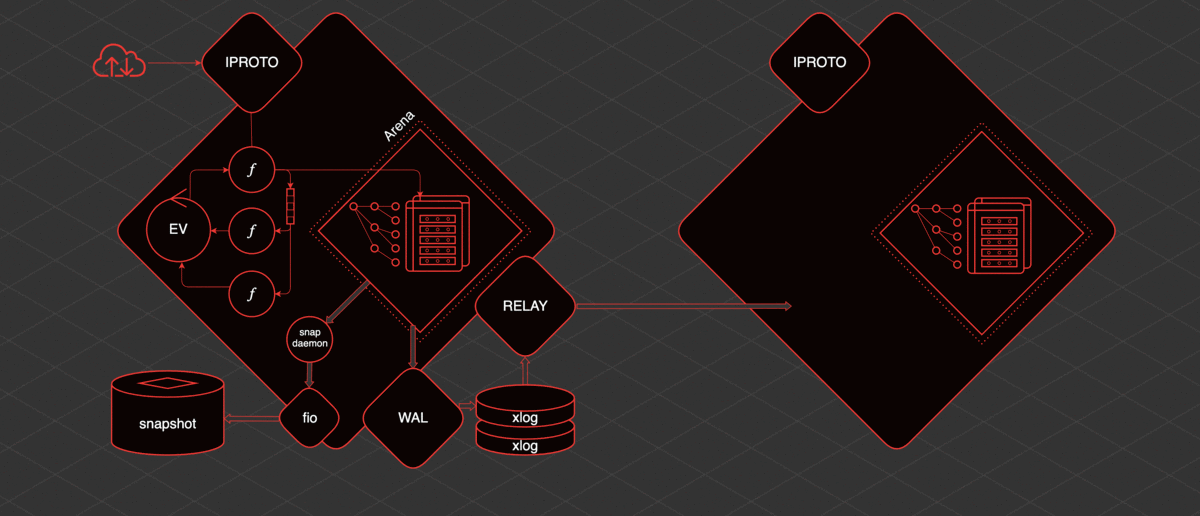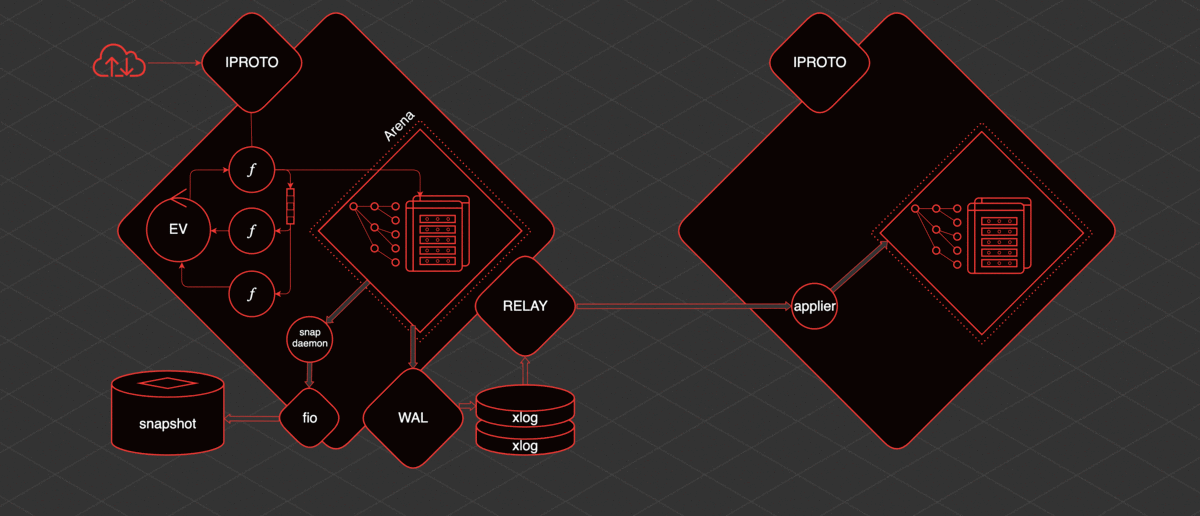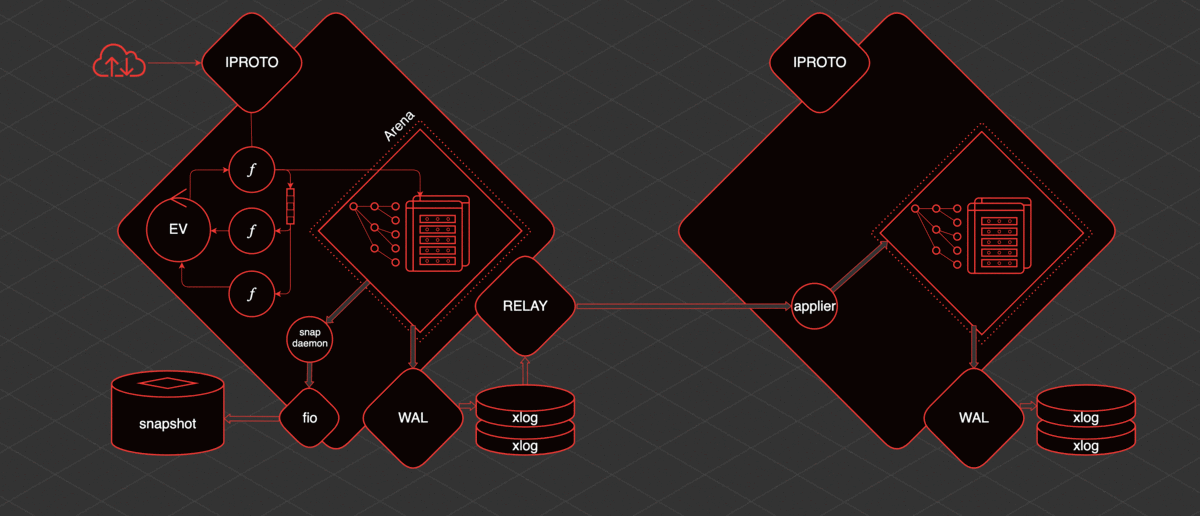
What happens when you restart? Let's imagine that Tarantool has been running for a while, there is a snapshot, there is an xlog. If you restart it:
- Tarantool finds the latest snapshot and starts reading it.
- Reads and looks at what xlog there are after this snapshot. Reads them.
- Upon completion of reading snapshot and xlog, we have a snapshot of the data that was at the time of restart.
- Then Tarantool completes the indexes. At the time of reading the snapshot, only primary indexes are built.
- When all the data has been hoisted into memory, we can build secondary indexes.
- Tarantool launches the application.
The kernel structure in six lines:
- Data is in memory
- Accessing data from one thread
- Changes are written to the Write Ahead Log
- Indexes are built on the data
- Snapshot will be saved periodically
- WAL is replicated.
Lua
Tarantool applications are implemented in LuaJIT. Here you can stop and talk about why LuaJIT.
First, Lua is an accessible scripting language that was originally created not for programmers, but for engineers. That is, for people who are technically educated, but not very deeply immersed in the specifics of programming.
Lua has been kept as simple as possible. Therefore, it turned out to be possible to create a JIT compiler that allows you to bring the performance of a scripting language almost to the performance of C. You can find examples when a small Lua program compiled in LuaJIT practically catches up with a program similar to C in performance [4].
Lua makes it pretty easy to write efficient things. In general, there was an idea around Tarantool - to work side by side with data. By running the program in the same namespace and the process in which the data is located, we can not waste time walking around the network.
We are accessing memory directly, so reading has almost zero and predictable latency. All this could have been achieved simply with Lua functions, but inside Tarantool there is an event loop plus fibers. Lua is integrated with them.
Total:
- Lua: a simple scripting language for engineers
- Highly efficient JIT compilation
- Working alongside data
- Not procedures, but a cooperative runtime
Fiber and cooperative multitasking
Fiber is the thread of execution. It is similar to a thread, but more lightweight and implements a cooperative multitasking primitive. This imposes the following properties on us.
- More than one task is not being executed at a time.
- The system lacks a scheduler. Any fiber must voluntarily surrender.
The absence of a scheduler and concurrently executing tasks reduces the consumption of parasitic costs and improves performance. All this together makes it possible to build an application server. You can exit Tarantool to the outside world.
Tarantool has libraries for working with both networking and data. You can use it as a familiar programming language, similar to Python, Perl, JavaScript, and solve problems that are not related to the database at all.
Inside Tarantool there are functions, inside the application server itself, for working with the database. Over the course of the development of Tarantool, the platform has evolved over this application server. We mean the following in the term platform.
The platform is basicallyin-memory database and embedded application server. Or vice versa, an application server plus a database. But Tarantool also comes with tools for replication, for sharding; tools for clustering and managing this cluster, and connectors to external systems.
Total:
- Fiber is a lightweight execution thread that implements cooperative multitasking
- The next task is performed after the current one announces the transfer of control
- Applications server
- Event loop with fibers
- Non-blocking socket work
- Collection of Networking and Data Libraries
- Functions for working with the database
- Tarantool platform
- In-memory database
- Built-in application server
- Clustering tools
- Connectors to external systems
Database functionality
We use tapes to store data. They are tuples. It is an array with data that is not typed. Tuples or taples are combined into spaces. Space is essentially just a collection of tapes. The analogue from the world of SQL is a table.
Tarantool has two storage engines. You can define different spaces for storage in memory or on disk. To work with data, a primary index is required. If we create only the primary index, Tarantool will look like key-value.
But we can have many indexes. Indexes can be composite. They can consist of several fields. We can select by partial match with the index. We can work on indices, that is, a sequential iteration over the iterator.
Indexes come in different types. By default, Tarantool uses the B + * tree. And then there is hash, bitmap, rtree, functional indexes and indexes on JSON paths. All this diversity allows us to use Tarantool quite successfully where relational databases are suitable.
Tarantool also has an ACID transaction mechanism. A single threaded data access device gives us the ability to achieve the serializable isolation level. When we refer to the arena, we can read from it or we can write into it, i.e. make data modifications. Everything that happens is executed sequentially and exclusively in one thread.
Two fibers cannot run in parallel. But if we are talking about interactive transactions, then there is a separate MVCC engine. It allows you to perform serializable transactions that are already interactive, but you will have to additionally handle potential transaction conflicts.
In addition to the Lua access engine, Tarantool has SQL. We have often used Tarantool as a relational storage. We concluded that we will design the storage according to relational principles.
Where tables were used in SQL, we have spaces. That is, each line is represented by a tap. We defined a schema for our spaces. It became clear that you can take any SQL engine and just map primitives and execute SQL on top of Tarantool.
In Tarantool, we can call SQL from Lua. We can use SQL directly, or from SQL we can call what is defined in Lua.
SQL is a complementary mechanism, you can use it, you don't need to use it, but it is a pretty good addition that expands the possibilities of using Tarantool.
Total:
Data storage primitives
- tapl (tuple, string)
- space (table) - collection of tapes
- engine:
- memtx - the entire amount of data fits into memory and a reliable copy on disk
- vynil - stored on disk, the amount of data may exceed the amount of memory
- primary index
Indexes
- maybe a lot
- composite
- index types
- tree (B⁺ *)
- hash
- bitmap
- rtree
- functional
- json path
Transactions
- ACID
- Serializable (No-yield)
- Interactive (MVCC)
SQL & Lua
- TABLE: space
- ROW: tuple
- Schema: space format
- Lua -> SQL: box.execute
Comparison with other systems
To get a good understanding of Tarantool's place in the DBMS world, we'll compare it with other systems. You can compare a lot with someone, but I am interested in four main groups:
- In-memory platforms
- Relational DBMS
- Key-value solutions
- Document Oriented Systems
In-memory platforms
GridGain, GigaSpaces, Redis Enterprise, Hazelcast, Tarantool.
How are they similar? In-memory engine, in-memory database, plus some application runtime. They allow you to flexibly build cluster systems for different amounts of data.
In particular, this is the use in the role of Data Grid. These platforms are aimed at solving business problems. Each grid, each in-memory platform is built on its own architecture, while they belong to the same class. Also, different platforms have a different set of tools, because each of them is aimed at a different segment.
Tarantool is a general purpose, segmentless platform. This gives broader opportunities and a range of business scenarios to be solved.
Relational databases
Now let's compare the Tarantool in-memory database engine with MySQL and PostgreSQL. This allows you to position the engine itself, in isolation from the application server and even more so from the platform.
Tarantool is similar to relational databases in that it stores data in tabular form (in tapes and spaces). Indexes are built to the data, just like in relational databases. In Tarantool, you can define a schema, there is even SQL, with which you can work with data.
But it is the SQL schema that distinguishes Tarantool from classic relational databases. Because even though SQL is there, you don't have to use it. It is not the main tool for interacting with the database.
Tarantool's schema is not strict. You can only define it for a subset of your data.
In conventional relational databases, an in-memory table is not persistent storage used for some kind of fast operations. In Tarantool, the entire amount of data fits into memory, is served from memory, and at the same time is reliable and persistent .
This is so important that I will write again - Tarantool stores the entire data set in memory and at the same time the data is safely saved to disk .
Key-value DB
The next class to compare with is key-value - memcached, Redis, Aerospike. How is Tarantool similar to them? It can work in key-value mode, you can use exactly one index. In this case, Tarantool behaves like a classic key-value store.
For example, Tarantool can be used as a drop-in replacement for memcached. There is a module that implements the corresponding protocol, and in this case we completely imitate memcached.
Tarantool is similar in its in-memory architecture to Redis, it just has a different style of data description. Wherever Redis is applicable for architectural scenarios, you can take Tarantool. The battle of these yokozun is described in the article at the link [5].
The difference between Tarantool and key-value databases is precisely the presence of secondary indexes, transactions, iterators and other things inherent in relational databases.
Document-oriented databases
As a fourth category, I would like to cite document-based databases. The most striking example here is MongoDB. Tarantool can also store documents. Therefore, we can say that Tarantool has its own way, including a document-oriented base.
Tarantool's internal storage format itself is msgpack. This is such a binary JSON. It is almost equivalent to the format used by Mongo. This is BSON. It has the same compactness. It reflects the same data types. In doing so, you can index the content of these documents. Read more about msgpack in a recent article [6].
Also included with Tarantool is the Avro Schema library. It allows documents of a regular structure to be parsed into lines and these lines are already stored directly in the database.
But Tarantool was not originally conceived as a document-oriented database. This is a bonus for him and the ability to store some part of the data as a document. Therefore, it has slightly weaker indexing mechanisms in comparison with the same Mongo.
Bonus round: column bases
Such questions sometimes arise. The answer here is simple - Tarantool is not a columnar database (who would have thought). Scripts that are good for columnar bases do not work with Tarantool. It can be noted that they complement each other extremely well.
I think many of you are familiar with Click House. This is a great analytical solution. This is a column base. Moreover, ClickHouse does not like microtransactions. If you send a lot of small transactions to it, it will not reach its maximum throughput. You need to send data in batches to it.
At the same time, microtransactions can and should be sent to Tarantool. He is able to accumulate them. Since it has various connectors, it can accumulate these transactions and send them to a ClickHouse-type storage as a batch. Yin and Yang.
Total:
| vs | ||
|---|---|---|
| In-memory |
|
|
|
|
|
| Key-value |
|
|
| - |
|
|
|
|
We'll start with examples of when Tarantool shouldn't be used. The main scenario is analytics, aka OLAP, including using SQL.
The reasons for this are quite simple. Tarantool is basically a single threaded application. It has no data access locks. But if one thread is executing long SQL, no one else will be able to run while it is running.
Therefore, analytical databases usually use multi-threaded data access mode. Then, in separate threads, you can cheat something. In the case of Tarantool, one thread is faster than many other solutions. But it is one, and there is no way to work with data from several threads.
But if you want to build some pre-calculated analytics, for example, you know that you will need cumulative data like this. You have a stream of data, and you can tell right away that you need some kind of counters. This prefigured analytics builds well on Tarantool.
When to use
The main scenario comes from its historical heritage, from what it was created for. Many small transactions.
These can be sessions, user profiles and everything that has grown out of it during this time. For example, Tarantool is often used as a vector store next to Machine Learning, because it is convenient to store it there. It can be used as high-loaded counters that pass all traffic through themselves, anti-brute force systems.
Subtotal:
Examples of bad use
- Analytics (OLAP)
- Incl. using SQL
Examples of good use
- High Frequency Microtransactions (OLTP)
- User profiles
- Counters and signs
- Data cache proxy
- Queue brokers
Conclusion and conclusions
Tarantool is persistent and has the ability to walk to many other systems. Therefore, it is used as a cache proxy for legacy systems. To heavy, complex ones, both in write true proxy and write behind proxy.
Also, the architecture of Tarantool, the presence of fibers in it and the ability to write complex applications makes it a good tool for writing queues. I know of 6 queue implementations, some of them are on GitHub, some of them are in private repositories or somewhere in projects.
The main reason for this is the guaranteed low latency for access. When we are inside Tarantool and come for some data, we give it from memory. We have fast, competitive access to data. Then you can build mashups that run right next to the data.
Try Tarantool on our website and come with questions to the Telegram chat .
Links
- S3 architecture: 3 years of evolution for Mail.ru Cloud Storage
- Video - Tarantool as a foundation for high-load applications
- Tarantool: how to save a million dollars on a database on a high-load project
- https://github.com/luafun/luafun
- Tarantool vs Redis: what in-memory technologies can do
- Advanced MessagePack Features