
Task - "Analyze commercial chat messages for ignoring the client's question by the company's manager"
At the entrance: a log of chats with a client of the company in csv format:
departure date |
Message |
Who sent |
Request number |
yyyy-mm-dd hh-mm-ss |
Text1 |
Sender1 |
Number 1 |
yyyy-mm-dd hh-mm-ss |
Text2 |
Sender2 |
Number 2 |
yyyy-mm-dd hh-mm-ss |
Text3 |
Sender3 |
Number 3 |
yyyy-mm-dd hh-mm-ss |
Text4 |
Sender4 |
Number 4 |
yyyy-mm-dd hh-mm-ss |
textN |
senderN |
NumberN |
Solution plan:
Data preparation
Choosing a tool to identify similar messages within each chat
Analysis of the obtained results
Summarizing
Data preparation
The following tools are used:
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import tqdm
import pandas as pd
import numpy as np
import re
import time
from nltk.tokenize import sent_tokenize, word_tokenize
import pymorphy2
morph = pymorphy2.MorphAnalyzer(lang='ru')
from nltk import edit_distance
import editdistance
import textdistance
from jellyfish import levenshtein_distance
CSV DataFrame. , . , / .
df = pd.DataFrame()
counter = 1
for path_iter in PATH:
print(path_iter)
df_t = pd.read_csv(path_iter, sep=';', encoding='cp1251', dtype='str', engine = 'python')
if counter == 1:
df_t[' '] = pd.to_datetime(df_t[' '], format='%d.%m.%y %H:%M')
else:
df_t[' '] = pd.to_datetime(df_t[' '], format= '%Y-%m-%d %H:%M:%S')
df = df.append(df_t)
counter += 1
df.sort_values(by=[' ', ' '], inplace=True)
df.reset_index(drop=True, inplace=True)
print(' DF, rows =', len(df))
df.head()
>>>
DF, rows = 144584

, . .
df[' '].value_counts()
>>>
['AGENT'] 43137
['CONSULTANT'] 33040
['USER'] 29463
['MANAGER'] 21257
[] 13939
['BOT'] 3748
Name: , dtype: int64
print('- ', len(set(df[' '].tolist())))
>>>
5406
– 25 .
df[' '].value_counts().hist(bins = 40)

: , , , . «.jpg».
def filter_text(text):
'''
,
.
, ,
'''
text = text.lower()
if len(re.findall(r'[\w]+', text)) == 1:
#print(re.findall(r'[\w]+', text), '---', len(re.findall(r'[\w]+', text)))
return ''
# ".jpg"
text = re.sub(r'(.+[.]jpg)|(.+[.]pdf)', '', text)
text = [c for c in text if c in '- ']
text = ''.join(text)
return text
df['work_text'] = df.apply(lambda row: filter_text(row['']), axis = 1)
.
df['work_text'] = df.apply(lambda row: re.sub(r'\s+', ' ', row['work_text']) , axis = 1)
/ :
STOP_WORDS = [
'-', '--', '-', '-', '-', '-', '-', '-', '-', '-', '-', '-', '-', '-', '', '-', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '-', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'-', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'-', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '','',''
]
#DF
df_users = df[df[' '] == '''['USER']''']
[df_users.work_text.replace(x, '', regex=True, axis = 1, inplace=True) for x in STOP_SENTS]
,
def normalize_text(text):
'''
,
STOP_WORDS - ,
,
,
'''
ls = list()
for word in word_tokenize(text, language='russian'):
if word not in STOP_WORDS:
ls.append(morph.parse(word)[0].normal_form)
norm_text = ' '.join([x for x in ls])
return norm_text
df_users['clear_text'] = df_users.work_text
df_users['clear_text'] = df_users.apply(lambda row: normalize_text(row.clear_text), axis = 1)
:
def get_edit_distance(sec_posts, val_leven):
'''
sec_posts - list
val_leven - :
ratio_ed = editdistance /
'''
ls = []
len_sec_posts = len(sec_posts)
sec_posts_iter = 0
for i in sec_posts:
sec_posts_iter += 1 # ,
for k in sec_posts[sec_posts_iter:]:
#ed = edit_distance(i, k)
#ed = textdistance.levenshtein(i, k)
#ed = levenshtein_distance(i, k)
ed = editdistance.eval(i, k)
if len(k) == 0:
ratio_ed = 0
else:
ratio_ed = ed / len(k)
if len(k) !=0 and len(i) != 0 and ratio_ed <= val_leven:
ls.append([i, k, ratio_ed, ed])
#list [post1, post2, ratio_ed, ed]
return ls
CURRENT_LEV_VALUE = 0.25
# :
number_orders = set(df_users[(df_users[' '] == '''['USER']''')][' '].tolist())
# , :
all_dic = {}
for i_order in tqdm.tqdm(number_orders):
posts_list = df_users[(df_users[' '] == '''['USER']''') & (df_users[' '] == i_order)]['clear_text'].tolist()
all_dic[i_order] = get_edit_distance(posts_list, CURRENT_LEV_VALUE)
– editdistance.
29463 . import edit_distance, import editdistance, import textdistance, from jellyfish import:

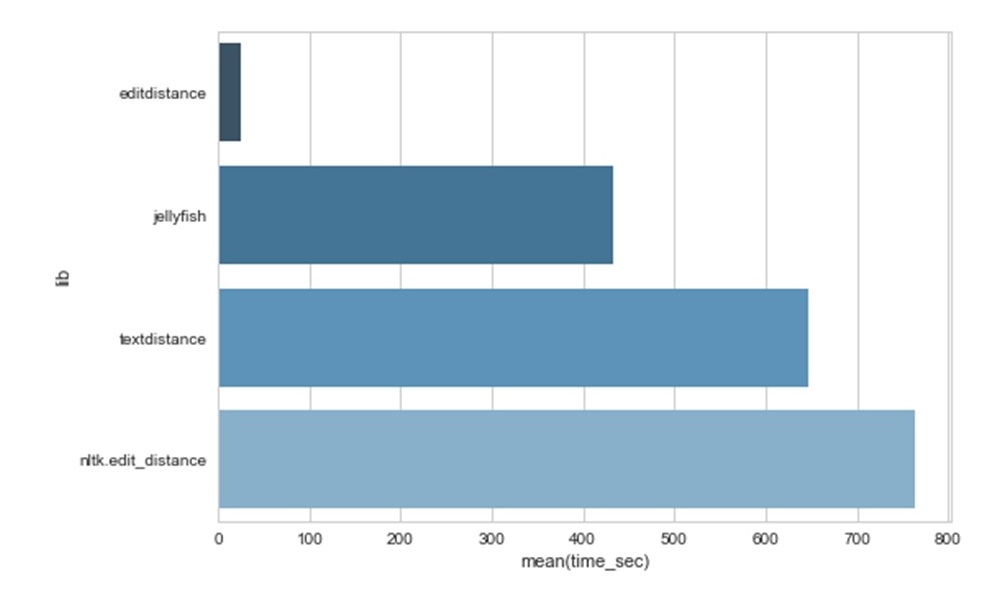
editdistance 18 31 .
CURRENT_LEVEN, — editdistance (text1, text2)/ (text1).
CURRENT_LEVEN . -. . CURRENT_LEVEN 0.25.

dataframe :
df_rep_msg = pd.DataFrame(ls, columns=['id_order', 'clear_msg', 'clear_msg2', 'ratio_dist', 'ed_dist'])
df_rep_msg['id_rep_msg'] = df_rep_msg.reset_index()['index'] +1
df_rep_msg.head()

:
df1 = df_rep_msg[['id_order','clear_msg','ratio_dist','ed_dist', 'id_rep_msg']]
df2 = df_rep_msg[['id_order','clear_msg2','ratio_dist','ed_dist', 'id_rep_msg']]
df2.columns = ['id_order','clear_msg','ratio_dist','ed_dist','id_rep_msg']
df_rep_msg = pd.concat([df1, df2], axis=0).sort_values(by=['id_order'], ascending=[True])
del df1
del df2
df_rep_msg.drop_duplicates(inplace=True)
df_rep_msg.head(10)

df_users_rep_msg
df_users_rep_msg = pd.merge(
df_users, df_rep_msg, how='left',
left_on=['clear_text',' '],
right_on=['clear_msg','id_order']
)
df_users_rep_msg[df_users_rep_msg.clear_msg.notnull()][
[' ', '', ' ', ' ', 'clear_msg', 'ratio_dist', 'ed_dist','id_rep_msg']
].head()

, 6
count_ser = df_users_rep_msg[df_users_rep_msg.id_rep_msg.notnull()]['id_rep_msg'].value_counts()
filt = count_ser[count_ser > 4]
filt

df_users_rep_msg[df_users_rep_msg.id_rep_msg.isin(filt.index)][[' ','','id_order']]

, , , .
df_m = pd.merge(
df, df_users_rep_msg[df_users_rep_msg.id_rep_msg.notnull()],
how='left',
left_on = [' ',' ', ' ', ''],
right_on =[' ',' ', ' ', '']
)
df_m = df_m[[' ', '', ' ', ' ','clear_msg',
'ratio_dist', 'ed_dist', 'id_rep_msg']]
df_m.loc[18206:18216]

df_temp = df_m[df_m.id_rep_msg.notnull()][['id_rep_msg']]
df_temp['id_row'] = df_temp.index.astype('int')
df_temp.id_rep_msg = df_temp.id_rep_msg.astype('int')
index_arr = df_temp.groupby(by = 'id_rep_msg')['id_row'].agg([np.min, np.max]).values
index_arr[0:10]
>>>
array([[ 36383, 36405],
[108346, 108351],
[ 12, 43],
[ 99376, 99398],
[111233, 111235],
[121610, 121614],
[ 91234, 91252],
[ 11963, 11970],
[ 7103, 7107],
[ 53010, 53016]], dtype=int64)
df_m.loc[index_arr[194][0]:index_arr[194][1]]
In the example below, you can see how the request was intercepted by a bot / automated system, the client is not ignored
df_m.loc[index_arr[194][0]:index_arr[194][1]]

Checking the rest of the cases
#
results = {'_':0, '_':0, '___':0}
results['___'] = len(index_arr)
for i in range(len(index_arr)):
if len(set(df_m.loc[index_arr[i][0]:index_arr[i][1]][' '].tolist()) - set(["['USER']"])) > 0:
results['_'] += 1
elif len(set(df_m.loc[index_arr[i][0]:index_arr[i][1]][' '].tolist()) - set(["['USER']"])) == 0:
results['_'] += 1
print(' :', round(100*(results['_']/results['___']), 2), '%')
results

Number of processed messages:
N = 1
anw_yes = (236)
anw_no = (103)
ind = np.arange(N)
width = 0.35
p1 = plt.bar(ind, anw_yes, width)
p2 = plt.bar(ind, anw_no, width, bottom=anw_yes)
plt.ylabel('_')
plt.title(' ')
plt.xticks(ind, (''))
plt.yticks(np.arange(0, 500, 50))
plt.legend((p1[0], p2[0]), ('_', '_'))
plt.show()

Conclusion
Using the NLP model based on the Levenshtein editorial distance measurement, it was possible to reduce the number of checked chats from 5406 units. up to 339 units Of these, identify high-risk chats - 103 units. Define and use in calculations a high-performance library for calculating the editing distance between texts, which allows you to scale the check to large amounts of information.