Blooming video under the hood
I continue to talk about my unusual hobby. My hobby is the algorithmic transformation of ancient black and white video into material that looks modern. My first job is described in this article . Time has passed, my skills have improved, and now I am not laughing at the "Zoom and enhance" meme .

The pastime may seem strange, but it is true that it is enjoyable. Maybe it's the ability to be a wizard who turns the ashes of the past into fire with the help of technomagic, or maybe the reason is in a lot of intellectual puzzles that do not have a ready-made solution, maybe it is compensation for a lack of creative self-expression, maybe all together. With each new video, the process becomes overgrown with details, the number of third-party tools and scripts involved is growing.
It is necessary to clarify that we are not talking about manual restoration and coloring, which require tons of Indians and kilograms of money, but about the use of autotune algorithms (often referred to as "AI", "neural networks").
Once my works were slightly better in clarity and color than similar works of other amateurs, but now the arsenal of tools used has expanded so much that the quality of the final result depends only on the time invested.
▍Small story
From the outside, the process of automatic color fading of the video is not perceived as something abstruse, because it is obvious that it is enough to download a certain program and throw a video recording into it, and all the complex work has already been done by the one who designed the color fading algorithm and spent electricity on training.
Let me tell you now about how the revolutionary Deoldify color fading algorithm came about . Even if you are into machine learning, it is not a fact that you know who Jeremy Howard is . His professional career began as a hired consultant, 20 years ago he was engaged in what is now called Data Science, that is, extracting profit from data using mathematics.
The sale of a couple of startups allowed him to think about deliberately making a positive contribution to the development of humanity. After moving to Dolina, he joined the crowd of top machine learning specialists, and in 2011 he became the best participant in the Kaggle competition.
A major turning point came in 2014, when his project to automatically detect medical abnormalities on radiographs showed results that surpassed the quality of the work of experienced doctors. At the same time, the project did not represent anything grandiose in terms of the invested intellectual and material resources, and the final training was carried out the night before the presentation. A typical working project, which by its existence symbolized a transition point in technical progress.
Jeremy has a clear understanding that such a powerful tool can be a source of growth in any area. The main problem was (and is) that the number of specialists in self-learning systems is incomparable with the number of projects in which their abilities could be used. From his point of view, it would be much more effective to give this tool to everyone. This is how the Fast.Ai project appeared , which is a symbiosis of a code and a training course. The code on the one hand makes Pytorch much easier to use (a tool for constructing machine learning algorithms), and on the other hand, it contains a lot of ready-made techniques that professionals use to increase the speed and quality of learning. The curriculum is structured from top to bottom, first students are taught to use off-the-shelf pipelines, then Jeremy shows how each element of the pipeline can be written from scratch, starting with a live demo in an Excel sheet of the key algorithm underlying all of Deep Learning. The goal of the Fast.Ai project is to teach a specialist from any field to solve typical problems on typical architectures (of course, if you have programming skills). Miracles do not happen, the level of skills after such training does not exceed the level of "round kati - square vert", but even this is enough to solve work problems at a new level, inaccessible to colleagues.
In the Fast.Ai tutorial, one of the topics is devoted to the use of the UNet architecture , which is focused on the reinterpretation of images. For example, this architecture can be trained to generate realistic photographs from images captured with a thermal imager, or to contrast anomalies in images. Generally speaking, such an architecture, by its known form and properties, makes it possible to predict the presence of properties in the form, the identification of which was the goal of training.
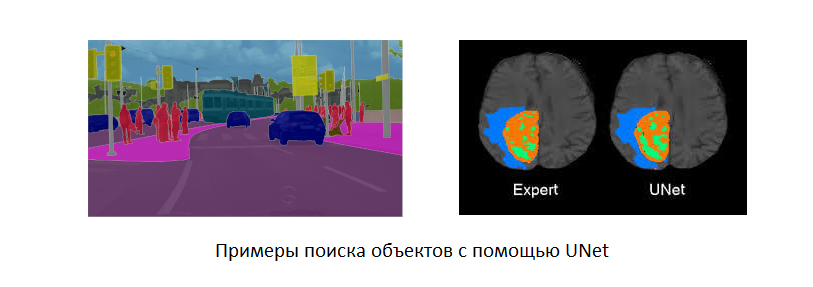
As homework, the students of the course were encouraged to use UNet to solve any interesting problem. A certain Jason Antic became interested in converting black and white photographs to color. His experiments showed that such an architecture produces adequate results and there is significant potential for further development. This is how the Deoldify project was born, which, with the assistance of Jeremy Howard himself, grew to a finished product and eventually blew up the Internet. The author made the first version available to everyone, and he himself began to develop a closed commercial version, which in a limited form can be used on the genealogical project MyHeritage.com (requires registration, several photos are free).

▍ « »
The main problem with cutting edge open source machine learning projects is that user friendliness is usually to the left of zero. The author of the project focuses on the learning pipeline, he needs the results of the algorithm solely for presentation to the community, which is normal, since the goal of such projects is self-promotion and contribution to research. Self-completion of projects by the user is the norm. In order not to go far: before processing a video, it must be decoded, processed each frame and the resulting compression into a video file, if one video is processed with several tools, then after successive compression you can forget about the quality. Each new tool has to be redone to work with a stack of pictures.But what if in the tool at the pipeline level the use of no more than 8 frames per run is embedded? The algorithm is sufficient for demonstration, but not for practical purposes. You will have to write an external wrapper to run it multiple times, because it is unlikely that you will be able to change someone else's pipeline without losing compatibility with the pretrained state of the algorithm. And, of course, academic writers don't really care about optimization. There is one project that refused to work with images larger than a matchbox, after optimization it began to require 5 times less video memory and now it can handle FullHd.that it will be possible to change someone else's pipeline without losing compatibility with the pre-trained state of the algorithm. And, of course, academic writers don't really care about optimization. There is one project that refused to work with images larger than a matchbox, after optimization it began to require 5 times less video memory and now it can handle FullHd.that it will be possible to change someone else's pipeline without losing compatibility with the pre-trained state of the algorithm. And, of course, academic writers don't really care about optimization. There is one project that refused to work with images larger than a matchbox, after optimization it began to require 5 times less video memory and now it can handle FullHd.
You can list the jambs that have been encountered for a long time, it is enough to dwell on the fact that for the operation of any algorithm, the installation of instrumental libraries is necessary, sometimes it may take 2-3 days of experiments before the libraries stop conflicting with each other (even if there is a list of exact versions, there are many reasons why will have to google for a long time).
▍A minute of beauty
Choosing a material for colorization is not that easy. On the one hand, the content should be interesting to me, on the other hand, the long advertising film of the Diesel company, saturated with technical details, is unlikely to interest a wide audience, on the third hand, there are restrictions in the choice due to copyright. New variants come from memory or in the course of searching for specific records. My last works are dedicated to the Russian ballerina Anna Pavlova. Enough has been written and said about her, many photographs have survived, but since her professional activity is associated with movement in time and space, the most interesting witness is the film. Unfortunately, some of the surviving records are unknown to the general public, and what is now being searched for is of an absolutely disgusting quality. What is interesting about the figure of Anna Pavlova,so it is literally a figure. She can be considered the prototype of the standard of the modern ballerina, perhaps it will not be a discovery for you that, at the end of the 19th century, thinness was still collectively perceived as a sign of illness or poverty, of course, among wealthy people there were different figures, but in general, fatness was perceived as a marker of a successful life. Women bursting with health often performed on the theater stage, here are photos of three stars of that time.Women bursting with health often performed on the theater stage, here are photos of three stars of that time.Women bursting with health often performed on the theater stage, here are photos of three stars of that time.

In one of my works, you can even see how it looked. Spectators who do not have a good understanding of history hardly take such a picture seriously, although the most advanced inhabitants of our planet will surely find a positive here.
Returning to Anna Pavlova: there are several films depicting a ballerina in dance. They exist in good quality, but they are not publicly available. But in the course of the search, to my surprise, I discovered a whole full-length film in which our ballerina played the main role. At the beginning of the film, a number with a dance that has nothing to do with the plot is inserted, so it is quite appropriate to consider it a separate video, which I have been working on.
▍Problems at the start
Decode the original video into a series of PNG files. We look at the resulting images and notice that there are frames that repeat the previous ones.
This is a standard story, because at the dawn of cinematography, a shooting speed of 12-19 frames per second (hereinafter fps) was used to save film. In the later analog era, when 99% of footage was 24-25 fps, old tapes were copied frame-to-frame, resulting in faster playback. Therefore, in the minds of the majority, the old chronicle is firmly associated with indistinct rushing little men. The truth is that black and white film originals retain very well, even better than color ones, and have a resolution between DVD and FullHD. All that you could see in most cases was shoddy copies, re-shot from the projection to the screen. Although many films have survived only on such copies (losses are due to the human factor), the number of originals that have survived is still significant.Only a select few have access to the originals, fortunately, these days computer image processing allows unlimited replication of scanned high-quality copies of originals, clean up defects and reproduce material at a normal frame rate.
There are two separate problems with low frame rates. Firstly, it is non-standard, if any playback speed can be used on a personal computer, then there are many cases when it is necessary to adhere to the 24-30 fps range. The easiest way to correct the frame rate is to repeat the last one every 3-4 frames. At the same time, the speed of movement of objects becomes natural, but the picture is perceived as twitchy, this is actually the second problem. In 2021, technologies will allow you to make a smooth picture by interpolating frames. Frame interpolation technology in TVs and software video players began to be found around 2005. Due to mathematical algorithms, two adjacent images are mixed so that during playback there is a feeling of smooth movement in the frame. It works well for 24 fps,since the difference between frames is rarely significant. But for 12-19 fps, such algorithms are not suitable: they draw a blurry double image or crazy artifacts. This problem is more successfully solved by self-learning algorithms that are able to remember exactly how to draw an intermediate image for different movements of different types of objects.
In modern re-releases of films of the silent film era, the use of interpolation is not yet used, respectively, there are repeated frames in our video, and if they are not removed, then when it comes to frame interpolation, it will turn out to be nonsense, which means it is necessary to remove unnecessary ones.
▍Unexpected twist
Remove this with pens - you will be tortured, swam, we know. We run the script for detecting identical frames, the script falls out with the error "Many matches in a row". And, well, of course: the frames are too dark, the search rakes the same and different frames into one heap. Run the dynamic range normalization script, which automatically makes contrasting borders, black leads to black, white to white, and then returns to the place the shades of gray that are lost during such manipulations.

We start the duplicate search again, the process is now more confident, but after deleting unnecessary frames, something new is found. With some periodicity, there is a repetition of frames in the reverse order. We launch the original video and watch carefully, wow, they really used a trick that uses the inertia of vision, and the image is perceived less twitchy than with ordinary duplication of frames.
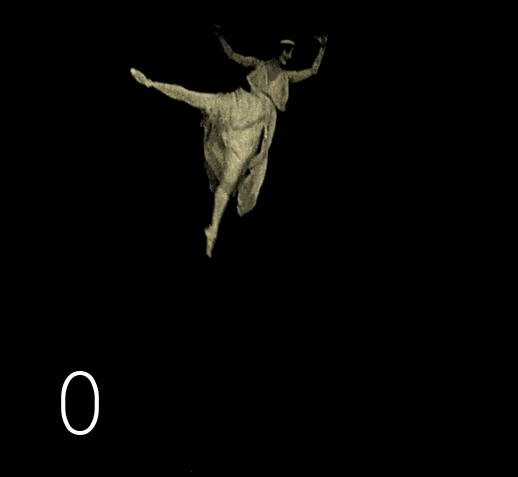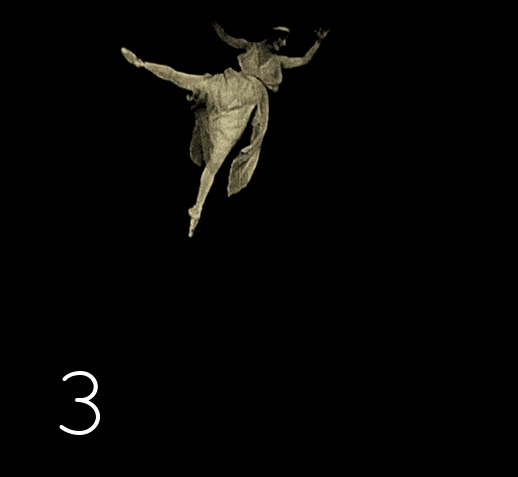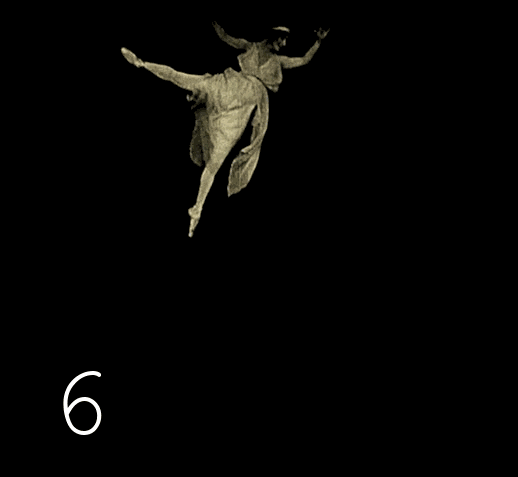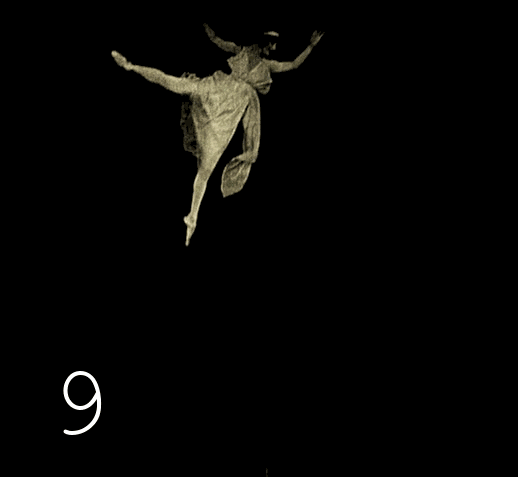

We change the script from searching for identical frames in a row to - searching for identical frames through one intermediate one . We check the results - again a surprise: there is a repetition in two frames. After checking the third version of the script, the surprises end.
The problem of removing extra frames suddenly became very serious. On such dark and not saturated with details, you cannot trust the automatic search for duplicates, it will make mistakes repeatedly, skipping the unnecessary and deleting the necessary. We run the search for all types of takes on another episode of the film, in which the number of errors will be minimal. In the case of a simple repetition, by highlighting the takes in the file manager, you can understand the repetition scheme and delete unnecessary files programmatically.
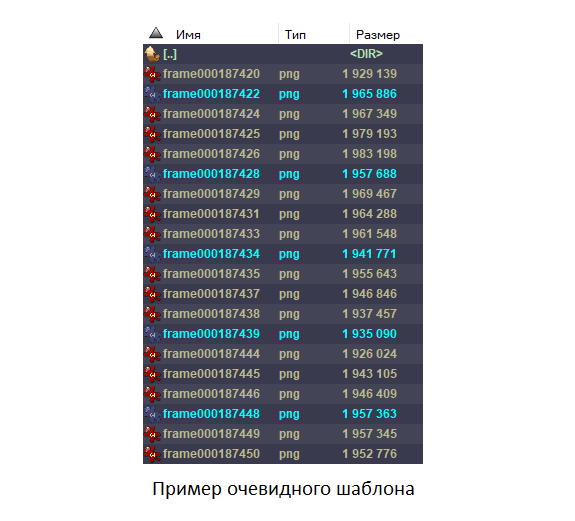
In this case, the pattern looked randomly periodic, small pieces are repeated, but in general the essence is unclear. So what's now? Either abandon the whole idea, or reverse the repetition algorithm.
Changing the duplicate search script, now labels will be added to the file names depending on the type of duplication. We transfer the entire list of files to Excel and leave only the labels, turn the column into a row and fly out of the allowable number of columns, now we have to divide it into two sheets. We highlight duplicated frames of the same type in one color, which will allow us to use the biological template analyzer.

Short repetitions are grouped. We check how accurately a long group is repeated. The groups are similar, but there are slight differences. This is a fiasco. There are several possible reasons for this picture: random changes were deliberately made, or several algorithms for completing frames were used, or the content of frames is taken into account, or the method uses a non-intuitive function. Writing a much longer sequence of repetitions for calculus felt like overkill.

You will have to remove the noise with your hands using a sample. We run the duplicate search script on the episode of interest to us, and load the sequence of frames into the Excel, paint it, and insert a template of a long sequence next to it. We put down the marking where it seems unambiguous, we remove the incorrect marking. Then we guess where which frames should be, and now most of the picture is restored. There are a few unclear places left. We put down marks exactly according to the template or by intuition. Of course, somewhere there will be errors, but somewhere we will find ourselves that against the general background of the correct sequence it is no longer critical, especially since in the old chronicle almost always some frames are lost, and there is no point in squeezing out the absolute ideal in this case.
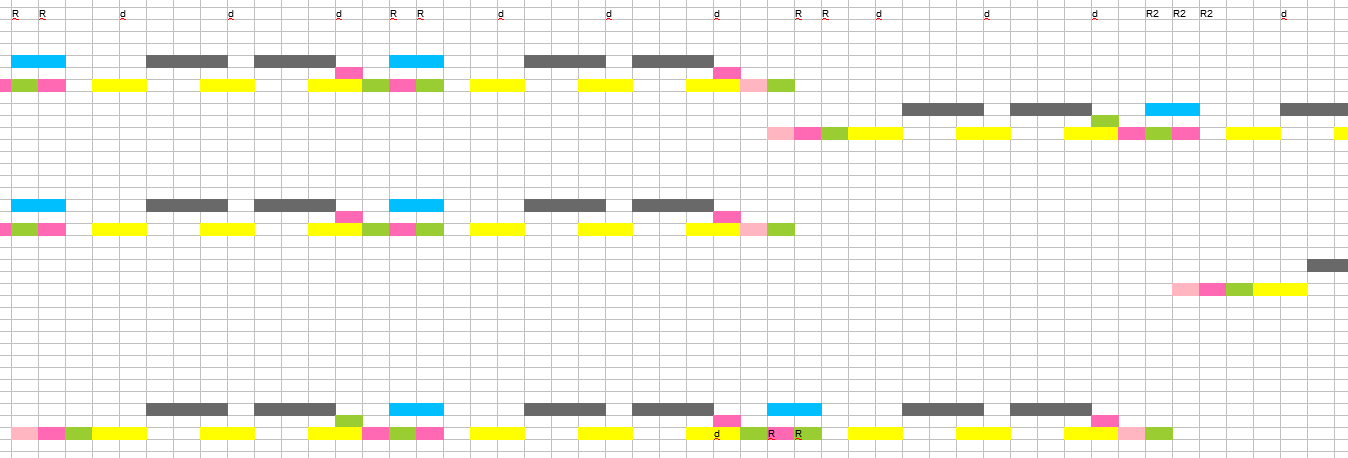
Using the final list, we remove the unnecessary, check it and voila, the problem looks 9 out of 10 solved.
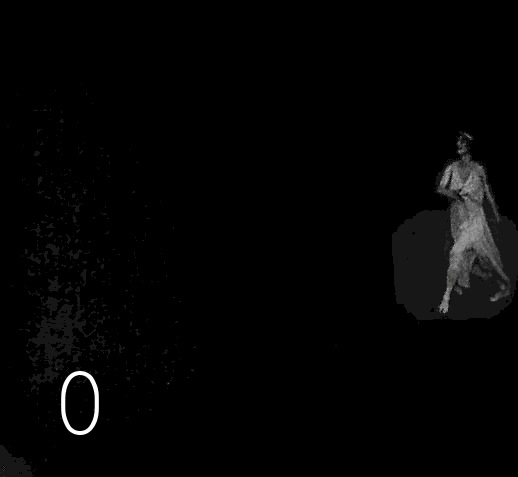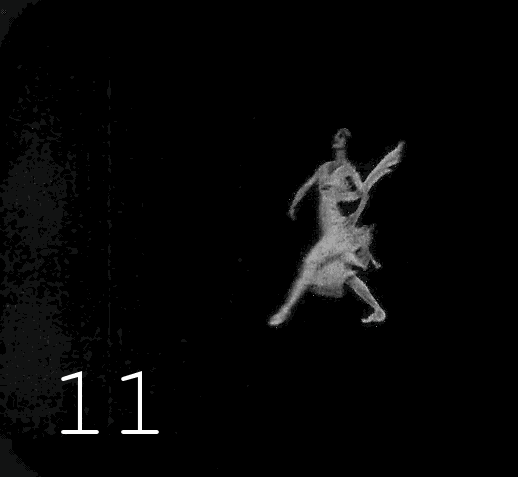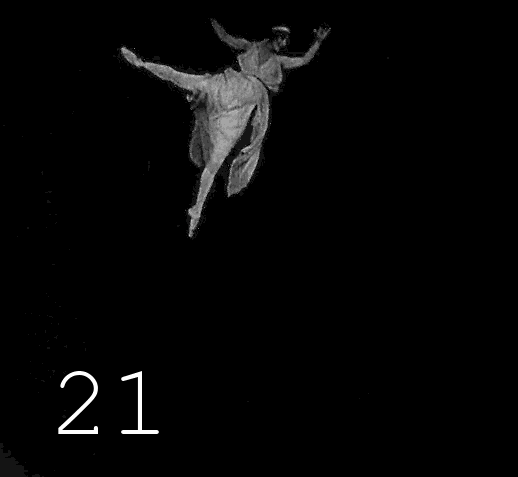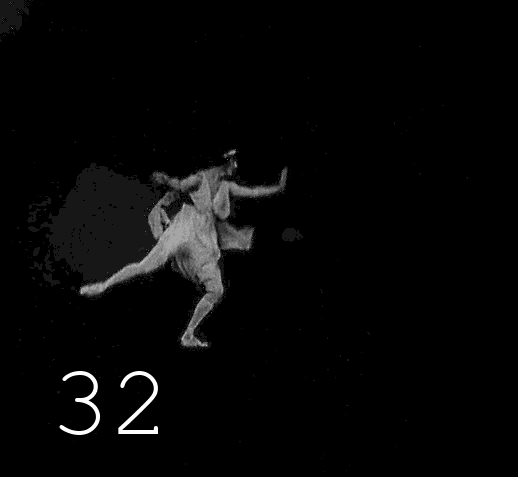
▍
This is followed by 17 black magic operations, during which 17 folders are formed on the disk containing video frames after each manipulation. In addition to the discoloration itself, automatic correction of unsuccessfully discolored frames is performed, a significant increase in the clarity of the image, the restored image returns to "analogy" (to get rid of the feeling of Photoshop), for all this, 5 different image enhancement tools are used, interconnected by scripts, which are poured back and forth luminance and color channels. The names of the tools will remain my professional secret, sorry, too much work and time spent on collecting this zoo and modifying it. When I saw the results of Deoldify 2, it became clear to me that my desire to be the best in this area is meaningless,no matter how cool I squeeze the quality percentages, each new similar algorithm is many times superior to the old one. I gave up fading and plunged into Machine Learning in order to build my Deoldify, however, then a series of events happened that distracted me from this goal. As a result, I combined several ready-made projects into a common process, the results of which, at least somehow replace my failed colorization algorithm. Perhaps in the next article I will tell you how to use the colorizer from Google, if you can curb her appetite for memory, there will be a code and details.As a result, I combined several ready-made projects into a common process, the results of which somehow replace my failed colorization algorithm. Perhaps in the next article I will tell you how to use the colorizer from Google, if you can curb her appetite for memory, there will be a code and details.As a result, I combined several ready-made projects into a common process, the results of which somehow replace my failed colorization algorithm. Perhaps in the next article I will tell you how to use the colorizer from Google, if you can curb her appetite for memory, there will be a code and details.
To complete the work on the video, you need to try to remove the jambs, for this the professional Davinci Resolve video harvester is best suited . If you open the next picture separately, you can see the number of elements in the retouching chain. This design makes the background black, brings the colors closer to natural, fights with unnecessary colors, creates an imitation of a spotlight beam (hides minor traces of using correction).
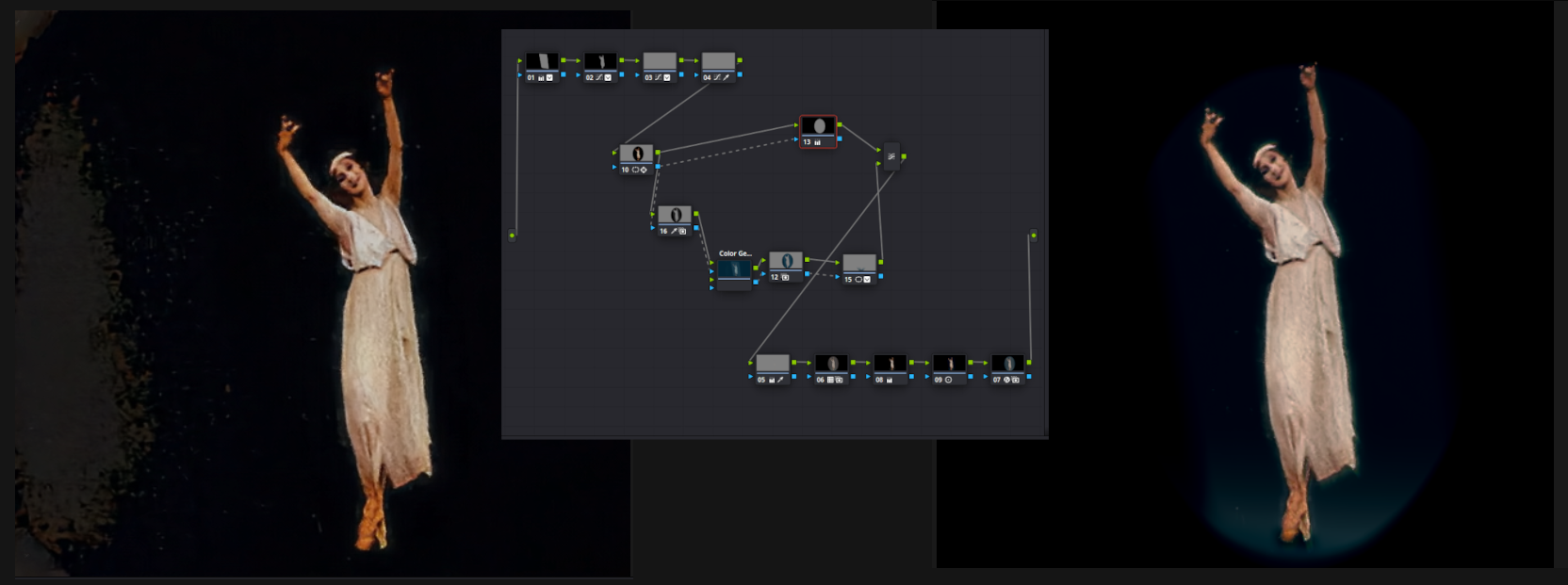
It remains to do frame interpolation, cosmetic upscaling to 2K, and now our video is ready. The original picture is too dark and there is no need to expect miracles, but now it is possible to consider the smooth movements of the dancer's clear figure.
The film itself contains many scenes with a relatively good picture, which makes it possible to assess how much algorithmic processing can improve the image. The frames of 2K resolution are too large for the article, therefore, the final frames reduced in 2 times are inserted next to the full frame of the original image.





▍Results
The dance plot contains 1251 frames (before interpolation), the work took 5 days .
Music added from Youtube free music library.
The film contains 19660 frames (before interpolation), 14 days were processed (only algorithms, manual retouching was not applied). With music it was more difficult here, at first there was a version assembled from pieces of the opera, which forms the basis of the film script, but due to copyright it was not possible to publish this version, I had to use suitable compositions from the first library found, they say it turned out better than the first time.
Computer characteristics: Amd Ryzen 3 1200, 4GB RAM, GTX 1060 3GB
▍- Links to my work:
Youtube Not.
Rutube Not.
Ps I could not resist, I colored.

