
In modern computational linguistics, understanding the meaning of what is written or said is achieved using natural language models (NLU). With the gradual growth of the audience of Salyut virtual assistants, the question arises of optimizing our services that work with natural language. To do this, it turns out to be advisable to use one strong NLU model to solve several word processing problems at once. In this article, we'll show you how you can use multitasking learning to improve vector representations and train a more general NLU model using SBERT.
Highly loaded word processing services solve a number of different NLP tasks:
- Recognizing intentions.
- Highlighting named entities.
- Sentimental analysis.
- Toxicity analysis.
- Search for similar queries.
Each of these tasks has its own specifics and, generally speaking, requires the construction and training of a separate model. However, it is impractical to maintain and execute a separate NLU model for each such task - the processing time of the request and the consumed (video) memory greatly increase. Instead, we use one strong NLU model to extract generic features from text. On top of these features, we apply relatively lightweight models (adapters), which solve applied NLP problems. At the same time, NLU and adapters can be executed on different machines, which makes it easier to deploy and scale solutions.

But how to make the features identified by the base NLU model universal enough so that a high-quality NLP model can be built on top of them? Let's figure it out.
By tradition, we present the implementation of our approach in Python 3 and TensorFlow 1.15. A complete step-by-step guide and code examples can be found here - Colab .
We also lay out in a publicly available an updated Russian model SBERT-NLU class BERT-large [427 million options.] Version Multitask : huggingface [tensorflow, pytorch] .
Multi-tasking learning. Why is this needed?
During the operation of NLU models, we found that the features allocated by models trained for one task (for example, NLI ) can be quite successfully reused for other downstream tasks (for example, for classification or sentimental analysis). To do this, a lightweight model (adapter), sharpened for solving a new problem, is trained on the vectors selected by the base model. This does not change the base model.
At the same time, the quality of such adapter models is usually still worse than if we trained our NLU model for each task. The reason is that the new data is only used for adapter models and does not improve the base model. Multitask learning helps us to cope with this.
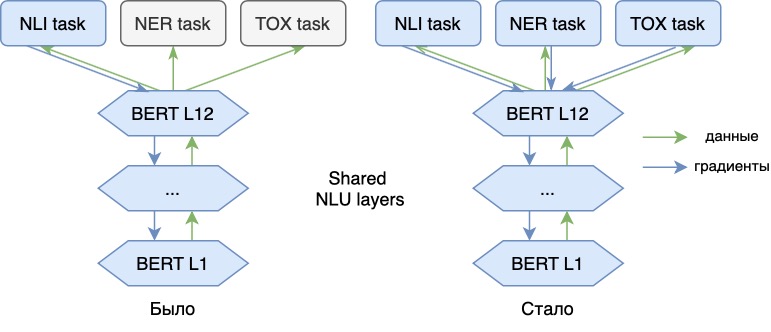
Now we train the language model not only on the main NLI problem, but also on additional ones (NER, toxicity analysis). Adding new tasks allows us to add new "meanings" to the vectors of our model, making them more universal. Thus, the model will be able to reflect in its vectors information, for example, about the emotional shades of speech of a phrase or about the part of speech of each word in the text. With vector representations of such a model, these problems can be solved more efficiently.
0. Experiment
As an example, consider teaching NLU on three tasks:
- Sentence representation (NLI).
- Named entity recognition (NER).
- Sentiment analysis.
To teach the main task of vectorization of sentences, we, like last time , use a dataset for Natural Language Inference , containing pairs of sentences with labels that indicate a consequence ("entailment"), a contradiction ("contradiction") or the absence of a semantic connection (" neutral ") between sentences. For this data, based on the BERT model, we will learn such a vector representation that the similarity between the corresponding pairs of sentences will be greater than the similarity between conflicting or neutral to each other.
We will train the NER head using the datasetfrom the kaggle platform. This model will assign each token in the proposal being processed to one of several IOB named entity types . Its task is a multi-class classification.
For the problem of sentiment analysis, let's take the data from the Tweet Sentiment Extraction competition . The essence of this contest is to predict the emotional color of comments on twitter posts. There are three classes in the dataset - positive, neutral and negative color of the replica. For this example, we will highlight only two classes: positive and negative. The task will be a binary classification.
We use the pre-trained English BERT-base as the basic vectorization model.
Experiment plan:
- Preparing datasets.
- Batch generator implementation.
- Determination of the loss function.
- Building the model.
- Preparation of the validation process.
- Model training.
- Discussion of results and conclusions.
1. Data preparation
First, let's load the datasets necessary for training the basic sentence vectorization model - [ SNLI , MNLI ] and for its validation - [ STS SICK ]. In addition, we need a pre-trained English BERT model. Fortunately, all of this is in the public domain:
Next, let's go to the kaggle platform and download data from there for sentimental analysis - here we need train.csv. For this data, let us single out negative examples in a separate class, and combine the rest into a common group (positive, neutral):
It remains to pick up the data for NER and prepare it in the [text, ner_labels] format:
2. Batch generator
Now let's write a procedure for generating a package of examples for training a neural network. Due to the fact that we now receive not one, but already three
datasets as input, we also need more generators: for an NLI task, using the triplet generator, we will generate triples
[anchor, positive, negative]:
for classification problems NER and Toxic use the same data generator generating pairs [sample, label]. Here we randomly select several examples with their class labels from the provided datasets and form a package:
Finally, let's combine the three generators into a common complex generator that will concatenate all three types of data packet into one to train the model:
3. Loss function
Now, for each task, we define our own error function, and then combine them for the final loss function:
- We will also formulate the problem of "convergence" of paraphrased sentences as a ranking problem and use the slightly modified Softmax Loss as an error function :
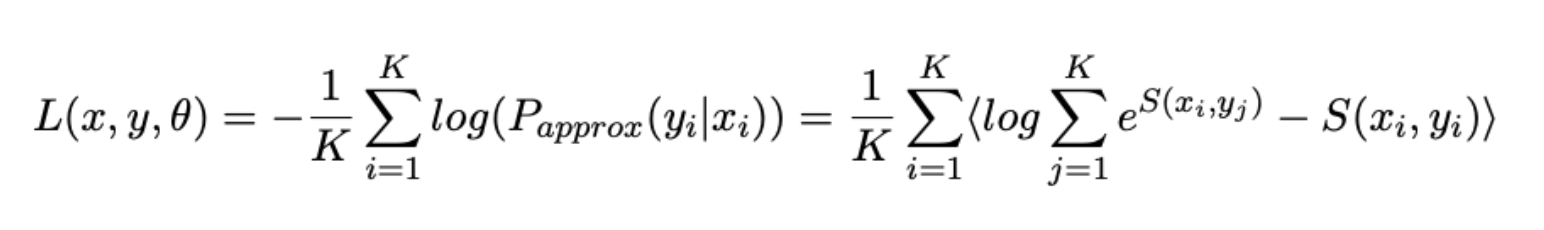
- Binary Cross Entropy Loss:

- NER- -, CrossEnrtopyLoss:

- Joint-loss, :
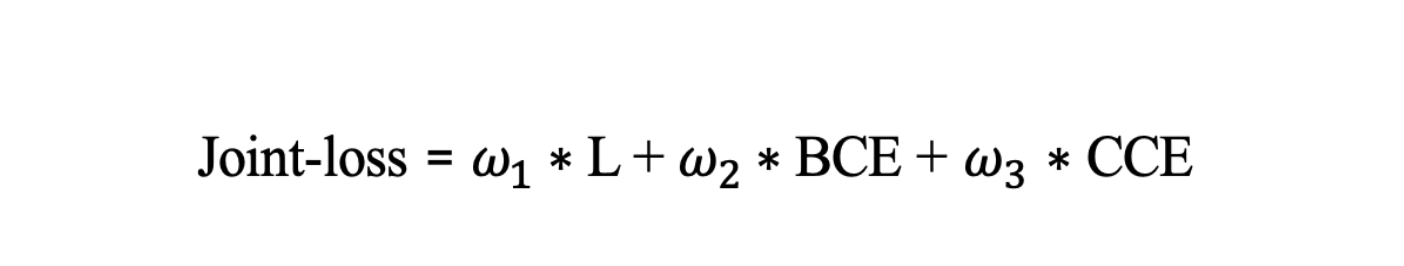
4.
Our model consists of the main NLU-part (here we use the BERT-base) and three "heads" -adapters, specific for each task.
For NLI and Toxic tasks, we will take averaged token embeddings from the last BERT layer (we use masked mean pooling). For the NER task, we will use token embeddings from the output of the 8th encoder layer. When teaching sentence-level representations, embeddings for token-level problems are best taken from the intermediate layers of the model.
It looks something like this:

Multitask-model architecture
Code for assembling the model:
5. Validation of results
To validate the sentence vectorization model, we use the STS 2012–2016 and SICK 2014 datasets .
Like SNLI, this dataset contains pairs of sentences. Let us vectorize them with a model using a model and estimate the similarity between the sentences by calculating the cosine proximity between their vectors. As a metric, we will calculate the rank correlation with labels from the dataset.
Callback code containing this logic:
https://gist.githubusercontent.com/gaphex/f2d2e1a9c849ba9d69a3014da705968f/raw/8ac26c3b236979625a906591dd594b9fd8640483/pearsonr_callback.py .
The task of determining the toxicity of comments will be tested against the AUC metric. Data partitioning is stratified with respect to class distribution.
https://gist.github.com/Ab1992ao/873227b0834ebe43c95b4b5fe029eb95 .
The quality of the NER markup will be assessed by two metrics - accuracy and F1-measure.
https://gist.github.com/Ab1992ao/e3ea080d36d2bf2d0c1ddc17aa4b9e99 .
6. Learning process
We are at the home stretch. Now we have: data, model and validation pipeline. Let's move on to hyperparameters and learning resources.
According to the classics, we have Colab with NVIDIA K80 (12GB) / T80 (16GB) video accelerator at our disposal - depending on your activity in this environment. In order for our entire work of multitask art to fit into memory, it is important to choose the correct maximum length of the processed sequence (seq_len) and, of course, the size of the batch.
In this experiment, we will again limit ourselves to 24 tokens for the sentence task, which will be enough to encode most of the data used in training. For sentiment and ner-task, use the same sequence length.
An increase in the size of the batch has an extremely positive effect on the convergence of the model - we will choose the maximum one that will fit into the memory of our GPU.
As an optimizer, we will use good old Adam with a small learning rate . We will train the model before convergence, 25 epochs should be enough.
Training parameters:
- batch size = 96/72 for BERT-base (16 GB of memory or 12 GB, respectively);
- max_seq_len = 24;
- Optimizer Adam;
- Learning rate ~ 2e-6;
- Metrics - [SpearmanR, F1, AUC];
- Number of eras ~ 25.
Let's compare the metrics of adapters trained on top of the old and new versions of the SBERT model.

As you can see, due to multitasking additional training, we managed to significantly increase the quality of additional tasks NER and TOX. It is important that this did not damage the main functionality of the model - the metrics on the STS and SICK datasets remained the same.
7. Opportunities for further improvement
Augmentation
As part of our work, we use additional manipulations that help to obtain more accurate and stable models.
During batch generation, we apply a number of augmentations, among which the following can be distinguished: at the letter level, at the word level, case change and punctuation removal.
At the level of letters, these are:
1) removal of "prvet";
2) repeat "greetings";
3) swapping of two adjacent symbols "Prievt";
4) replacement for a close key on the keyboard "welcomes";
5) replacement with a phonetically close letter "hello".
At the word level, these are:
1) swapping two or more words;
2) insertion of the words of parasites - "well, this is the same, as it were."
In order to make the model more resistant to case and punctuation changes, punctuation may be removed in some examples. For a random token, the register can be changed.
Augmentations related to changing words and symbols are applied for 3% of the batch, and with punctuation and capitalization - for 30%.
8. Results and conclusions
In this article, we got acquainted with the concept of Multitask Leaning and applied this knowledge to improve vector representations of the language model.
Using these methods, we improved the NLU model for the Russian language SBERT-multitask and published it. We have further trained this version of the model for solving NER problems, sentiment analysis and toxicity analysis.
We measured the metrics for both versions of the SBERT model on the benchmark of Russian language models RussianGLUE . Although RuGLUE tasks did not participate in the multitasking retraining process, the metrics of the second version of the model slightly increased. Teaching the model to one problem broadened its horizons and improved the quality on others as well.

We plan to further develop SBERT natural language models. Among the directions can be distinguished: acceleration and distillation , improvement of the basic architecture and the addition of new tasks. We will talk about them in the following articles. If you are interested in NLP technologies and want to implement them in new products for a wide audience - come to us for an interview .
We wish you the best in your research!
Thank you for your help in preparing the materials for this article. Andriljo and Ibragim_bad...