. We, in RUVDS, lacked an NVMe server in the line to make it faster and more powerful ... Because in the last year the fashion went to deploy on such Bitrix and 1C ... There is a demand for the service, other hosting services also have it and are ordered - in general, everything went to the fact that you just need to choose a configuration and specific hardware options and buy in all 11 locations around the world. And here I must say that we currently support only two configurations: faster and slower. Because spare parts, because support, because software and so on is one of the parts of the policy of adequate prices. That is, a third will be added, and it will be possible to change something there in four years.
We have SSD RAID everywhere (even where HDD is shown at a tariff), but we wanted stronger, higher and faster.
The first thing we learned is that NVMe is not combined into RAID in normal ways, that is, as a result, reliable disks should not be expected. Second, we wanted to push the Hi-CPU into the same server and were surprised to find that the 4.5 GHz frequency is not a server one, but home desktop hardware and server solutions of such frequency simply do not physically exist in nature yet.
Plus, on the way, our admin found a fatal bug in the testing utility. In general, let me tell you with tests what exactly an NVMe solution looks like in VDS hosting.
I must say right away that perhaps we did something wrong, and if someone understands that, I will be very grateful.
▍ Expectations from NVMe
When we switched from HDD to SSD, the difference was like heaven and earth. You run any test and you get a multiple performance boost. This was not the case on NVMe. Moreover, in a head-on collision with our existing NVMe configurations, the drives did not always get around them. They were faster or slower, depending on the conditions of the test.
To get started, we bought a couple of server options. We usually buy a platform, test it, understand what is wrong, test it again, then only roll it out into 11 locations, because so many spare parts at once and new support processes are expensive. Then we bought a platform and immediately stumbled upon an incredibly lame result.
In the same hypervisor on different guest operating systems, it was impossible to distinguish between SSD inside the server or NVMe. Even with the dough.
When using NVMe in RAID, the speed will be slower than SSD. Roughly speaking, when we use RAID, we include it in one PCIe bus and we are limited to this PCI Express, and we can parallelize only a few disks on different buses. We need controllers.
Why so, no one could give a normal answer. They asked an old trusted vendor, new vendors, and generally left-wing vendors. Everyone shrugged their shoulders and said: "Well, you generally suckers, who sticks NVMe in RAID - there will be no performance!". The wording was different from the one given, but the meaning remained unchanged. So we realized that we should probably use NVMe without a raid. There is one company (a friendly competitor) - and so, only they explained that they had the same thing a few years ago. They threw out several platforms, and in the end they decided not to use RAID.
That is, the first problem is that when the disk is released, there will be no autorebuild for a new one, which will be brought by the administrator. Without RAID, clients will lose their virtual machine status and data. Not the same, but we are trying to move on.
Then there is a choice between U2 and M2. We bought expensive U2 rims. They are stuck into the bus through the Okulinka interface. M2 is more often used in desktops, they stick into the motherboard. We also tested it, there is not much difference between them. But if the disk is plugged directly into the board without an intermediate interface, then it is more difficult to maintain, - in case of failure, you will have to remove the server cover and poke around.
▍ Now tests are the reality of NVMe
The result depends on the host OS, the version of the hypervisor, the version of the home OS on the virtual machine, and the choice of testing method.
It depends on the fact that the most recent hypervisors support NVMe with their drivers natively, while others work as an SSD overhead. This is not a very good result either, because we are used to using proven solutions. There is a server Windows 12-16-19. We use the maximum version 16. When the next one comes out, we will use 19. Because the latest versions are always beta. In general, only geeks and suicides use the latest software in server administration. And yes, if your hand is twitching right now, you are a geek. Or a beta tester. Although, you may not know about it yet. The software vendor regularly rolls out a new version, gives rebuts, updates, patches - you need to go through a generation for it to work stably. As always, we are waiting for the second service pack. You can't explain to a client about a new vulnerability or a new pack of updates from MS. More precisely,we can explain, but the client does not always believe. With our fleet of cars on the 19th Windu, it is not very good to run. If all the servers start doing color music with updates and reboots, you don't want to beat your face in the dirt.
The second important point concerns the weirdness on the 45 GB file, you will see now.
Methodology: during testing, we used the diskspd utility . CrystalDiskMark was screwed around it , which we wanted to use first, but we found one very funny bug.
It is important for us that both utilities:
- Allows you to specify several test files at the same time. Moreover, these files can be located on different disks. This can be useful for checking the overall throughput of the controller when reading independently on different disks. Number of threads. How many threads independent from each other will be created that will read and write files.
- In diskspd number of outstanding IO requests per thread - there may be some discrepancies in the translation. Moreover, in CrystalDiskMark this parameter is called Queue, although it can be called a queue with some stretch.
▍ Understanding the number of outstanding IO parameter
To understand how the utility works, we can look into its source code. The following lines are most interesting.
For reading:
if (useCompletionRoutines) { rslt = ReadFileEx(...); } else { rslt = ReadFile(...); }
And similar lines to write:
if (useCompletionRoutines) { rslt = WriteFileEx(...); } else { rslt = WriteFile(...); }
Arguments omitted for clarity. We are more interested in the fact that reading and writing are performed by the standard WinAPI functions:
ReadFile
WriteFile
AND the corresponding asynchronous functions:
ReadFileEx
WriteFileEx
If you take a closer look at the code, you can understand the following:
When setting number of outstanding IO = 1 , synchronous ReadFile and WriteFile options will be used. The pseudocode for the write operation looks like this:
void testThreadFunc() { while (!stopTesting) { WriteFile(...) // } }
If you set the number of outstanding IO> 1 , then the asynchronous ReadFileEx and WriteFileEx options will be used, and the number of outstanding IO sets the depth of such calls for each thread. The pseudocode for a write operation with number of outstanding IO = 3 looks like this:
void callback1() { while (!stopTesting) { WriteFileEx(..., callback1) } } void callback2() { while (!stopTesting) { WriteFileEx(..., callback2) } } void callback3() { while (!stopTesting) { WriteFileEx(..., callback3) } } void testThreadFunc() { WriteFileEx(..., callback1) // WriteFileEx(..., callback2) // WriteFileEx(..., callback3) // // }
Thus, the number of outstanding IO is the number of asynchronous calls in each thread.
▍ Why we didn't use CrystalDiskMark
The CrystalDiskMark utility is just a graphical frontend for diskspd . It's easy to guess about this if you install the utility and go to the CdmResource \ DiskSpd directory.
But there are a number of problems with the implementation of this shell.
First, it modifies the diskspd code in some way . It's easy to understand if you look at the CrystalDiskMark code :
command.Format(L"\"%s\" %s -d%d -A%d -L \"%s\"", ..., GetCurrentProcessId(), ...);
When calling diskspd, it is passed the -A parameter with the Id of the current process. Diskspd does not have such a parameter. The author of CrystalDiskMark decided not to parse the diskspd console output and decided to get the data in a more tricky way. Moreover, the method chosen is not the most successful.
In this function, diskspd is called directly :
int ExecAndWait(TCHAR *pszCmd, BOOL bNoWindow, double *latency) { DWORD Code = 0; … GetExitCodeProcess(pi.hProcess, &Code); *latency = (double)*pMemory * 1000; // milli sec to micro sec return Code; }
In principle, there are no questions about transferring latency through SharedMemory . But if we consider further on the code where the value of the Code variable is used , it becomes clear that this is the measured disk speed. It is a bad idea to return it via the ErrorCode of the process. For example, if the process ends with an error for some other reason, then the error code will simply be displayed as a result of testing.
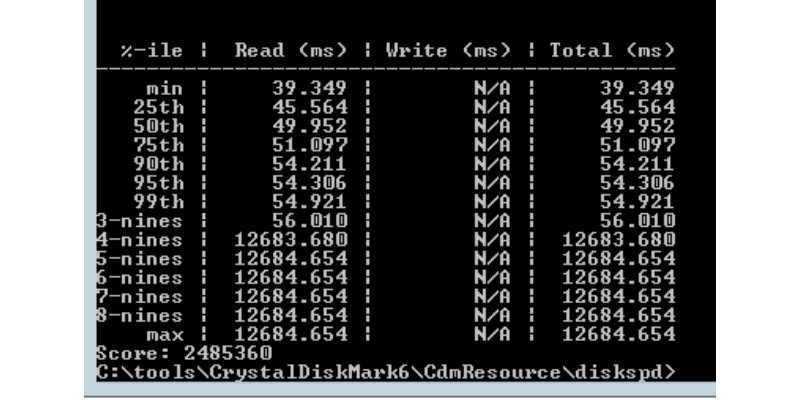
There are also doubts about the correctness of the latency return value . When specifying the -L switch, diskspd returns something like this:
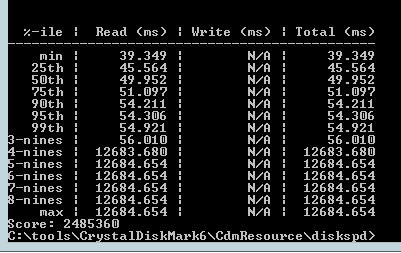
For example, the sixth line means that 95% of the time the latency will be less than 54.306ms . CrystalDiskMark simply returns the average of all values in the table. This can be misleading.
▍ Test parameters
To see the benefits of NVME, you need to set the number of outstanding IO large enough. We chose the number 32.
❒ Platform:
Supermicro SuperServer SYS-6029P-WTRT 2U
❒ Drives:
Intel SSD DC P4610 Series 1.6TB, 2.5in PCIe 3.1 x4, 3D2, TLC
❒ Commands to run diskspd for 10G file:
DiskSpd64.exe -b128K -t32 -o32 -w0 -d10 -si -S -c10G G:/testfile.dat DiskSpd64.exe -b128K -t32 -o32 -w100 -d10 -si -S -c10G G:/testfile.dat DiskSpd64.exe -b4K -t32 -o32 -w30 -d10 -r -S -c10G G:/testfile.dat
❒ Commands to run diskspd for 50G file:
DiskSpd64.exe -b128K -t32 -o32 -w0 -d10 -si -S -c50G G:/testfile.dat DiskSpd64.exe -b128K -t32 -o32 -w100 -d10 -si -S -c50G G:/testfile.dat DiskSpd64.exe -b4K -t32 -o32 -w30 -d10 -r -S -c50G G:/testfile.dat
▍ Results
❒ Table 1 Windows Server 2019 Host OS
|
|
SSD RAID 5 |
NVME U.2 |
|
Windows Server 2016 Virtual Server 10GB File (IOPS - more is better) |
11636 |
246813 |
|
Windows Server 2016 Virtual Server 45GB File (IOPS - more is better) |
9124 |
679 |
|
Debian Virtual Server 10 file 10GB (IOPS - more is better) |
- |
162748 |
|
Debian 10 virtual server file 45GB (IOPS - more is better) |
- |
95330 |
❒ Table 1 Windows Server 2016 Host OS
|
|
SSD RAID 5 |
NVME U.2 |
|
Windows Server 2016 Virtual Server 10GB File (IOPS - more is better) |
11728 |
101350 |
|
Windows Server 2016 Virtual Server 45GB File (IOPS - more is better) |
11200 |
645 |
|
Debian Virtual Server 10 file 10GB (IOPS - more is better) |
10640 |
52145 |
|
Debian 10 virtual server file 45GB (IOPS - more is better) |
9818 |
39821 |
Under Hyper-V and a Windows Server guest, the results are hard to explain. On a small file of about 10G, we get a large increase in IOPS compared to an SSD in a raid. But if we take a 45G file , on the contrary, we get a significant drop in IOPS.
▍ Now on to the Hi-CPU
The second surprise opened on 4.5 GHz processors.
It must be said here that processors in the server lines are also used by the -1 generation from the desktop. Because beta testers are gamers and you can send them software patches. But on the servers, even the same heartblade was not immediately corrected, and not everything. All server solutions are reliable and expensive, but they are always inferior in speed.
We have non-desktop tasks. The machine is divided among many customers. And now we see configurations at 4.5 GHz, which are not in nature.
It turns out that there are two implementations:
- Hi-CPU ( , ). , , . .
- , turbo boost-, . ! - 3,6 4,5 . , -, : . ( ), . .
▍
As a result, we decided to stay at our proven 3.6 GHz (turbo boost 4.4 GHz) and thus close the research with the processor.
With NVMe - having picked up random results from a superstandard utility, as you can see, we changed the tool. Next is the question of the hypervisor and the OS.
Commercially, these discs offer more and more, you have to learn to work. For ourselves, we leave a certain combination of the host version of the hypervisor and we will continue to test, present the disks too. If a hoster writes NVMe, it doesn't mean anything yet. On KVM with certain fresh * nix assemblies and painstaking configuration, you can get excellent gains, but each test should be marked with an asterisk - “in such conditions, if you change a little, and in general everything is not so”. On the 12th Windows or Debian, everything is different.
In general, NVMe is an unconditional standard, but so far this does not mean that it will definitely be faster with it. We are deploying servers with it carefully, but as long as the gain roughly corresponds to the increase in price, no magic.

