In the first part of the article, we implemented a simple (and not very efficient) GUT grid renderer, and promised that we would optimize the renderer so that it could display the billion cells declared in the header.
To do this, we will have to significantly reduce the amount of video memory consumed - in its current form, even on gaming video cards (if they could be bought in our time!), There may not be enough memory, not to mention video cards in office computers.
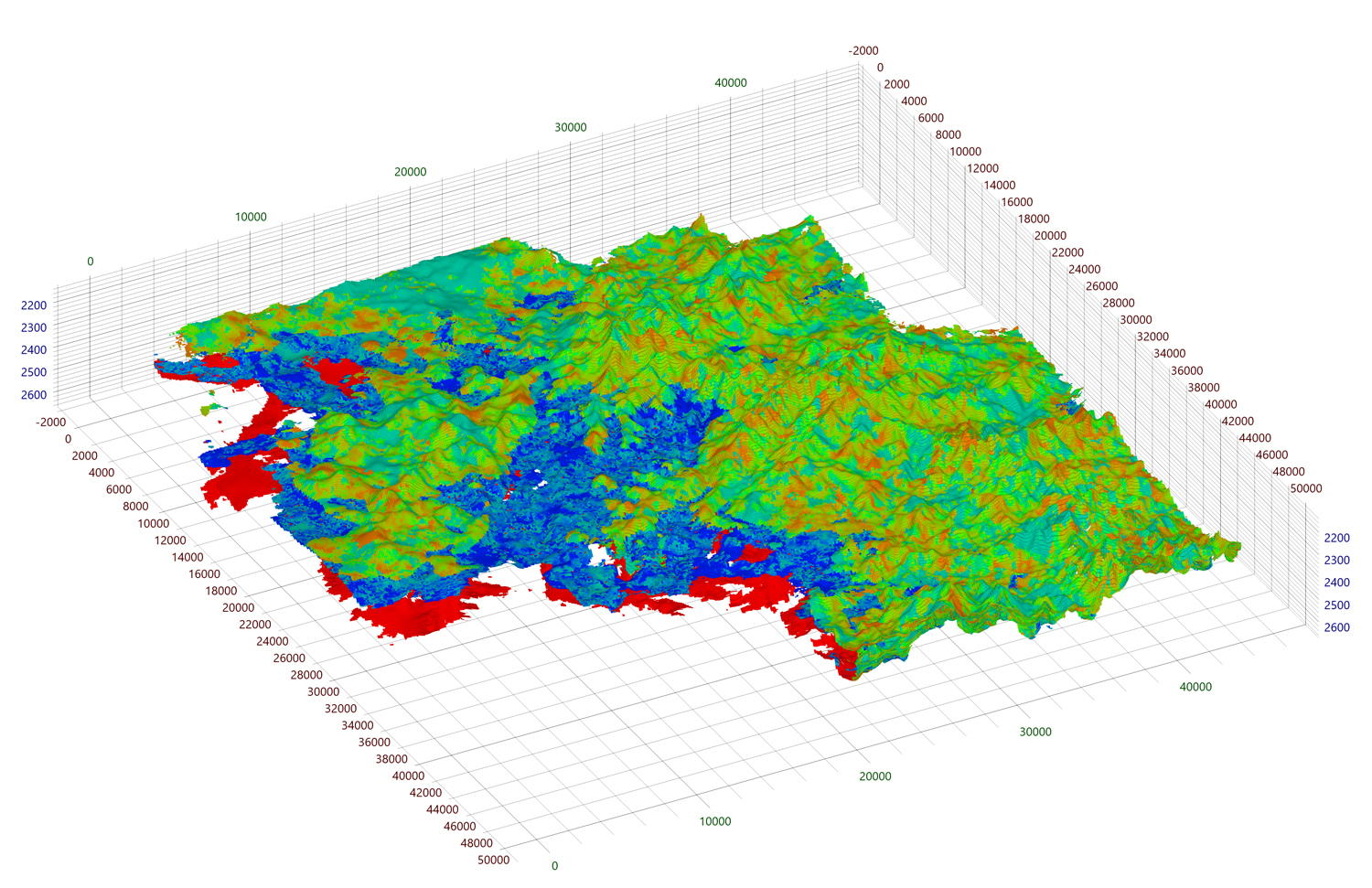
Let's start by analyzing how much memory our renderer currently requires. Each cell face is set at four vertices, each vertex contains five attributes with a total size of 48 bytes. Suppose that a fully docked mesh of size 1000 3 is fed to the input . In this case, 4 * 6 * 1000 2 vertices will be generated for the outer edges of the mesh, with a total volume of 1098.6 MB. Let's not forget about the indices, which will be generated 6 * 6 * 1000 2 pcs. the size of 137.3 MB.
, , - .
, — 2003 . , — .
, , , - - .
2484,3 — , !
:
// corner_point_grid.h
template<typename T>
struct span3d {
T* const data;
const uint32_t ni;
const uint32_t nj;
const uint32_t nk;
span3d(T* _data, uint32_t _ni, uint32_t _nj, uint32_t _nk)
: data(_data), ni(_ni), nj(_nj), nk(_nk) { }
T at(size_t x, size_t y, size_t z) const {
return data[x * nj * nk + y * nk + z];
}
T& at(size_t x, size_t y, size_t z) {
return data[x * nj * nk + y * nk + z];
}
};
struct Palette {
float min_value;
float max_value;
GLuint texture;
};
struct CornerPointGrid
{
CornerPointGrid(uint32_t ni, uint32_t nj, uint32_t nk,
const float* coord, const float *zcorn, const float* property, const uint8_t* mask);
~CornerPointGrid();
void render(GLuint shader,
const Palette& palette,
const mat4& proj, const mat4 & view,
const mat4& model,
vec3 light_direct,
bool primitive_picking);
private:
//
span3d<const float> _coord;
span3d<const float> _zcorn;
span3d<const float> _property;
span3d<const uint8_t> _mask;
//
std::vector<uint8_t> _joined_mask_data;
span3d<uint8_t> _joined_mask; // _joined_mask_data;
// OpenGL
GLuint _position_vbo;
GLuint _normal_vbo;
GLuint _cell_index_vbo;
GLuint _texcoord_vbo;
GLuint _property_vbo;
GLuint _indexbuffer;
GLuint _vao;
//
size_t _triangle_count;
//
void _gen_vertices_and_indices(size_t quad_count);
// OpenGL
void _create_vertex_index_buffers();
// VAO
void _setup_vao();
};
// corner_point_grid.cpp
// .
// 6-------7
// /| / |
// 4------5 | z y
// | 2----|--3 |/
// |/ | / 0-x
// 0------1
// 8-
// x, y, z, .
static const std::array<uint32_t, 8> cell_vertices_offset_x = {
0, 1, 0, 1, 0, 1, 0, 1
};
static const std::array<uint32_t, 8> cell_vertices_offset_y = {
0, 0, 1, 1, 0, 0, 1, 1
};
static const std::array<uint32_t, 8> cell_vertices_offset_z = {
0, 0, 0, 0, 1, 1, 1, 1
};
// , .
// 6-------7
// /| / |
// 4------5 | z y
// | 2----|--3 |/
// |/ | / 0-x
// 0------1
static const std::array<std::array<uint32_t, 4>, 6> cell_quads = {
std::array<uint32_t, 4>{0, 1, 5, 4}, // 1-
std::array<uint32_t, 4>{1, 3, 7, 5}, // 2-
std::array<uint32_t, 4>{3, 2, 6, 7}, // ...
std::array<uint32_t, 4>{2, 0, 4, 6},
std::array<uint32_t, 4>{3, 1, 0, 2},
std::array<uint32_t, 4>{4, 5, 7, 6},
};
//
static const std::array<std::array<int, 3>, 6> cell_quads_neighbors = {
// (i,j,k) -
std::array<int, 3>{ 0, -1, 0},
std::array<int, 3>{ 1, 0, 0},
std::array<int, 3>{ 0, 1, 0},
std::array<int, 3>{-1, 0, 0},
std::array<int, 3>{ 0, 0, -1},
std::array<int, 3>{ 0, 0, 1},
};
// ,
// ( joined_mask)
enum JoinedMaskBits : uint8_t {
I_PREV = 1 << 0, I_NEXT = 1 << 1,
J_PREV = 1 << 2, J_NEXT = 1 << 3,
K_PREV = 1 << 4, K_NEXT = 1 << 5
};
// ,
static const std::array<JoinedMaskBits, 6> cell_quads_joined_mask_bits = {
// x, y z
JoinedMaskBits::J_PREV,
JoinedMaskBits::I_NEXT,
JoinedMaskBits::J_NEXT,
JoinedMaskBits::I_PREV,
JoinedMaskBits::K_PREV,
JoinedMaskBits::K_NEXT,
};
// , ,
// .
// ,
//
// ( , ).
static const std::array<vec2, 4> quad_vertices_texcoords = {
vec2(1, 0),
vec2(0, 0),
vec2(0, 1),
vec2(0, 0),
};
//
static const std::array<uint32_t, 6> quad_to_triangles = {
0, 1, 2, 0, 2, 3
};
static vec3 calc_normal(vec3 v1, vec3 v2){
//
vec3 normal = cross(v1, v2);
//
if (length2(normal) < 1e-8f){
normal = vec3(0, 0, 1);
} else {
normal = normalize(normal);
}
return normal;
}
static void calc_joined_mask(span3d<const float> zcorn, span3d<uint8_t> joined_mask) {
// , ~10 .
const float eps = 0.1f;
//
for(uint32_t i = 0; i < joined_mask.ni; ++i) {
for(uint32_t j = 0; j < joined_mask.nj; ++j) {
for(uint32_t k = 0; k < joined_mask.nk; ++k) {
// zcorn
uint32_t iz = i * 2, jz = j * 2, kz = k * 2;
// , (i,j,k) (i+1,j,k) X
if (i + 1 < joined_mask.ni) {
float d = 0.0f;
d += std::abs(zcorn.at(iz+1, jz, kz ) - zcorn.at(iz+2, jz, kz ));
d += std::abs(zcorn.at(iz+1, jz+1, kz ) - zcorn.at(iz+2, jz+1, kz ));
d += std::abs(zcorn.at(iz+1, jz, kz+1) - zcorn.at(iz+2, jz, kz+1));
d += std::abs(zcorn.at(iz+1, jz+1, kz+1) - zcorn.at(iz+2, jz+1, kz+1));
if (d < eps) {
// - , I_NEXT I_PREV
joined_mask.at(i, j, k) |= I_NEXT;
joined_mask.at(i+1, j, k) |= I_PREV;
}
}
// , (i,j,k) (i,j+1,k) Y
if (j + 1 < joined_mask.nj) {
float d = 0.0f;
d += std::abs(zcorn.at(iz, jz+1, kz ) - zcorn.at(iz, jz+2, kz ));
d += std::abs(zcorn.at(iz+1, jz+1, kz ) - zcorn.at(iz+1, jz+2, kz ));
d += std::abs(zcorn.at(iz, jz+1, kz+1) - zcorn.at(iz, jz+2, kz+1));
d += std::abs(zcorn.at(iz+1, jz+1, kz+1) - zcorn.at(iz+1, jz+2, kz+1));
if (d < eps) {
// - , J_NEXT J_PREV
joined_mask.at(i, j, k) |= J_NEXT;
joined_mask.at(i, j+1, k) |= J_PREV;
}
}
// , (i,j,k) (i,j,k+1) Z
if (k + 1 < joined_mask.nk) {
float d = 0.0f;
d += std::abs(zcorn.at(iz, jz, kz+1) - zcorn.at(iz, jz, kz+2));
d += std::abs(zcorn.at(iz+1, jz, kz+1) - zcorn.at(iz+1, jz, kz+2));
d += std::abs(zcorn.at(iz, jz+1, kz+1) - zcorn.at(iz, jz+1, kz+2));
d += std::abs(zcorn.at(iz+1, jz+1, kz+1) - zcorn.at(iz+1, jz+1, kz+2));
if (d < eps) {
// - , K_NEXT K_PREV
joined_mask.at(i, j, k) |= K_NEXT;
joined_mask.at(i, j, k+1) |= K_PREV;
}
}
} // for k
} // for j
} // for i
}
static bool check_if_quad_culled(const span3d<const uint8_t>& mask,
const span3d<uint8_t>& joined_mask,
uint32_t i, uint32_t j, uint32_t k, uint32_t qi) {
// ,
if (!(joined_mask.at(i, j, k) & cell_quads_joined_mask_bits[qi]))
return false;
//
// ( , .. _joined_mask == 0)
if (!mask.at(i + cell_quads_neighbors[qi][0],
j + cell_quads_neighbors[qi][1],
k + cell_quads_neighbors[qi][2]))
return false;
// ,
return true;
}
static size_t calc_number_of_quads(const span3d<const uint8_t>& mask,
const span3d<uint8_t> joined_mask) {
size_t num_of_quads = 0;
for (uint32_t i = 0; i < mask.ni; ++i)
for (uint32_t j = 0; j < mask.nj; ++j)
for (uint32_t k = 0; k < mask.nk; ++k)
//
if (mask.at(i, j, k)){
//
for (uint32_t qi = 0; qi < 6; ++qi){
// ,
if (!check_if_quad_culled(mask, joined_mask, i, j, k, qi))
// ,
num_of_quads++;
}
}
return num_of_quads;
}
// 8 , (i, j, k).
// 6-------7
// /| / |
// 4------5 |
// | 2----|--3
// |/ | /
// 0------1
static void get_cell_vertices(const span3d<const float>& coord,
const span3d<const float>& zcorn,
uint32_t i, uint32_t j, uint32_t k,
std::array<vec3, 8>& vertices)
{
//
for (int vi = 0; vi < 8; ++vi) {
//
uint32_t pillar_index_i = i + cell_vertices_offset_x[vi];
uint32_t pillar_index_j = j + cell_vertices_offset_y[vi];
// p1 -
float p1_x = coord.at(pillar_index_i, pillar_index_j, 0);
float p1_y = coord.at(pillar_index_i, pillar_index_j, 1);
float p1_z = coord.at(pillar_index_i, pillar_index_j, 2);
// p2 -
float p2_x = coord.at(pillar_index_i, pillar_index_j, 3);
float p2_y = coord.at(pillar_index_i, pillar_index_j, 4);
float p2_z = coord.at(pillar_index_i, pillar_index_j, 5);
// Z , X Y ,
// , (x,y,z) p1-p2
float z = zcorn.at(2 * i + cell_vertices_offset_x[vi],
2 * j + cell_vertices_offset_y[vi],
2 * k + cell_vertices_offset_z[vi]);
float t = (z - p1_z) / (p2_z - p1_z);
float x = p1_x + (p2_x - p1_x) * t;
float y = p1_y + (p2_y - p1_y) * t;
vertices[vi].x = x;
vertices[vi].y = y;
vertices[vi].z = z;
}
}
void CornerPointGrid::_gen_vertices_and_indices(size_t quad_count) {
const size_t vertex_count = quad_count * 4;
std::vector<float> a_position, a_index, a_property, a_normal, a_texcoord;
// 3 (x, y z)
a_position.reserve(3 * vertex_count);
// +
a_index.reserve(3 * vertex_count);
// +
a_property.reserve(vertex_count);
// +
a_normal.reserve(3 * vertex_count);
// + ( )
a_texcoord.reserve(2 * vertex_count);
// ,
std::array<vec3, 8> cell_vertices;
//
for (uint32_t i = 0; i < _property.ni; ++i) {
for (uint32_t j = 0; j < _property.nj; ++j) {
for (uint32_t k = 0; k < _property.nk; ++k) {
// ( )
if (_mask.at(i, j, k)){
// 8 ,
get_cell_vertices(_coord, _zcorn, i, j, k, cell_vertices);
//
for (int qi = 0; qi < 6; ++qi) {
// ,
if (!check_if_quad_culled(_mask, _joined_mask, i, j, k, qi)){
// 4
const std::array<uint32_t, 4>& quad = cell_quads[qi];
//
vec3 normal = calc_normal(
cell_vertices[quad[0]] - cell_vertices[quad[1]],
cell_vertices[quad[2]] - cell_vertices[quad[1]]);
//
for (int vii = 0; vii < 4; ++vii){
//
const vec3& v = cell_vertices[quad[vii]];
//
a_position.insert(a_position.end(), {v.x, v.y, v.z});
a_index.insert(a_index.end(), {(float)i, (float)j, (float)k});
a_property.push_back(_property.at(i, j, k));
a_normal.insert(a_normal.end(), {normal.x, normal.y, normal.z});
vec2 texcoords = quad_vertices_texcoords[vii];
a_texcoord.insert(a_texcoord.end(), {texcoords.x, texcoords.y});
}
}
}
}
}
}
}
assert(a_position.size() == vertex_count * 3);
// VBO
glNamedBufferStorage(_position_vbo, a_position.size() * sizeof (float), a_position.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_normal_vbo, a_normal.size() * sizeof (float), a_normal.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_cell_index_vbo, a_index.size() * sizeof (float), a_index.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_texcoord_vbo, a_texcoord.size() * sizeof (float), a_texcoord.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_property_vbo, a_property.size() * sizeof (float), a_property.data(), gl::GL_NONE_BIT);
// -
size_t indices_count = quad_count * 6;
std::vector<uint32_t> indices;
indices.reserve(indices_count);
for (size_t i = 0; i < quad_count; ++i)
for (uint32_t j = 0; j < 6; ++j)
//
indices.push_back(static_cast<uint32_t>(i * 4 + quad_to_triangles[j]));
glNamedBufferStorage(_indexbuffer, indices.size() * sizeof (uint32_t), indices.data(), gl::GL_NONE_BIT);
// , glDrawElements
_triangle_count = indices.size();
}
void CornerPointGrid::_create_vertex_index_buffers() {
//
glCreateBuffers(1, &_position_vbo);
glCreateBuffers(1, &_normal_vbo);
glCreateBuffers(1, &_cell_index_vbo);
glCreateBuffers(1, &_texcoord_vbo);
glCreateBuffers(1, &_property_vbo);
//
glCreateBuffers(1, &_indexbuffer);
}
void CornerPointGrid::_setup_vao() {
// VAO
glCreateVertexArrays(1, &_vao);
// VAO
glVertexArrayElementBuffer(_vao, _indexbuffer);
// VAO
// position
glVertexArrayVertexBuffer(_vao, 0, _position_vbo, 0, sizeof (float) * 3);
glVertexArrayAttribBinding(_vao, 0, 0);
glVertexArrayAttribFormat(_vao, 0, 3, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 0);
// normal
glVertexArrayVertexBuffer(_vao, 1, _normal_vbo, 0, sizeof (float) * 3);
glVertexArrayAttribBinding(_vao, 1, 1);
glVertexArrayAttribFormat(_vao, 1, 3, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 1);
// cell index
glVertexArrayVertexBuffer(_vao, 2, _cell_index_vbo, 0, sizeof (float) * 3);
glVertexArrayAttribBinding(_vao, 2, 2);
glVertexArrayAttribFormat(_vao, 2, 3, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 2);
// texcoord
glVertexArrayVertexBuffer(_vao, 3, _texcoord_vbo, 0, sizeof (float) * 2);
glVertexArrayAttribBinding(_vao, 3, 3);
glVertexArrayAttribFormat(_vao, 3, 2, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 3);
// property
glVertexArrayVertexBuffer(_vao, 4, _property_vbo, 0, sizeof (float));
glVertexArrayAttribBinding(_vao, 4, 4);
glVertexArrayAttribFormat(_vao, 4, 1, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 4);
}
CornerPointGrid::CornerPointGrid(uint32_t ni, uint32_t nj, uint32_t nk,
const float* coord, const float* zcorn, const float* property, const uint8_t* mask) :
_coord(coord, ni+1, nj+1, 6),
_zcorn(zcorn, ni*2, nj*2, nk*2),
_property(property, ni, nj, nk),
_mask(mask, ni, nj, nk),
_joined_mask_data(ni*nj*nk, 0),
_joined_mask(_joined_mask_data.data(), ni, nj, nk) {
//
calc_joined_mask(_zcorn, _joined_mask);
//
size_t quad_count = calc_number_of_quads(_mask, _joined_mask);
//
_create_vertex_index_buffers();
// /
_gen_vertices_and_indices(quad_count);
// VAO
_setup_vao();
}
CornerPointGrid::~CornerPointGrid()
{
glDeleteVertexArrays(1, &_vao);
glDeleteBuffers(1, &_position_vbo);
glDeleteBuffers(1, &_normal_vbo);
glDeleteBuffers(1, &_cell_index_vbo);
glDeleteBuffers(1, &_texcoord_vbo);
glDeleteBuffers(1, &_property_vbo);
glDeleteBuffers(1, &_indexbuffer);
}
void CornerPointGrid::render(GLuint shader,
const Palette& palette,
const mat4& proj,
const mat4& view,
const mat4& model,
vec3 light_direct,
bool primitive_picking)
{
// , ,
// , backface culling
glUseProgram(shader);
// MVP
mat4 mvp = proj * view * model;
glProgramUniformMatrix4fv(shader, glGetUniformLocation(shader, "u_mvp"), 1, GL_FALSE, &mvp[0][0]);
//
mat3 normal_mat = transpose(inverse(mat3{model}));
glProgramUniformMatrix3fv(shader, glGetUniformLocation(shader, "u_normal_mat"), 1, GL_FALSE, &normal_mat[0][0]);
//
glProgramUniform3fv(shader, glGetUniformLocation(shader, "u_light_direct"), 1, &light_direct[0]);
glProgramUniform1i(shader, glGetUniformLocation(shader, "u_primitive_picking"), primitive_picking);
//
glBindTextureUnit(0, palette.texture);
glProgramUniform2f(shader, glGetUniformLocation(shader, "u_value_range"), palette.min_value, palette.max_value);
//
glBindVertexArray(_vao);
glDrawElements(GL_TRIANGLES, _triangle_count, GL_UNSIGNED_INT, nullptr);
//
glBindVertexArray(0);
glBindTextureUnit(0, 0);
glUseProgram(0);
}
// corner_point_grid.vert
#version 440
//
layout(location=0) in vec3 a_pos;
//
layout(location=1) in vec3 a_normal;
//
layout(location=2) in vec3 a_ind;
//
layout(location=3) in vec2 a_texcoord;
// ,
layout(location=4) in float a_property;
//
layout(binding=0) uniform sampler1D u_palette_tex;
// MVP-
layout(location=0) uniform mat4 u_mvp;
//
layout(location=1) uniform mat3 u_normal_mat;
//
layout(location=2) uniform vec2 u_value_range;
//
layout(location=3) uniform bool u_primitive_picking;
//
layout(location=4) uniform vec3 u_light_direct;
layout(location=0) out INTERFACE {
//
vec4 color;
//
vec2 texcoord;
} vs_out;
void main() {
// mvp-
gl_Position = u_mvp * vec4(a_pos, 1);
//
vs_out.texcoord = a_texcoord;
// ,
if (u_primitive_picking) {
vs_out.color = vec4(a_ind.x, a_ind.y, a_ind.z, 1);
return;
}
//
float normalized_value = (a_property - u_value_range.x) / (u_value_range.y - u_value_range.x);
//
vec4 cell_color = texture(u_palette_tex, normalized_value);
//
vec3 normal = normalize(u_normal_mat * a_normal);
//
float NdotL = max(0, dot(normal, u_light_direct));
//
const float ka = 0.1, kd = 0.7;
vs_out.color = vec4((ka + NdotL * kd) * cell_color.rgb, cell_color.a);
}
// corner_point_grid.frag
#version 440
//
layout(location=3) uniform bool u_primitive_picking;
layout(location = 0) in INTERFACE {
vec4 color;
vec2 texcoord;
} fs_in;
layout(location=0) out vec4 FragColor;
//
vec3 border_color(vec2 dist, vec3 color)
{
// dist (1 - , 0 - )
// c
vec2 delta = fwidth(dist);
// ,
vec2 len = 1.0 / delta;
// - ,
vec2 edge_factor = smoothstep(0.2, 0.8, len * dist);
//
return mix(color * 0.25, color, min(edge_factor.x, edge_factor.y));
}
void main()
{
if (u_primitive_picking) {
FragColor = fs_in.color;
return;
}
//
vec3 res_color = border_color(fs_in.texcoord, fs_in.color.rgb);
FragColor = vec4(res_color, fs_in.color.a);
}
:
1. (3*4 );
2. (3*4 );
3. (3*4 );
4. (2*4 );
5. (4 ).
, «» . . , — «» , , 12 .
:
void CornerPointGrid::_gen_vertices_and_indices(size_t quad_count) {
const size_t vertex_count = quad_count * 4;
// // std::vector<float> a_position, a_index, a_property, a_normal, a_texcoord;
std::vector<float> a_position, a_index, a_property, a_texcoord;
// 3 (x, y z)
a_position.reserve(3 * vertex_count);
// +
a_index.reserve(3 * vertex_count);
// +
a_property.reserve(vertex_count);
// // +
// // a_normal.reserve(3 * vertex_count);
// + ( )
a_texcoord.reserve(2 * vertex_count);
// …
// ,
if (!check_if_quad_culled(_mask, _joined_mask, i, j, k, qi)){
// 4
const std::array<uint32_t, 4>& quad = cell_quads[qi];
//
// // vec3 normal = calc_normal(
// // cell_vertices[quad[0]] - cell_vertices[quad[1]],
// // cell_vertices[quad[2]] - cell_vertices[quad[1]]);
//
for (int vii = 0; vii < 4; ++vii){
//
const vec3& v = cell_vertices[quad[vii]];
//
a_position.insert(a_position.end(), {v.x, v.y, v.z});
a_index.insert(a_index.end(), {(float)i, (float)j, (float)k});
a_property.push_back(_property.at(i, j, k));
// // a_normal.insert(a_normal.end(), {normal.x, normal.y, normal.z});
vec2 texcoords = quad_vertices_texcoords[vii];
a_texcoord.insert(a_texcoord.end(), {texcoords.x, texcoords.y});
}
// …
// VBO
glNamedBufferStorage(_position_vbo, a_position.size() * sizeof (float), a_position.data(), gl::GL_NONE_BIT);
// // glNamedBufferStorage(_normal_vbo, a_normal.size() * sizeof (float), a_normal.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_cell_index_vbo, a_index.size() * sizeof (float), a_index.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_texcoord_vbo, a_texcoord.size() * sizeof (float), a_texcoord.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_property_vbo, a_property.size() * sizeof (float), a_property.data(), gl::GL_NONE_BIT);
( ):
void CornerPointGrid::_setup_vao() {
// VAO
glCreateVertexArrays(1, &_vao);
// VAO
glVertexArrayElementBuffer(_vao, _indexbuffer);
// VAO
// position
glVertexArrayVertexBuffer(_vao, 0, _position_vbo, 0, sizeof (float) * 3);
glVertexArrayAttribBinding(_vao, 0, 0);
glVertexArrayAttribFormat(_vao, 0, 3, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 0);
// normal
// // glVertexArrayVertexBuffer(_vao, 1, _normal_vbo, 0, sizeof (float) * 3);
// // glVertexArrayAttribBinding(_vao, 1, 1);
// // glVertexArrayAttribFormat(_vao, 1, 3, GL_FLOAT, GL_FALSE, 0);
// // glEnableVertexArrayAttrib(_vao, 1);
// cell index
glVertexArrayVertexBuffer(_vao, 1, _cell_index_vbo, 0, sizeof (float) * 3);
glVertexArrayAttribBinding(_vao, 1, 1);
glVertexArrayAttribFormat(_vao, 1, 3, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 1);
// texcoord
glVertexArrayVertexBuffer(_vao, 2, _texcoord_vbo, 0, sizeof (float) * 2);
glVertexArrayAttribBinding(_vao, 2, 2);
glVertexArrayAttribFormat(_vao, 2, 2, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 2);
// property
glVertexArrayVertexBuffer(_vao, 3, _property_vbo, 0, sizeof (float));
glVertexArrayAttribBinding(_vao, 3, 3);
glVertexArrayAttribFormat(_vao, 3, 1, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 3);
//...
, , . :
// …
// MVP-
layout(location=0) uniform mat4 u_mvp;
// ( )
layout(location=1) uniform mat4 u_model;
// …
layout(location=0) out INTERFACE {
//
vec4 color;
// ( )
vec3 model_pos;
//
vec2 texcoord;
} vs_out;
void main() {
// mvp-
vec4 pos = vec4(a_pos, 1);
gl_Position = u_mvp * pos;
// ,
if (u_primitive_picking) {
vs_out.color = vec4(a_ind.x, a_ind.y, a_ind.z, 1);
return;
}
// ( )
vs_out.model_pos = vec3(u_model * pos);
// …
}
, :
// …
layout(location = 0) in INTERFACE {
vec4 cell_color;
vec3 model_pos;
vec2 texcoord;
} fs_in;
// …
void main()
{
if (u_primitive_picking) {
FragColor = fs_in.cell_color;
return;
}
vec3 normal = normalize(cross(dFdy(fs_in.model_pos), dFdx(fs_in.model_pos)));
// …
}
, . :

, - .
?
|
|
|
FPS |
FPS |
|
2 484,29 |
54,3 |
17,7 |
|
1 932,23 |
60,8 |
18,4 |
1 2003 c 50% AMD RX580 8GB
, , , .
:
(3*4 );
(3*4 );
(2*4 );
(4 ).
. : 0 1. — , .
? : — .
, :
// …
// // std::vector<float> a_position, a_index, a_property, a_texcoord;
std::vector<float> a_position, a_index, a_property;
// 3 (x, y z)
a_position.reserve(3 * vertex_count);
// +
a_index.reserve(3 * vertex_count);
// +
a_property.reserve(vertex_count);
// // + ( )
// // a_texcoord.reserve(2 * vertex_count);
// …
// VBO
glNamedBufferStorage(_position_vbo, a_position.size() * sizeof (float), a_position.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_cell_index_vbo, a_index.size() * sizeof (float), a_index.data(), gl::GL_NONE_BIT);
// //glNamedBufferStorage(_texcoord_vbo, a_texcoord.size() * sizeof (float), a_texcoord.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_property_vbo, a_property.size() * sizeof (float), a_property.data(), gl::GL_NONE_BIT);
// …
// cell index
glVertexArrayVertexBuffer(_vao, 1, _cell_index_vbo, 0, sizeof (float) * 3);
glVertexArrayAttribBinding(_vao, 1, 1);
glVertexArrayAttribFormat(_vao, 1, 3, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 1);
// texcoord
// //glVertexArrayVertexBuffer(_vao, 2, _texcoord_vbo, 0, sizeof (float) * 2);
// //glVertexArrayAttribBinding(_vao, 2, 2);
// //glVertexArrayAttribFormat(_vao, 2, 2, GL_FLOAT, GL_FALSE, 0);
// //glEnableVertexArrayAttrib(_vao, 2);
// property
glVertexArrayVertexBuffer(_vao, 2, _property_vbo, 0, sizeof (float));
glVertexArrayAttribBinding(_vao, 2, 2);
glVertexArrayAttribFormat(_vao, 2, 1, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 2);
— , 0, -1:
// , ,
// .
// ,
//
// ( , ).
static const std::array<vec2, 4> quad_vertices_texcoords = {
vec2( 1, -1),
vec2(-1, -1),
vec2(-1, 1),
vec2(-1, -1),
};
— :
// …
//
a_position.insert(a_position.end(), {v.x, v.y, v.z});
// .
a_index.insert(a_index.end(), { i * texcoords[0],
j * texcoords[1],
k });
// …
, , sign():
// …
// ,
if (u_primitive_picking) {
vs_out.color = vec4(abs(a_ind.x), abs(a_ind.y), a_ind.z, 1);
return;
}
// ( )
vs_out.model_pos = vec3(u_model * pos);
//
vs_out.texcoord = vec2(max(vec2(0), sign(a_ind.xy)));
:
|
|
|
FPS |
FPS |
|
2 484,29 |
54,3 |
17,7 |
|
1 932,23 |
60,8 |
18,4 |
|
1 564,18 |
65,8 |
19,0 |
2 AMD RX580 8GB
, , .
, float, int16 – 32767 , , .
int16 ( 1, ):
// …
// // std::vector<float> a_position, a_index, a_property;
std::vector<float> a_position, a_property;
std::vector<int16_t> a_index;
// …
//
a_position.insert(a_position.end(), {v.x, v.y, v.z});
// .
// 1 ,
a_index.insert(a_index.end(), {static_cast<int16_t>((i+1) * texcoords[0]),
static_cast<int16_t>((j+1) * texcoords[1]),
static_cast<int16_t>(k) });
// …
// VBO
glNamedBufferStorage(_position_vbo, a_position.size() * sizeof (float), a_position.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_cell_index_vbo, a_index.size() * sizeof (int16_t), a_index.data(), gl::GL_NONE_BIT);
glNamedBufferStorage(_property_vbo, a_property.size() * sizeof (float), a_property.data(), gl::GL_NONE_BIT);
// …
// VAO
// position
glVertexArrayVertexBuffer(_vao, 0, _position_vbo, 0, sizeof (float) * 3);
glVertexArrayAttribBinding(_vao, 0, 0);
glVertexArrayAttribFormat(_vao, 0, 3, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 0);
// cell index
glVertexArrayVertexBuffer(_vao, 1, _cell_index_vbo, 0, sizeof (int16_t) * 3);
glVertexArrayAttribBinding(_vao, 1, 1);
glVertexArrayAttribFormat(_vao, 1, 3, GL_SHORT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 1);
, …
, — 200 . ?
. , 32 . , int16 16 , . — :
// …
std::vector<float> a_position, a_property;
std::vector<int16_t> a_index;
// 3 (x, y z)
a_position.reserve(3 * vertex_count);
// + ( )
a_index.reserve(4 * vertex_count);
// …
//
a_position.insert(a_position.end(), {v.x, v.y, v.z});
// .
// 1 ,
a_index.insert(a_index.end(), {static_cast<int16_t>((i+1) * texcoords[0]),
static_cast<int16_t>((j+1) * texcoords[1]),
static_cast<int16_t>(k),
0});
// …
// VAO
// position
glVertexArrayVertexBuffer(_vao, 0, _position_vbo, 0, sizeof (float) * 3);
glVertexArrayAttribBinding(_vao, 0, 0);
glVertexArrayAttribFormat(_vao, 0, 3, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 0);
// cell index
glVertexArrayVertexBuffer(_vao, 1, _cell_index_vbo, 0, sizeof (int16_t) * 4);
glVertexArrayAttribBinding(_vao, 1, 1);
glVertexArrayAttribFormat(_vao, 1, 4, GL_SHORT, GL_FALSE, 0);
glEnableVertexArrayAttrib(_vao, 1);
//…
// :
#version 440
//
layout(location=0) in vec3 a_pos;
//
layout(location=1) in ivec4 a_ind;
//…
:
|
|
|
FPS |
FPS |
|
2 484,29 |
54,3 |
17,7 |
|
1 932,23 |
60,8 |
18,4 |
|
1 564,18 |
65,8 |
19,0 |
16- |
1 380,16 |
70,4 |
19,3 |
3 AMD RX580 8GB
, .
, :
(3*4 );
* (4*2 );
(4 ).
48 , 24 – ! 1,8 .
«FPS ». , ?
, « », . 3 , .
. ( , ) — . , , .
, . :

, .
, , . — , , . , Early Z Rejection, , .
, :
// …
//
for (uint32_t i = 0; i < _property.ni; ++i) {
for (uint32_t j = 0; j < _property.nj; ++j) {
for (uint32_t k = 0; k < _property.nk; ++k) {
// ( )
if (_mask.at(i, j, k)){
// …
, .
, , — . , — - , , .
— , . — , , .
, , , :
// …
// +
a_property.reserve(vertex_count);
auto calc_cell = [this, &a_position, &a_index, &a_property](size_t i, size_t j, size_t k)
{
// ,
std::array<vec3, 8> cell_vertices;
// ( )
if (_mask.at(i, j, k)){
// 8 ,
get_cell_vertices(_coord, _zcorn, i, j, k, cell_vertices);
// …
};
, , :
size_t min_dim = std::min({_property.ni, _property.nj, _property.nk});
size_t max_layers = min_dim / 2 + 1;
size_t oi = 0, oj = 0, ok = 0;
size_t ni = _property.ni, nj = _property.nj, nk = _property.nk;
for (size_t layer = 0; layer < max_layers; ++layer) {
for (size_t k : {ok, nk-1}) {
for (size_t i = oi; i < ni; ++i) {
for (size_t j = oj; j < nj; ++j) {
calc_cell(i, j, k);
}
}
if (ok >= nk-1) break;
}
for (size_t j : {oj, nj-1}) {
for (size_t i = oi; i < ni; ++i) {
for (size_t k = ok+1; k < nk - 1; ++k) {
calc_cell(i,j,k);
}
}
if (oj >= nj - 1) break;
}
for (size_t i : {oi, ni-1}) {
for (size_t j = oj+1; j < nj-1; ++j) {
for (size_t k = ok+1; k < nk-1; ++k) {
calc_cell(i, j ,k);
}
}
if (oi >= ni - 1) break;
}
++oi; ++oj; ++ok;
--ni; --nj; --nk;
}
, — , 5 . , . . ( ) , .
, , , . , !
|
|
|
FPS |
FPS |
|
2 484,29 |
54,3 |
17,7 |
|
1 932,23 |
60,8 |
18,4 |
|
1 564,18 |
65,8 |
19,0 |
16- |
1 380,16 |
70,4 |
19,3 |
|
1 380,16 |
67,4 |
64,9 |
4. AMD RX580 8GB
, OpenGL. , — , .
OpenGL 1.5 glMapBuffer(). , «». , (, ). .
, glMapBuffer():
void CornerPointGrid::_gen_vertices_and_indices(size_t quad_count) {
const size_t vertex_count = quad_count * 4;
// VBO
glNamedBufferStorage(_position_vbo, 3 * vertex_count * sizeof (float), nullptr, gl::GL_MAP_WRITE_BIT);
glNamedBufferStorage(_cell_index_vbo, 4 * vertex_count * sizeof (int16_t), nullptr, gl::GL_MAP_WRITE_BIT);
glNamedBufferStorage(_property_vbo, vertex_count * sizeof (float), nullptr, gl::GL_MAP_WRITE_BIT);
auto a_position = reinterpret_cast<float*>(glMapNamedBuffer(_position_vbo, gl::GL_WRITE_ONLY));
auto a_index = reinterpret_cast<int16_t*>(glMapNamedBuffer(_cell_index_vbo, gl::GL_WRITE_ONLY));
auto a_property = reinterpret_cast<float*>(glMapNamedBuffer(_property_vbo, gl::GL_WRITE_ONLY));
// …
//
for (int vii = 0; vii < 4; ++vii){
//
const vec3& v = cell_vertices[quad[vii]];
ivec2 texcoords = quad_vertices_texcoords[vii];
//
a_position[0] = v.x;
a_position[1] = v.y;
a_position[2] = v.z;
a_position += 3;
// .
// 1 ,
a_index[0] = static_cast<int16_t>((i+1) * texcoords[0]);
a_index[1] = static_cast<int16_t>((j+1) * texcoords[1]);
a_index[2] = static_cast<int16_t>(k);
a_index[3] = 0;
a_index += 4;
a_property[0] = _property.at(i, j, k);
a_property += 1;
}
:
// …
// -
size_t indices_count = quad_count * 6;
glNamedBufferStorage(_indexbuffer, indices_count * sizeof (uint32_t), nullptr, gl::GL_MAP_WRITE_BIT);
auto indices = reinterpret_cast<uint32_t*>(glMapNamedBuffer(_indexbuffer, gl::GL_WRITE_ONLY));
for (size_t i = 0; i < quad_count; ++i)
for (uint32_t j = 0; j < 6; ++j)
//
*indices++ = static_cast<uint32_t>(i * 4 + quad_to_triangles[j]);
glUnmapNamedBuffer(_indexbuffer);
glUnmapNamedBuffer(_position_vbo);
glUnmapNamedBuffer(_cell_index_vbo);
glUnmapNamedBuffer(_property_vbo);
// …
, , :
|
|
|
|
() |
|
2 484,29 |
3 258,55 |
5 844,64 |
|
1 932,23 |
2 704,95 |
4 738,06 |
|
1 564,18 |
2 336,84 |
4 000,90 |
16- |
1 380,16 |
2 151,87 |
3 631,87 |
glMapBuffer |
1 380,16 |
2 152,14 |
2 618,31 |
5. AMD RX580 8GB
, , .
, Nvidia (GTX 1050Ti, RTX 2070) — 400+ . git bisect , glMapBuffer(). , - , AMD Intel.
(GL_KHR_debug) :
Buffer detailed info: Buffer object 1 (bound to NONE, usage hint is GL_DYNAMIC_DRAW) will use SYSTEM HEAP memory as the source for buffer object operations.
Buffer detailed info: Buffer object 1 (bound to NONE, usage hint is GL_DYNAMIC_DRAW) has been mapped WRITE_ONLY in SYSTEM HEAP memory (fast).
…
, , GL_DYNAMIC_DRAW, , . , .
, GL_DYNAMIC_DRAW – , glBufferStorage(), .
glBufferData(…, GL_STATIC_DRAW), , :
Buffer detailed info: Buffer object 1 (bound to NONE, usage hint is GL_STATIC_DRAW) will use VIDEO memory as the source for buffer object operations.
Buffer detailed info: Buffer object 1 (bound to NONE, usage hint is GL_STATIC_DRAW) has been mapped in HOST memory
…
, Nvidia – GL_DYNAMIC_DRAW . , GL_ARB_buffer_storage, - .
:
|
|
FPS
|
FPS
|
AMD RX580 |
54,3 – 67,4 (+24%) |
17,7 – 64,9 (+366%) |
Nvidia GTX 1050Ti |
29.9 – 40,2 (+34%) |
20.9 – 39,5 (+88%) |
Nvidia RTX 2070 |
116 – 150 (+29%) |
36,3 – 149 (+410%) |
Intel UHD 630 |
6 – 12 (+100%) |
5 – 12 (+140%) |
6.
30% , – 80% 410%! , . , , . !
, . .
, — , , . , ; ; , ... , - , , , — !
. , . ; !