
My name is Sasha, at SberDevices I work on speech recognition and how data can make it better. In this article, I will talk about the new Golos speech dataset, which consists of audio files and corresponding transcriptions. The total duration of the recordings is approximately 1240 hours, the sampling rate is 16 kHz. At the moment, this is the largest corpus of audio recordings in Russian, marked by hand. We released the corpus under a license close to CC Attribution ShareAlike , which allows it to be used for both scientific research and commercial purposes. I will talk about what the dataset consists of, how it was assembled and what results it can achieve.
Golos dataset structure
When creating the dataset, we were guided by the desire to solve the cold start problem, when data from real users was not yet available. This is what ultimately made it possible to make it publicly available, since the speech of real users is not there.
The audio recordings in the dataset are collected from two sources. The first source is a crowdsourcing platform, which is why we call it Crowd Domain. The second source is recordings created in the studio using the SberPortal target device. It has a special microphone system, and this is one of the devices on which our speech recognition should work.
We call this source Farfield-domain, since the distance from the user to the device is usually quite large. For recording via SberPortal in the studio, we used three distances: 1, 3 and 5 meters from the user to the device. Each domain has a training and test part, the resulting structure is shown in the table:
| Domains | Training part | Test part |
|---|---|---|
| Crowd | 979 796 files | 1095 hours | 9994 files | 11.2 hours |
| Farfield | 124 003 files | 132.4 hours | 1916 files | 1.4 hours |
| Total | 1 103 799 files | 1227.4 hours | 11910 files | 12.6 hours |
There is no personal information in the dataset, such as age, gender or user ID - everything is impersonal. The training and test parts may contain the speech of the same user.
| Statistics \ Domains | Crowd | Farfield |
|---|---|---|
| number | 979796 files | 124003 files |
| Average | 4.0 sec. | 3.8 sec. |
| Standard deviation | 1.9 sec. | 1.6 sec. |
| 1st percentile | 1.4 sec. | 2.0 sec. |
| 50th percentile | 3.7 sec. | 3.5 sec. |
| 95th percentile | 7.3 sec. | 6.8 sec. |
| 99th percentile | 10.5 sec. | 9.6 sec. |
The table above provides some statistical information about the entries: mean, standard deviation, and percentiles. For clarity, the figure shows two histograms of the distribution of record lengths:
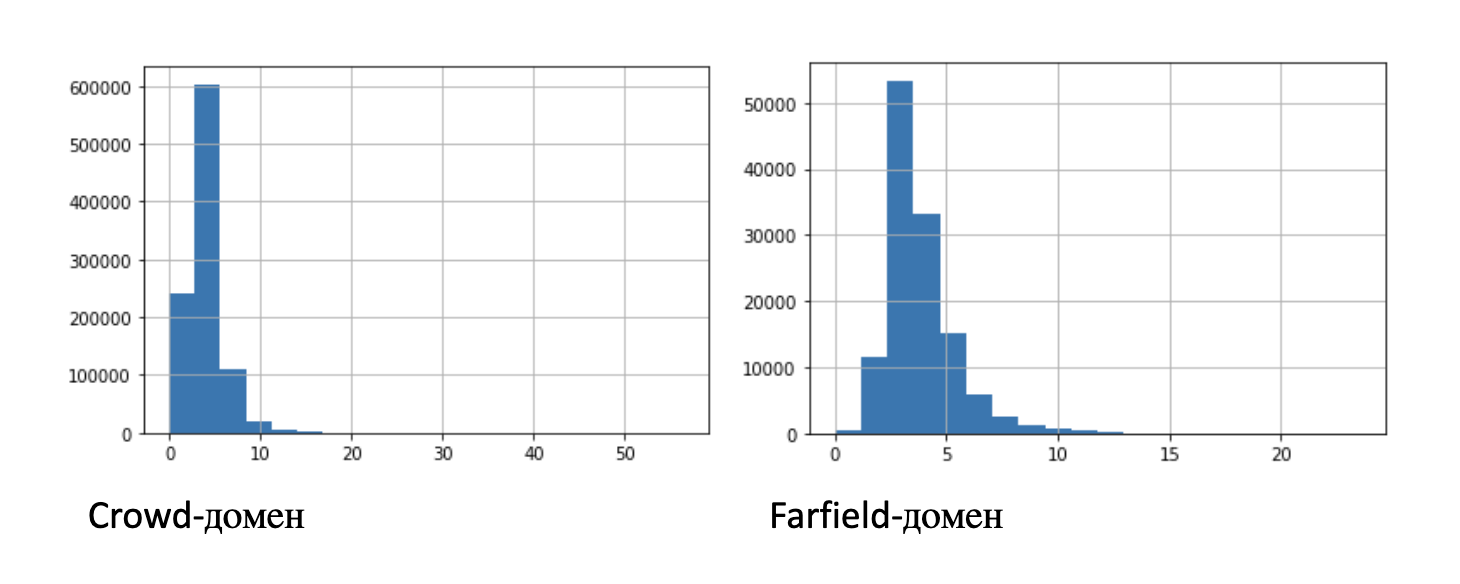
For experiments with a limited number of records, we identified subsets of shorter length: 100 hours, 10 hours, 1 hour, 10 minutes.
Data collection
At SberDevices, we are developing the Salute family of virtual assistants, so we generated speech similar to user requests for an assistant. We have created a template system to describe requests across different domains - music, movies, ordering products, and others. They are expressions that describe the structure of a request and decompose it into components. Using templates, we can generate reasonable queries, retrain the acoustic model, create a language model based on these queries, and much more.
Sample templates:
| Template | Example |
|---|---|
| [command_demands_vp] + [film_syn_vp] + [film_title_ip] | Play the movie green book |
| [command_demands_ip] + [film_syn_ip] + [film_title_ip] | You have a movie green book |
| [command_demands_ip] + [film_title_ip] | Do you have a green book |
| [film_title_ip] + [command_demands_vp] | put green book |
| [film_syn_ip] + [film_title_ip] + [command_demands_vp] | film the green book put |
| [film_title_ip] | green book |
| [command_demands_vp] + [film_title_ip] | turn on the green book |
| [film_syn_ip] + [film_title_ip] | film green book |
| [command_demands_vp] + [film_title_ip] | Turn on the green book |
| ... | ... |
In square brackets - the designation of the corresponding entity. Further in the table for two entities “film_title_ip” and “film_title_vp” there are possible options for filling it in:
| film_title_ip | film_title_vp |
|---|---|
| obsession | obsession |
| the escape | the escape |
| the beauty and the Beast | beauty and the beast |
| Island | Island |
| jane eyre | jane eyre |
| Wuthering Heights | Wuthering Heights |
| ... | ... |
The process of creating a tagged audio dataset consists of several stages:
- Step 1. First, we create templates for a certain domain.
- 2. - . , :
- 3. «» :
- 4. – , , . – . 80% Golos. , “”, , . , , .
- 4*. - , , , , , , . , . , , , , , . , .

- 5*. , . , . , , , . , , , . , , , . , . :

:
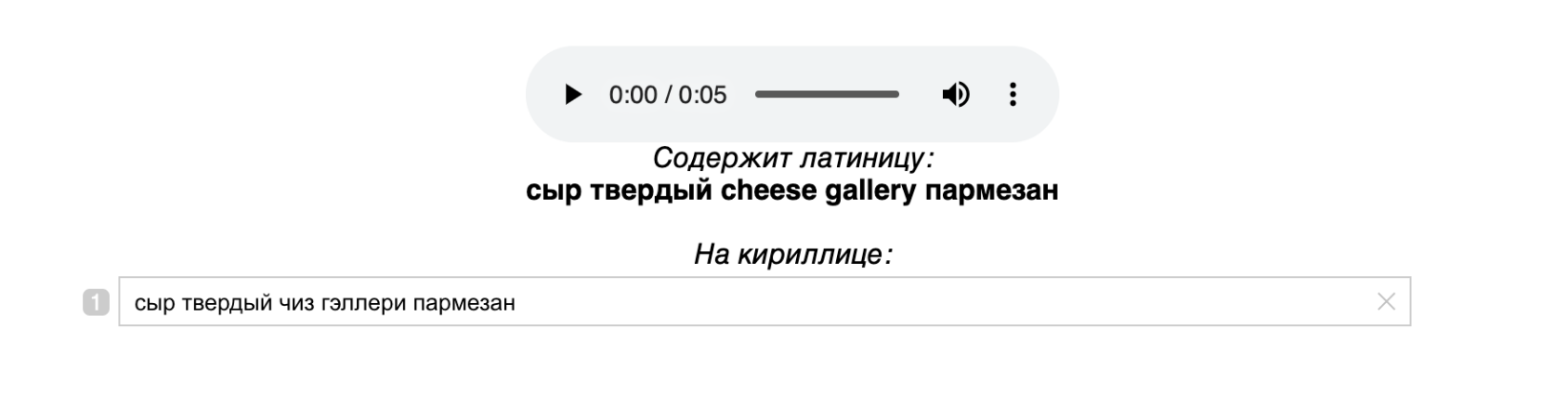
, . .
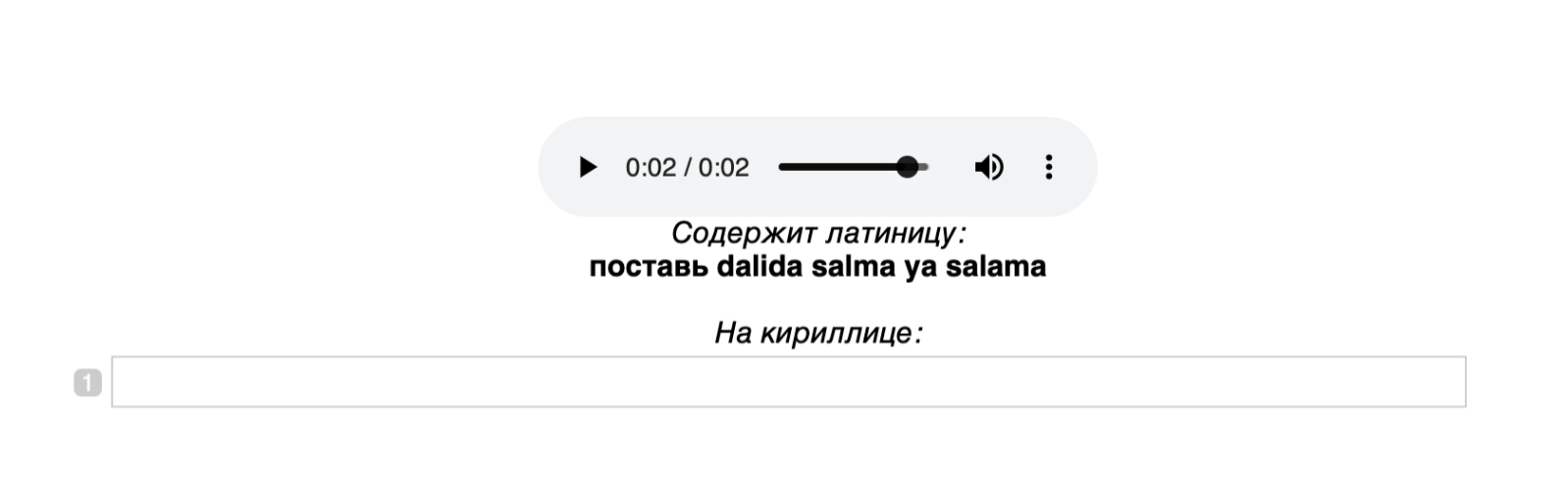
, , , .
- 5 . 3 , .
. -, , . -, . , .
, , “” – , “” - . , , , ( ) . bias , , . , . , .
The described process of creating a dataset allows you to make markup as high quality as possible, which distinguishes it from others created automatically or semi-automatically. We use this data to create a speech recognition system in our devices. Due to the high quality of the markings, the accuracy of the resulting system is comparable to that of a human. All data, along with trained acoustic and language models for speech recognition, are available on the project's GitHub page , as well as in ML Space from Sbercloud , a service for training machine learning models, where our dataset can be downloaded seamlessly right in the interface. We will tell you more about using ML Space and how we used it to teach speech recognition models in the next article.
Currently, there is a lot of open data in English, but there was no such high-quality Russian-language dataset. Now a corpus is also available in Russian, which can be used for speech recognition and synthesis, and the model trained on them shows a very high quality. We believe that the Golos dataset will enable the Russian scientific community to move even faster in improving Russian-language speech technologies.