Hello everyone! I am working with generative models, one of my projects is DeepFake development. I plan to create several articles about this project. This article is the first, in which I will consider the architectures that can be used, their advantages and disadvantages. Of the existing approaches to creating DeepFake, the following can be distinguished:
Codec-based architecture
Generative adversarial networks (GAN)
Encoder-decoder architecture
This approach includes generation methods based on autoencoders. They are united by the use of pixel losses (the input image is compared pixel by pixel with the output image, MSE, MAE, etc. loss functions are optimized) losses, which determines the advantages and disadvantages of this scheme. The upside is that autoencoders are relatively easy (compared to GANs) to train. The disadvantage is that optimization by pixel metrics does not allow achieving photorealism comparable to other methods (again, in comparison with GAN). The first option I considered was a dual decoder circuit. More details can be found here. The architecture is shown in the figure below.
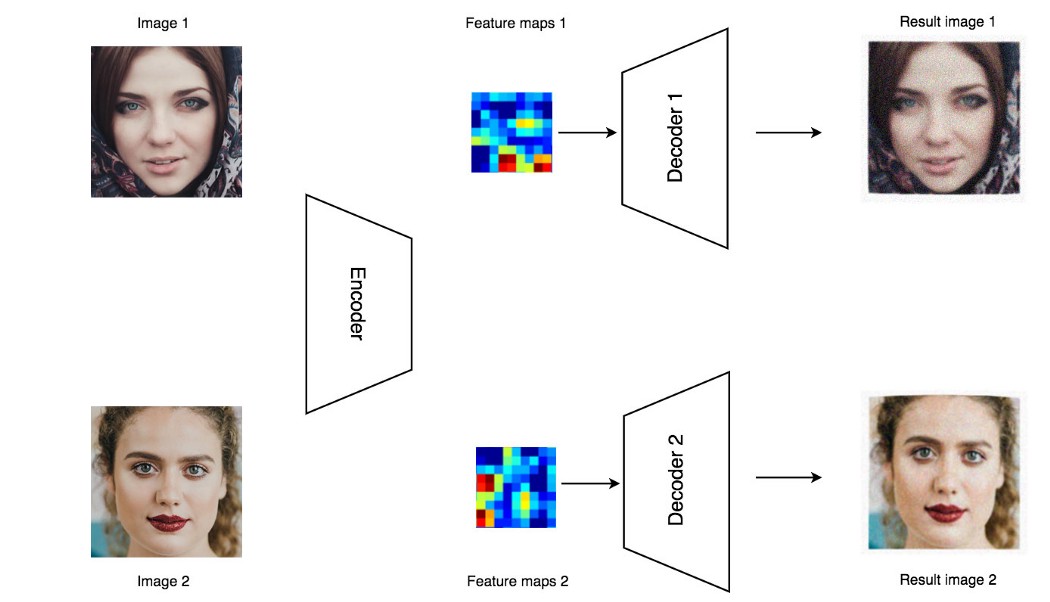
: - , , , . , . , . , DeepFake , , .. , . - , ( ) . " - " , .
Condtional Autoencoder
. .

: . latent_dim . , / ( ), , .. .. , . .. , atrributes vectors , , , , .. atrributes vectors , , , . , , .. atrributes vectors . .

, - , - . - "", . , .. .
Conditional GAN
GAN , . .. DeepFake ( - , ), Conditional GAN. GAN Conditional GAN . , .

GAN, . , .. , , . Conditional Gan - Z ( label). . , . Conditional GAN .

( - , - ). attributes vectors , . X GAN . , , GAN . , - DeepFake, , . . DeepFake GAN :
The development of the project continues at the moment. Many improvements are planned, first of all - increasing the resolution, working out scenes with complex lighting. If interested, as new results appear, there will be new publications.