
!
, Head of AI Celsus. .
, , ML- . «» — , , .
ML- DS-, , CV .
So, suppose you decide to found an AI start-up to detect breast cancer (by the way, the most common type of oncology among women) and are going to create a system that will accurately detect signs of pathology on mammography examinations, insure the doctor against errors, and reduce the time to make a diagnosis ... A bright mission, isn't it?

You have assembled a team of talented programmers, ML engineers and analysts, bought expensive equipment, rented an office and thought out a marketing strategy. Everything seems to be ready to start changing the world for the better! Alas, everything is not so simple, because you forgot about the most important thing - about data. Without them, you cannot train a neural network or other machine learning model.
This is where one of the main obstacles lies - the quantity and quality of the available datasets. Unfortunately, there are still very few high-quality, verified, complete datasets in the field of diagnostic medicine, and even fewer of them are publicly available to researchers and AI companies.
Consider the situation using the same example of breast cancer detection. More or less high-quality public datasets can be counted on the fingers of one hand: DDSM (about 2600 cases), InBreast (115), MIAS (161). There is also OPTIMAM and BCDR with a rather complicated and confusing procedure for gaining access.
And even if you were able to collect a sufficient amount of public data, the next obstacle awaits you: almost all of these datasets are allowed to be used only for non-commercial purposes. In addition, the markup in them can be completely different - and it is not a fact that it is suitable for your task. In general, without collecting your own datasets and their markup, it will be possible to make only an MVP, but not a high-quality product ready for operation in combat conditions.
So, you sent out requests to medical institutions, raised all your connections and contacts and received a motley collection of various pictures in your hands. Do not rejoice ahead of time, you are at the very beginning of the path! Indeed, despite the presence of a unified standard for storing medical images, DICOM(Digital Imaging and Communications in Medicine), in real life everything is not so rosy. For example, information about the side (Left / Right) and projection ( CC / MLO ) of a breast image can be stored in completely different data sources in different data sources. The only solution here is to collect data from as many sources as possible and try to take into account all possible options in the logic of the service.
What you mark up is what you reap
We finally got to the fun part - the data markup process. What makes it so special and unforgettable in the medical field? Firstly, the process of marking itself is much more complicated and longer than in most industries. X-ray images cannot be uploaded to Yandex.Toloka and you can get a tagged dataset for a penny. This requires painstaking work of medical specialists, and it is advisable to give each image to several doctors for marking - and this is expensive and time-consuming.
Further worse: experts often disagree and give completely different markings of the same images at the output. Doctors have different qualifications, education, level of "suspicion". Someone marks all objects in the picture neatly along the contour, and someone - with wide frames. Finally, one of them is full of energy and enthusiasm, while another is marking up pictures on a small laptop screen after a twenty hour shift. All these discrepancies naturally "drive" neural networks crazy, and you will not get a high-quality model under such conditions.
The situation is also not improved by the fact that most of the errors and discrepancies occur precisely in the most complex cases, the most valuable for training neurons. For example, researchshow that most of the mistakes doctors make when making a diagnosis on mammograms with an increased density of breast tissue, so it is not surprising that they are the most difficult for AI systems as well.
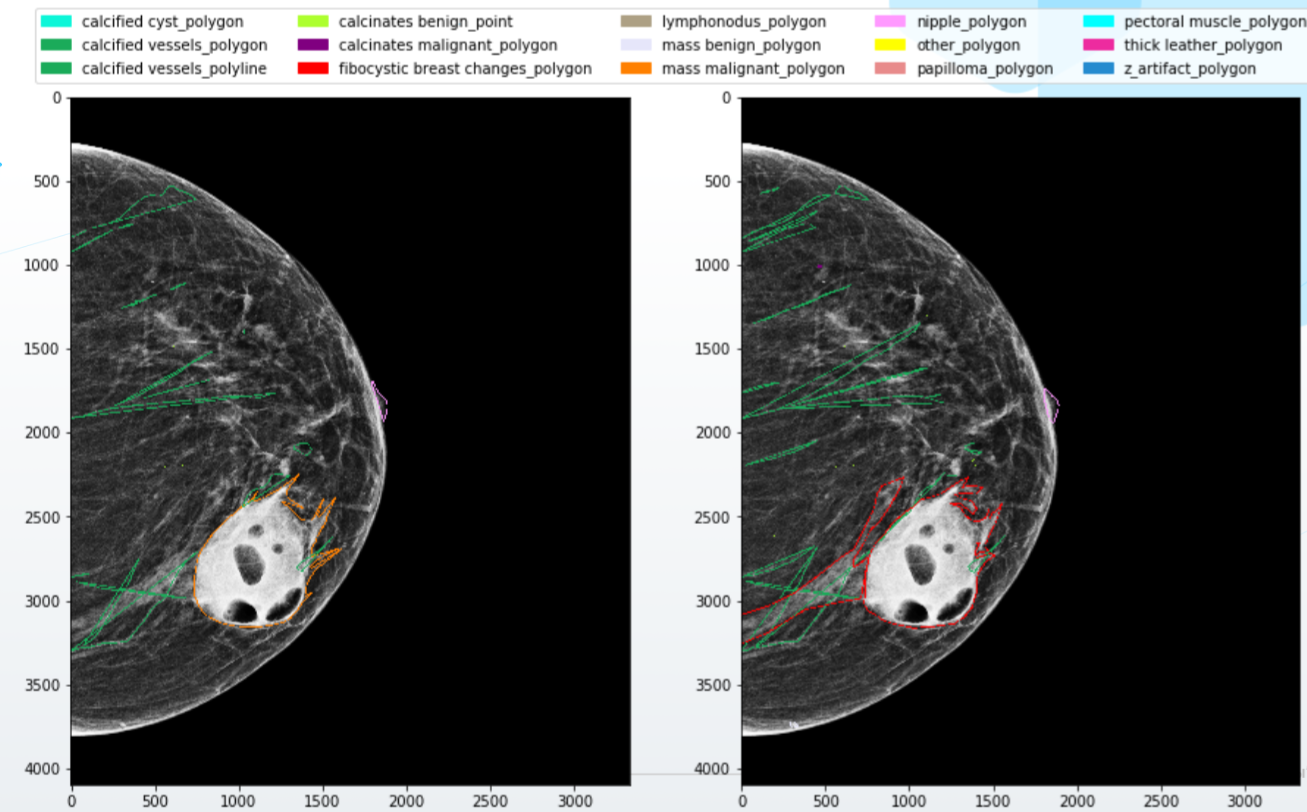
What to do? Of course, first of all, you need to build a high-quality system of interaction with doctors. Write detailed rules for markup, with examples and visualizations, provide specialists with high-quality software and equipment, write down the logic for combining minor conflicts in markup and ask for additional opinion in case of more serious conflicts.
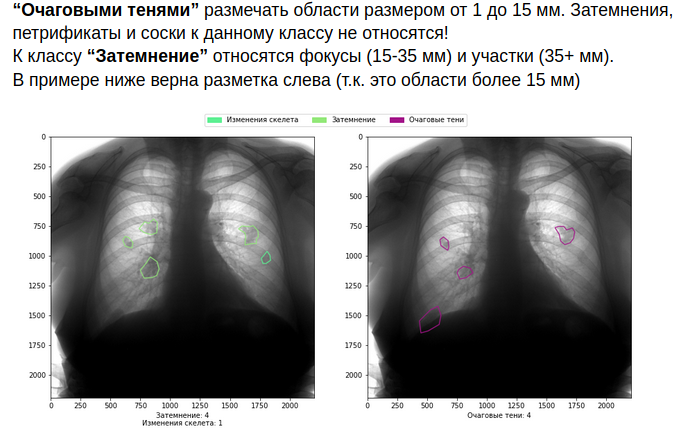
As you can imagine, all this increases the cost of the markup. But if you are not ready to take them upon yourself, it is better not to get into the field of medicine.
Of course, if you approach the process wisely, then costs can and should be reduced - for example, through active learning. In this case, the ML-system itself prompts doctors which images need to be additionally marked in order to maximize the quality of pathology recognition. There are different ways to assess the confidence of a model in its predictions - Learning Loss, Discriminative Active Learning, MC Dropout, entropy of predicted probabilities, confidence branch, and many others. Which one is better to use, only experiments on your models and datasets will show.
Finally, you can completely abandon the markup of doctors and rely only on the final, confirmed outcomes - for example, the death or recovery of the patient. Perhaps this is the best approach (although there are a lot of nuances here too), but it can only start working in ten to fifteen years, at best, when full-fledged PACS (picture archiving and communication systems) and medical information systems (MIS) and when enough data has been accumulated. But even in this case, no one guarantees the purity and quality of this data.
Good model - good preprocessing

Hooray! The model has been trained, shows excellent results, and is ready to be piloted. Cooperation agreements were concluded with several medical organizations, the system was installed and configured, a demonstration was carried out to doctors and the capabilities of the system were shown.
And now the first day of the system operation is over, you open the dashboard with metrics with a sinking heart ... And you see the following picture: a bunch of requests to the system, with zero objects detected by the system and, of course, a negative reaction from doctors. How so? After all, the system proved to be excellent in internal tests!
Upon further analysis, it turns out that in this medical institution there is some kind of X-ray machine unfamiliar to you with its own settings, and as a result, the images look completely different. The neural network was not trained on such images, so it is not surprising that it "fails" on them and does not detect anything. In the machine learning world, such cases are commonly referred to as Out-of-Distribution Data. Models usually perform significantly worse on such data, and this is one of the main problems of machine learning.
Illustrative example: our team tested a public modelfrom researchers at New York University, trained on a million images. The authors of the article argue that the model demonstrated high quality of detection of oncology on mammograms, and specifically they speak about the ROC-AUC accuracy indicator in the region of 0.88-0.89. On our data, the same model demonstrates significantly worse results - from 0.65 to 0.70, depending on the dataset.
The simplest solution to this problem on the surface is to collect all possible types of images, from all devices, with all settings, mark them up and train the system on them. Minuses? Again, long and expensive. In some cases, you can do without markup - unsupervised learning will come to your aid. Unlabeled images are given to the neuron in a certain way, and the model "gets used" to their features, which allows it to successfully detect objects in similar images in the future. This can be done, for example, using pseudo-markup of untagged images or various auxiliary tasks.
However, this is not a panacea either. In addition, this method requires you to collect all types of images existing in the world, which, in principle, seems to be an impossible task. And the best solution here would be to use universal preprocessing.
Preprocessing is an algorithm for processing input data before feeding it into a neural network. This procedure can include automatic changes in contrast and brightness, various statistical normalization and removal of unnecessary parts of the image (artifacts).
For example, after many experiments, our team managed to create a universal preprocessing for X-ray images of the mammary gland, which brings almost any input images to a uniform form, which allows the neural network to correctly process them.

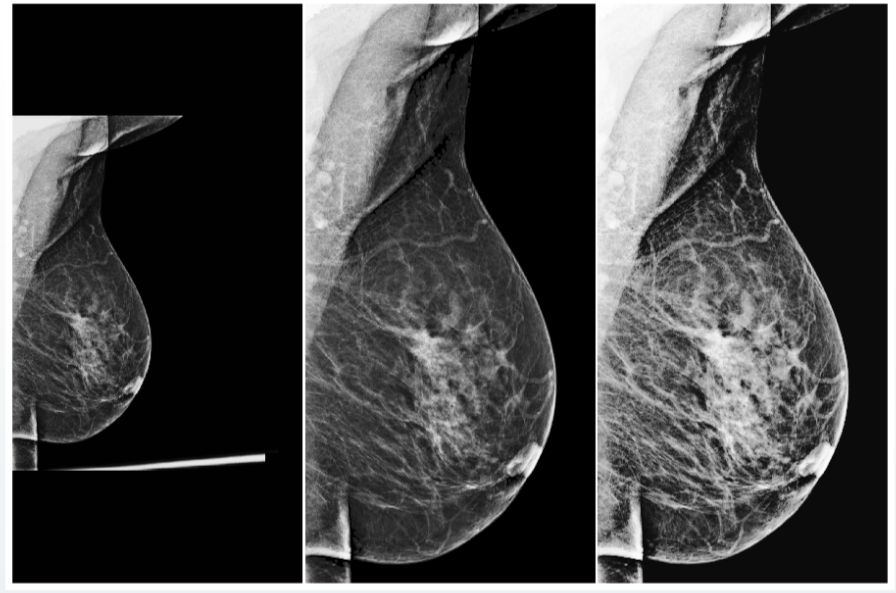
But even with universal preprocessing, you shouldn't forget about input data quality checks. For example, in fluorographic datasets, we often came across test images, which included bags, bottles and other objects. If the system assigns any probability of the presence of pathology in such an image, this clearly does not increase the confidence of the medical community in your model. To avoid such problems, AI systems must also signal their confidence in correct predictions and in the validity of the input data.

Different hardware is not the only problem with the ability of AI systems to generalize, generalize, and work with new data. A very important parameter is the demographic characteristics of the dataset. For example, if your training sample is dominated by Russian people over 60, no one can guarantee that the model will work correctly on young Asians. It is imperative to monitor the similarity of the statistical indicators of the training sample and the real population for which the system will be used.
If any discrepancies are found, it is imperative to conduct testing, and most likely, additional training or fine tuning of the model. It is imperative to conduct constant monitoring and regular revision of the system. In the real world, a million things can happen: the X-ray machine has been replaced, a new laboratory assistant has come who does research in a different way, crowds of migrants from another country suddenly flooded into the city. All this can lead to degradation of the quality of your AI system.
However, as you might have guessed, learning isn't everything. The system needs to be assessed at a minimum, and standard metrics may not be applicable in the medical field. This also makes it difficult to evaluate competing AI services. But this is the topic for the second part of the material - as always, based on our personal experience.