Many projects now use microservice architecture. We are also no exception, and for more than 2 years now we have been trying to build RBS for legal entities in a bank using microservices.

Authors of the article: ctimas and Alexey_Salaev
The importance of microservice architecture
Our project is an RBS for legal entities. Many different processes under the hood and a nice minimalistic interface. But it was not always so. For a long time we used a solution from a contractor, but one fine day it was decided to develop our product.
There was a lot of discussion when starting the project: which approach to take? how to build our new RBS system? It all started with discussions “monolith vs microservices”: discussed possible programming languages used, argued about frameworks (“should I use spring cloud?”, “Which protocol should I choose for communication between microservices?”). These questions, as a rule, have a limited number of answers, and we simply choose specific approaches and technologies depending on the needs and capabilities. And the answer to the question "How to write microservices themselves?" was not entirely straightforward.
Many might say, “Why develop a general architecture concept for the microservice itself? There is an enterprise architecture and a project architecture, and a general vector of development. If you assign a task to the team, it will complete it, and the microservice will be written and it will perform its tasks. After all, this is the essence of microservices - independence. " And they will be absolutely right! But over time, teams become larger, therefore, the number of microservices and employees is growing, and there are fewer old-timers. New developers come who need to immerse themselves in the project, some developers change teams. Also, teams cease to exist over time, but their microservices continue to live, and in some cases they need to be improved.
While developing the general concept of the microservice architecture, we leave ourselves a large reserve for the future:
- ;
- ;
- : .
Everyone who works with microservices is well aware of their pros and cons, one of which is the ability to quickly replace an old implementation with a new one. But how small does a microservice have to be so that it can be easily replaced? Where is the boundary that determines the size of the microservice? How not to make a mini monolith or a nanservice? And you can always go straight to the side of functions that perform a small part of the logic and build business processes by building the order of calling such functions ...
We decided to single out microservices by business domains (for example, the microservice for ruble payments), and build the microservices themselves according to the tasks of this domain.
Let's consider an example of a standard business process for any bank - "creating a payment order"

You can see that a seemingly simple client request is a fairly large set of operations. This scenario is approximate, some stages are omitted for simplicity, some of the stages occur at the level of infrastructure components and do not reach the main business logic in the product service, the other part of the operations works asynchronously. The bottom line is that we have a process that at one point in time can use many neighboring services, use the functionality of different libraries, implement some kind of logic inside itself and save data to various storages.
Taking a closer look, you can see that the business process is quite linear and in the course of its work it will either need to get some data somewhere or somehow process the data that it has, and this may require working with external data sources (microservices, databases) or logic (libraries).

Some microservices do not fit this concept, but the number of such microservices in the overall percentage is small and amounts to about 5%.
Clean architecture
After looking at different approaches to organizing code, we decided to try a “clean architecture” approach by organizing the code in our microservices as layers.
Regarding the "clean architecture" itself, more than one book has been written, there are many articles both on the Internet and on Habré ( article 1 , article 2 ), more than once its pros and cons have been discussed.
A popular diagram that can be found on this topic was drawn by Bob Martin in his book Clean Architecture:

Here, the pie chart on the left in the center shows the direction of dependencies between layers, and modestly in the right corner you can see the direction of the flow of execution.
This approach, as, indeed, in any programming technology, has its pros and cons. But for us there are much more positive aspects than negative ones when using this approach.
Implementation of "clean architecture" in the project
We have redrawn this diagram based on our scenario.
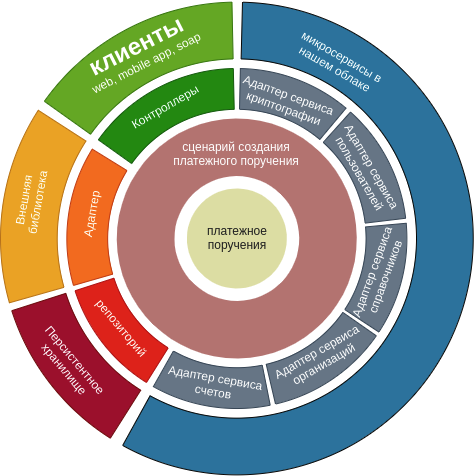
Naturally, this diagram reflects one scenario. It often happens that a microservice performs more operations on one domain entity, but, in fairness, many adapters can be reused.
Different approaches can be used to separate the microservice into layers, but we chose division into modules at the level of the project builder. Implementation at the module level provides an easier visual perception of the project, and also provides another layer of protection for projects against misuse of the architectural style.
From experience, we noticed that when immersing in a project, a new developer just needs to familiarize himself with the theoretical part and he can easily and quickly navigate almost any microservice.
We use Gradle to build our microservices in Java, so the main layers are formed as a set of its modules:

Now our project consists of modules that either implement contracts or use them. For these modules to start working and solving problems, we need to implement dependency injection and create an entry point that will launch our entire application. And here there is an interesting question in the book Uncle Bob "Pure architecture" there are whole chapters that tell us about the details, models and frameworks, but we do not build its architecture around the framework or around the database, we use them as one of the components ...
When we we need to save the entity, we refer to the database, for example, in order for our script to receive the contract implementations it needs at the time of execution, we use the framework that gives our architecture DI.
There are tasks when we need to implement a microservice without a database, or we can abandon DI, because the task is too simple and it is faster to solve it head-on. And if we will carry out all the work with the database in the "repository" module, then where do we use the framework to prepare all the DI for us? There are not so many options: either we add a dependency to each module of our application, or we will try to select the entire DI as a separate module.
We have chosen a separate new module approach and call it either “infrastructure” or “application”.
True, when such a module is introduced, the principle is slightly violated, according to which we direct all dependencies to the center to the domain layer, since it must have access to all classes in the application.
It will not work to add an infrastructure layer to our onion in the form of a layer, there is simply no place for it there, but here you can look at everything from a different angle, and it turns out that we have a circle “Infrastructure” and our puff onion is on it ... For clarity, let's try to move the layers apart a little to make it better visible:

Add a new module and look at the tree of dependencies on the infrastructure layer to see the final dependencies between the modules:

Now all that remains is to add the DI framework itself. We use Spring in our project, but this is optional, you can take any framework that implements DI (for example, micronaut).
How to build a microservice and where which part of the code will be - we have already decided, and it is worth looking at the business scenario again, because there is another interesting point.
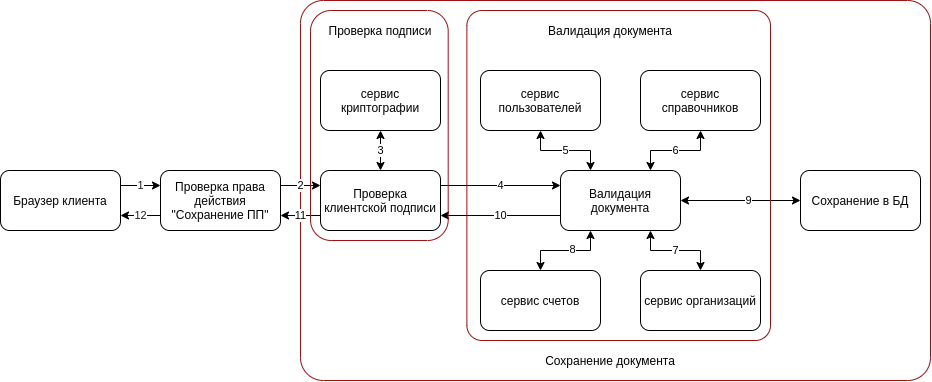
The diagram shows that checking the right of action may not be performed in the main script. This is a separate task that does not depend on what happens next. Signature verification could be moved to a separate microservice, but here there are many contradictions when defining the boundary of the microservice, and we decided to just add another layer to our architecture.
In separate layers, it is necessary to highlight the stages that can be repeated in our application, for example, signature verification. This procedure can occur when creating, changing or signing a document. Many main scripts start the smaller operations first and then only the main script. Therefore, it is easier for us to isolate the smaller operations into small scripts, broken down into layers so that they can be reused more easily.
This approach makes business logic easier to understand, and over time, a set of small business building blocks will be formed that can be reused.
There is not much to say about the code of adapters, controllers and repositories. they are quite simple. Adapters for another microservice use a generated client from a swagger, a spring RestTemplate or a Grpc client. In repositories - one of the variations of using Hibernate or other ORMs. The controllers will obey the library you will be using.
Conclusion
In this article, we wanted to show why we are building a microservice architecture, what approaches we use and how we develop. Our project is young and is only at the very beginning of its journey, but already now we can highlight the main points of its development from the point of view of the architecture of the microservice itself.
We are building multi-module microservices, where the advantages include:
- , - , , - , ;
- , , - ;
- , Api, , , , ;
- , , , , .
Not without, of course, a fly in the ointment. For example, the most obvious thing is that often each module works with its own small models. For example, in the controller you will have a description of the rest models, and in the repository there will be database entities. In this connection, you have to map objects to each other a lot, but tools such as “mapstruct” allow you to do this quickly and reliably.
Also, the disadvantages include the fact that you need to constantly monitor other developers, because there is a temptation to do less work than it costs. For example, moving the framework a little further than one module, but this leads to the erosion of the responsibility of this framework in the entire architecture, which in the future may negatively affect the speed of improvements.
This approach to implementing microservices is suitable for projects with a long lifespan and projects with complex behavior. Since the implementation of the entire infrastructure takes time, but in the future it pays off with stability and quick improvements.