
SberCraft, CyberCode, Luxcity - you may have heard of these games or even participated in them. All this is Geecko's handiwork. The largest Geecko projects collect 20 thousand players each, while until recently the company did not have a dedicated team to support the infrastructure.
The company's service station Nikita Obukhov and Marketing Director Irina Fedorova spoke about the incident, which became one of the arguments to seriously think about infrastructure changes, moving to K8s and hiring a DevOps team.
What is inside:
- loss of control over Facebook,
- a sudden rush of traffic on Friday night,
- Grant from Microsoft Azure, Cloud Moving and Transformation Challenges.
Go!
Geecko — DevRel . IT- , : , , -.
Geecko
What engine are the games made on, what are they technically?
Nikita: Our games are exclusively browser-based. We use our own developments and proven libraries to work with Canvas, maps, isometry. We use JS / TS, a Vue.js framework for a typical web UI.
We are not yet writing for mobile platforms - at best, we support mobile permissions. But this is not often necessary - in most of our games you need to write code, and writing code from a mobile phone is such a convenience.
How demanding are games on CPU and memory?
Nikita: In our games, we need to write code, and we need to execute this code.
We support 12 languages: both compiled and interpreted in different environments. We execute the code on our server resources: the load on the processor and memory is intensive.
We are also launching LSP services that provide autocomplete code for our online IDE. They also require CPU and especially memory: when there are a lot of players, the load increases significantly.
Where are the games hosted?
Nikita: It was always clouds. Now the main provider is Azure (Geecko received a grant from Microsoft for free use of the cloud - ed.). We launch all new projects there - and, what is important for us, we launch them in Kubernetes. All new infrastructure is based on Kubernetes and Docker.
Which provider did you have before and why did you decide to switch?
Nikita: We have been and are still represented in DigitalOcean and Yandex.Cloud. They are good providers, but Microsoft turned out to be the most suitable grant program for us.
How much did you spend on servers before and spend now?
Nikita: Six months ago, we spent about 30 thousand rubles a month, now this figure is approaching 100 thousand. The growth is related to the number of projects: we do not stop the old ones, they continue to work and receive organic registrations. We regularly launch new activities: in one month we can release three projects - for example, one battle, one game and a meetup.
Does Microsoft Grant Cover All Costs?
Nikita: Our infrastructure costs have not become zero: we cannot transport everything at once, this is not economically feasible. Therefore, two more cloud providers continue to work with us, their share is simply decreasing.
Backups in other geographic areas, disaster recovery of resources in another cloud - all this is important.
Overall, overall costs are reduced. The code execution service has the largest resource consumption, and thanks to the grant, its costs in the coming year will be zero. If a number of conditions are met, the grant will be extended for a second year.

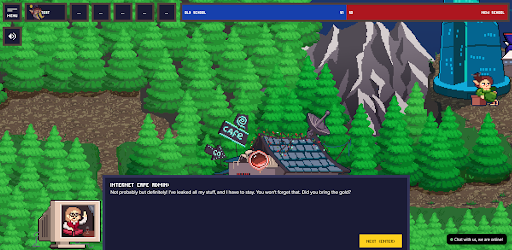
Screenshot from Cybercode game
Friday's rush of Facebook traffic
Have you had a situation where an influx of users dropped production?
Nikita: Yes, once there was an incident close to this. We had a task from an international company: to find many English-speaking developers.
By design, players must collectively complete the mission while on the same map. The map has finite dimensions, so it is impossible to place everyone on it. We divided users into clusters of 100 people, each of whom lives no more than five days - this is the game cycle for completing the mission. During this time, the participants either win or lose.
We expected that up to 10 such cards would be active at the same time, that is, up to 1000 players. But in fact, there were more than 2000 players or 20 cards at the peak.
Why did it happen? Why did so many users suddenly come to the game?
Irina: The story happened in early March, when Facebook began to massively and spontaneously block advertising accounts for inconsistency with the policy for advertisers. A lot of companies then lost their advertising offices, including us: our main office and both backup offices fell. And all this at the very moment when we had to promote the game.
Facebook is one of the main promotion channels, because it is easy enough to select an audience and segment it based on the available data. And for 12 days we lost access to this channel. When we returned it with sweat, blood and tears, we had to catch up with the KPI - 4500 liquid registrations for certain geolocations, mainly in Europe.
There was no choice but to push the budget: we sped up our advertising campaigns.
What does it mean to "push with the budget"?
Irina: If we initially spent 300-500 dollars a day, then we went over 1000.
You have to understand that usually advertising campaigns are trained for several days, and then they start working as profitably as possible. But our advertising budget was larger than usual, so the campaign learned faster and on the second day it started to spin really cool indicators. At some point, we lost control of her.
We were counting on a certain conversion rate, but it turned out to be more simply due to the fact that Facebook overclocked. If the average conversion rate in such games is about 8%, then at the peak moment it reached 15%.
Cool!
Irina: Yes, it was then that we understood what a large advertising budget means. True, this only works in the case of the West - in Russia there is simply no audience to spend so much money.
And, of course, it all happened on Friday. Classic! On Friday evening, I receive a message from Nikita that we have so much traffic that we need to do something about it.
How did Nikita know about this? Where did this signal come from?
Nikita: We have automatic server load notifications. This is how it looked:

An alert comes that the virtual machine (8 cores, 32 GB of memory) is loaded by 90% on the CPU at the threshold value of 50%.
This is not critical, as the service continues to work. For players, this means that they press the "Run Code" button and wait twice as long for execution. But it also means that if new players keep coming in, the situation will get worse, right down to downtime.
As a result, the worst outcome was avoided - the service did not go down completely?
Nikita: Fortunately, everything ended well.
Of course, if the situation had arisen in the middle of the working day, we would not have worried at all - there you can react quickly. But not Friday night. On Friday night, you go to a bar and get this message on your phone. But to fix everything, it is not enough to be on the phone.
How did you manage the situation?
Irina: We just reduced the cost of advertising campaigns by almost 70%.
Did you get back on track later?
Irina: No, they did not bring it to the same state, because the situation was unpredictable: Facebook was increasing and increasing conversion every day. If we had been spinning at the same speed for another week, perhaps the conversion would have been even higher. But heroic victories were not required, so we restored a comfortable level. It turned out about 10 loaded maps, and the service worked quietly.
Nikita: It should be noted that there are other sides of the issue: we try to respond promptly to players' messages. The more players, the more support requests they generate. We wanted to maintain a high level of service, and we were not ready to increase the amount of support so quickly. We decided that it would be wiser to do everything more smoothly and predictably than to peak at the weekend.
This time you decided to stifle the advertising campaign and thereby saved the situation. How do you usually solve a scaling problem from a technical point of view?
Nikita: We are scaling by launching additional instances of the service.
In this case, it is not Kubernetes and there is no autoscale. It is necessary to start a virtual machine clone in semi-manual mode - you have to wait up to half an hour while the VM is recreated from the image. After that, you need to check that the VM is working as expected and all services on it have risen: LSP servers, code runners. After that, we balance traffic to new machines and continue to monitor the workload and status codes.
Screenshot from SberCraft game
Conclusions and plans
How did you rearrange your work after this incident?
Nikita: We figured out how best to plan marketing: how much investment does what amount of registrations give.
At the technical level, we have become firmly convinced that we need a new way to scale the code execution service, ideally - autoscale.
We make the code execution service stateless (independent of the storage system), make small architectural changes and change the infrastructure - we introduce the same Kubernetes on which other services run.
But in the case of a code execution service, the scheme is more complicated - it is not as easy to translate it as the others. We are still checking that everything is working as it should.
Right now, the code is running on DigitalOcean and will run on the Azure cloud. In Kubernetes.
There you are using Kubernetes as a service (Azure Kubernetes Service)?
Nikita: Yes. We are using Kubernetes as a service and are also considering Cloud Functions.
How is AWS Lambda?
Nikita: Yes, all major providers have them. They allow you to pay exactly as much as you do code runs. But there are technical limitations in the capabilities of runtime environments.
Who is in charge of the infrastructure now?
Nikita: My qualifications and qualifications of back-end developers are not always enough, because DevOps, SRE are a very wide area. And leaving back-end developers on duty for incidents is not very correct. Therefore, at the beginning of the year, we had an outsourcing DevOps team - the guys with whom we previously worked in other businesses.
Why did you start collaborating with the infrastructure and DevOps team?
Nikita: The incident with the game was the catalyst for changes that we have long recognized, but had no opportunity to implement.
The company has grown, similar cases began to occur, which confirmed: yes, guys, you need DevOps engineers, you need to make an infrastructure that will be easier to scale.
The task was fully taken care of two months ago, when we received a grant from Azure. By now, many services have been moved to the new cloud.
Why did you decide to outsource rather than hire people?
Nikita: From our own experience, we know that DevOps is a difficult area to recruit. And here it turned out that there are proven guys, and the form of working with a contractor is very convenient for us.
Well, and most importantly: we acquired not one engineer, but a whole team that monitors the availability of services around the clock and is ready to respond to an incident before it is discovered by users.
Is the DevOps team setting up everything from scratch or using what it was, including monitoring?
Nikita: We took the path of displacement. We start new projects in a new infrastructure, migrate core services there, and leave projects under support in the old one. Everything is new for new projects, including monitoring.
The peculiarity of the transformation is that you have to rethink the architecture of the service. We understood how it can be changed to get new qualities.
Therefore, work is also happening on the backend side: we will refactor the code, update the architecture, but in a fairly moderate amount.
So you're setting up new CI / CD processes right now?
First of all, we are restructuring organizationally. We have a new role, corresponding to the dedicated team, and the ways of communication, setting tasks have changed.
We had CI / CD processes, they just started rolling over to the new infrastructure. Of course, they are improving, but they do not fundamentally change.
Screenshot from the game SberCraft
What global conclusion have you made for yourself?
At different stages of the life of a project, things are different. Six months ago, we would not have been ready for the DevOps team ourselves. But now we can communicate with them much more substantively. We clearly understand our pains and came to the guys with a list of questions and suggestions on how to do something. It turned out to be a good collaboration: together we came to high-quality and well-grounded decisions.
There is a lot of work ahead. The code execution service in the migration process, and as the most complex of our services, will require a lot of involvement. For some time we will have both versions of the service in production and balance traffic between them. When we understand that everything is fine, we will completely switch to Azure.
, . , .
, , , .
21 «» , .
:
— ,
— ,
— ,
— ,
— .
Databricks, Mail.ru Cloud Solutions TangoMe.