
The translation of the material was prepared as part of the online course "Ecosystem Hadoop, Spark, Hive".
We invite everyone to a free webinar "Testing Spark Applications" . In an open lesson, we will consider the problems in testing Spark applications: stat data, partial verification and start / stop of heavy systems. Let's study the libraries for the solution and write tests.
Apache Spark . : , .
Spark Streaming
Clairvoyant , - . , , , . , Apache Nifi, Apache Flume, Apache Flink . — Spark Streaming.
Spark Streaming — Core Apache Spark , . .

Spark Streaming . , ( X ) Spark Streaming Spark Engine. Spark - , (Directed Acyclic Graph, DAG) , .

Spark Streaming , Spark . .
, Spark Streaming , Spark Streaming, . , :
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String]
(topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
:
StreamingContext
, 2
Kafka DStream
RDD DStream
StreamingContext
, Apache Kafka .
YARN
, Spark:
JAR ( Python)
spark-submit:
$ spark-submit --class “org.apache.spark.testSimpleApp” --master
local[4] /path/to/jar/simple-project_2.11–1.0.jar
spark-submit master local[4]. , Spark , , .
Spark:
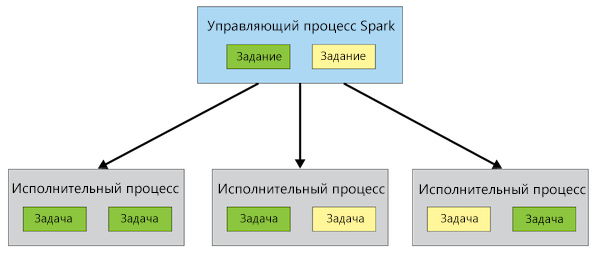
Spark Driver. (master) , , ( — DAG, Java, Scala Python). (Executor) , , , .
, , Spark Hadoop, YARN (Yet Another Resource Negotiator — « »). , , YARN Spark Driver Executor. YARN master:
Spark 1.6.3
YARN : --master yarn-client
YARN : --master yarn-cluster
Spark 2.0
YARN : --master yarn --deploy-mode client
YARN : --master yarn --deploy-mode cluster
2 : . Spark Driver: . .
YARN

Spark Driver - ( , spark-submit). , Spark . Spark. Spark Streaming, .
Spark Streaming — , . , Spark Streaming, ? .
YARN

Spark Driver YARN. , - , YARN . , , , .
spark.yarn.maxAppAttempts
. , YARN.
spark.yarn.am.attemptFailuresValidityInterval
Application Master (AM). AM , AM . , .
, :
spark.yarn.maxAppAttempts=2
spark.yarn.am.attemptFailuresValidityInterval=1h,
.
spark-submit:
$ spark-submit
--class "org.apache.testSimpleApp"
--master yarn
--deploy-mode cluster
--conf spark.yarn.maxAppAttempts=2
--conf spark.yarn.am.attemptFailuresValidityInterval=1h
/path/to/jar/simple-project_2.11-1.0.jar
:
val sparkConf = new SparkConf()
.setAppName("App")
.set("spark.yarn.maxAppAttempts", "1")
.set("spark.yarn.am.attemptFailuresValidityInterval", "2h")
val ssc = new StreamingContext(sparkConf, Seconds(2))
, , Spark Streaming , , . .
YARN Spark Streaming :
$ yarn application -kill {ApplicationID}
, , Spark Streaming?
, : , , .
, , Spark Kafka ( Kafka , ), Spark Streaming , , , .
, , , Spark Streaming , .
:
// Start the computation
ssc.start()
ssc.awaitTermination() <--- REMOVE THIS LINE
Spark Streaming :
Spark Streaming: HDFS.
Spark Code: , . , .
: , .
: .
Spark:
— , , . awaitTermination while. , HDFS. , true while StreamingContext.
, , , . Spark Streaming .
. : http://spark.apache.org/docs/latest/monitoring#metrics
StreamingListener (Spark ≥ 2.1)
Apache Spark 2.1 , Spark Streaming. :
onBatchSubmitted
onBatchStarted
onBatchCompleted
onReceiverStarted
onReceiverStopped
onReceiverError
, . ( , , . .) . , , .
Spark

Spark Apache Spark . , , : . . , , , . . , Spark Streaming .
, Apache Spark. , RDD DataFrame, , RDD. Spark , RDD DataFrame .
Spark Streaming, , Spark Streaming, — .
, , , , HDFS. , Spark Streaming. , , :
. , ;
DStream. DStream, ;
. , , .
, , updateStateByKey reduceByKeyAndWindow.
:
val checkpointDirectory = "hdfs://..." // define checkpoint directory
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc // Return the StreamingContext
}
// Get StreamingContext from checkpoint data or create a new one
val ssc = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext)
ssc.start() // Start the context
.
Spark
Spark .
DStream, , . , , , , .
Kafka
Kafka Spark Streaming, Kafka . , .
Kafka ( ):
kafka-topics --zookeeper <host>:2181 --create --topic <topic-name> --partitions <number-of-partitions> --replication-factor <number-of-replicas>

Kafka, , Kafka. Kafka , . null, .

, Spark Streaming Kafka . «» Spark. Spark Kafka, . Kafka ( ), .
Kafka
Kafka, , 2 : . , : « ?», , , « ?». , .

, — Spark Streaming ( , Twitter, Kinesis .). . . - , API Kafka Kafka. (Write Ahead Log — WAL). Kafka ( ). WAL, Spark .
: , . , , , WAL.
. , , :
— WAL ;
WAL — . , : spark.streaming.receiver.wrteAheadLog.enable=true;
StorageLevel WAL — HDFS, , : StorageLevel.MEMROY_AND_DISK_SER.
, Spark Streaming, - . ?
: Kafka , . WAL? : WAL , Kafka . : .

WAL, WAL Kafka. , . , . , 1 2000–2050, 2 — 2051–2100. .
: , . , , .
Kafka
, , Spark Streaming « ». , , , . , Spark Streaming ( — « », « »). Spark Streaming .
, , — Kafka, , Spark Streaming Kafka. , . , .
, . , « ».
, .

, Kafka DStream, loadOffsets:
val storedOffsets: Option[mutable.Map[TopicPartition, Long]] = loadOffsets(spark, kuduContext)
val kafkaDStream = storedOffsets match {
case None =>
LOGGER.info("storedOffsets was None")
kafkaParams += ("auto.offset.reset" -> "latest")
KafkaUtils.createDirectStream[String, Array[Byte]]
(ssc, PreferConsistent, ConsumerStrategies.Subscribe[String, Array[Byte]]
(topicsSet, kafkaParams)
)
case Some(fromOffsets) =>
LOGGER.info("storedOffsets was Some(" + fromOffsets + ")")
kafkaParams += ("auto.offset.reset" -> "none")
KafkaUtils.createDirectStream[String, Array[Byte]]
(ssc, PreferConsistent, ConsumerStrategies.Assign[String, Array[Byte]]
(fromOffsets.keys.toList, kafkaParams, fromOffsets)
)
}
, Kudu ( kuduContext), , : Zookeeper, HBase, HDFS, Hive, Impala .
, . , , —
.
, , 30 , 30 .
. , 40 , . 40 , , . , .
, , . Spark.
Spark , . , 10 , 10 , .

, , .
(, )
, Spark Streaming. , , . , (join) , .
RDD/DataFrame, RDD/DataFrame .
Kafka , . , Spark.
, Spark Streaming . .
, ( ), , . , :
dstream.repartition(100)
, . , , , - , 10 , . .