In the final article about DBT, I want to share a translation of the case by Stefano Solimito, in which he talked about his experience of using this tool at The Telegraph.
My previous articles on DBT:
-
Data modeling: why you need it and how to implement it
What is dbt and why do you need marketing analytics
The Telegraph is a 164-year-old company in which data has always played a central role. With the advent of the cloud and the need to process a huge amount of data in 2015, we started building our platform based on Google Cloud and have continued to improve it over the years.
A task
Over the past 4 years, I have had several discussions about how to organize data transformation or, more broadly, extraction, transformation, and loading (ETL) processes. The number of tools on the market is huge, and choosing the wrong technology can negatively affect the quality of the data and decisions based on it.
The Telegraph's data lake is powered by Cloud Storage and BigQuery . According to Google, Dataflow ( Apache Beam ) should be the natural choice for performing ETL in this case . This may be true for most companies. But if you go beyond the general use cases provided in Help and run into real-world problems, the choice may not be so easy.
In our case, the implementation of Apache Beam turned out to be not the easiest solution for the following reasons:
Java SDK , Python SDK. Python, Java — . , data scientists Python, , .
, , BigQuery. , Apache Beam ETL.
Dataflow Google, 2015 , AWS, ..
, , SQL, , SQL Java Python.
: - Apache Beam, .
Google Cloud Platform (GCP), , , Dataproc. Spark Hadoop GCP, . Hadoop, .
, - — Talend ( ). , , , :
.
CI/CD, .
, , . , .
Talend, .
ETL , , .
Python ETL , Google AWS, . . , , , . -, .
2019 DBT Python Apache Beam .
DBT
DBT (Data Building Tool) — , , .
DBT T () ETL-, (E) (L). . DBT 280 , The Telegraph .

DBT — , SQL-, .
, :
Postgres
Redshift
BigQuery
Snowflake
Presto
DBT pip ( Python). : (CLI) (UI). DBT Python , .
CLI : , , ..
UI .

, DBT . , . , , .
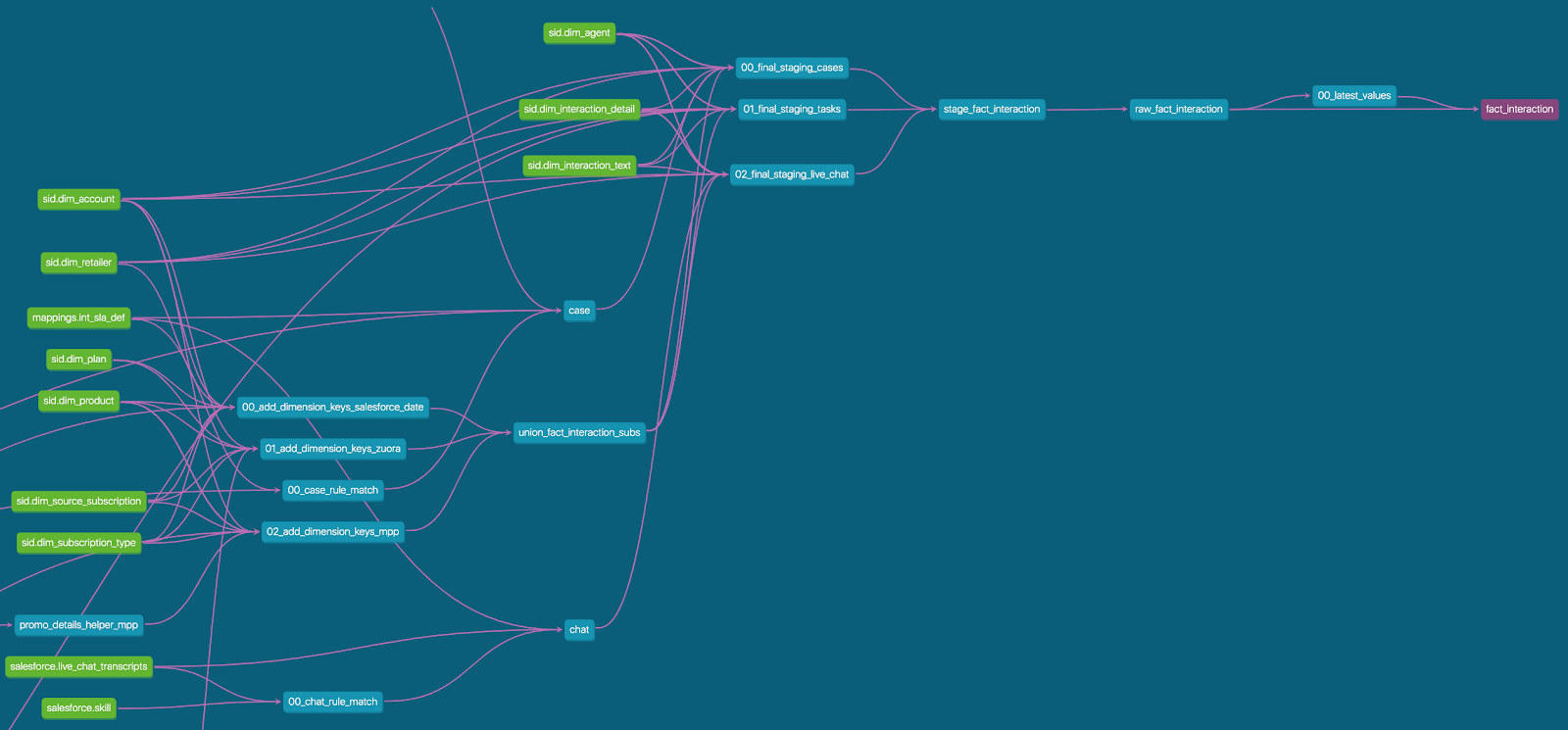
DBT : «dbt init» . , data- .
DBT . , (dbt_project.yml), .
DBT . — , , . (DW). Jinja2, :
.
SQL , .
, .
, BigQuery Standard SQL.
Jinja , , . Jinja , , .

DBT . , , , . , , , , , .
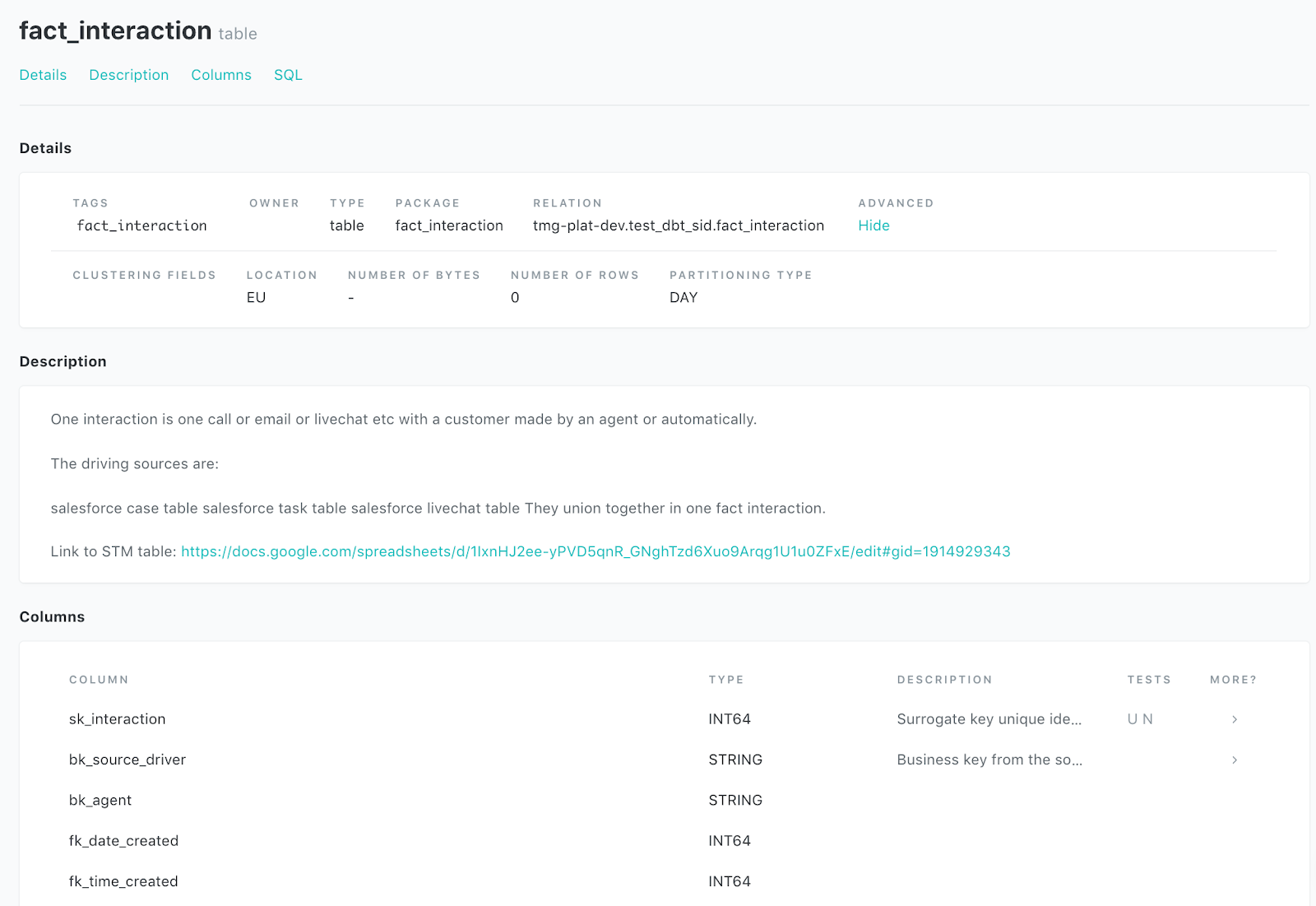
data-driven , , . DBT , .
YAML, , .
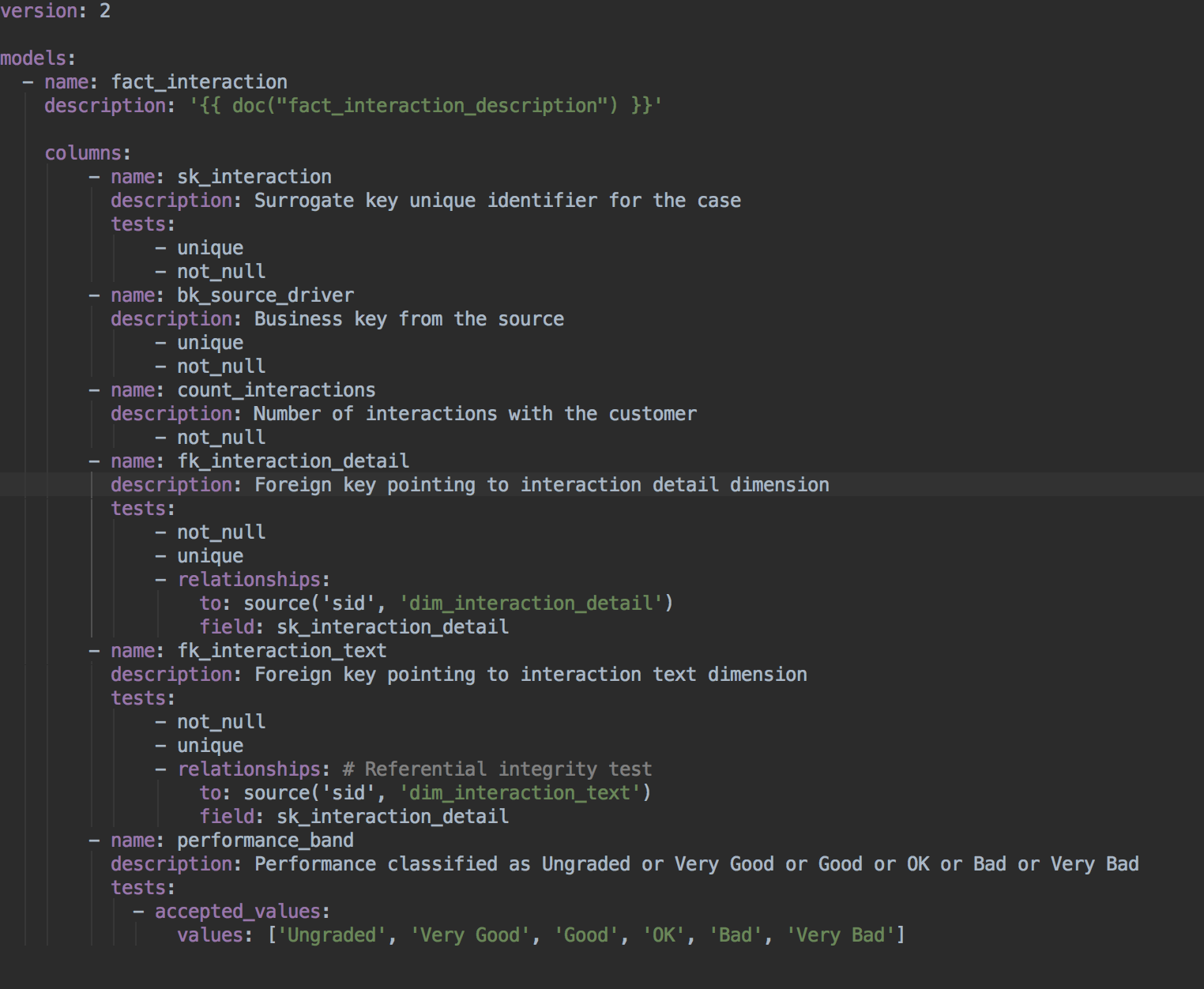
:
sk_interaction, bk_source_driver .
count_interactions
fk_interaction_detail , , fk_interaction_detail sk_interaction_detail. , .
fk_interaction_text .
Performance_band .
SQL.
, «bk_source_driver» «fact_interaction» 5% , NULL.
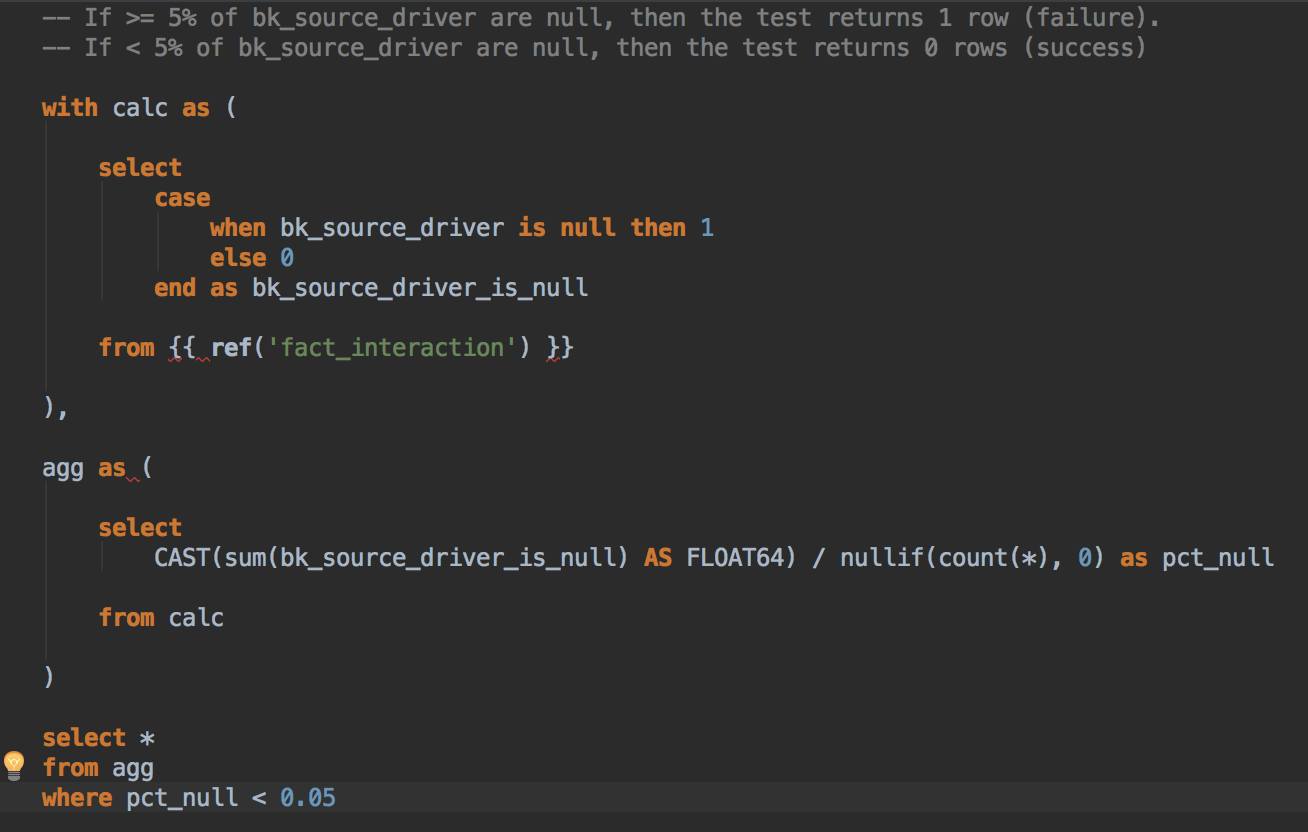
DBT . YAML , DBT.
, Sharded BigQuery Tables. . «execution_date» DBT , .

DBT (), , , SQL .
«execution_date» , .
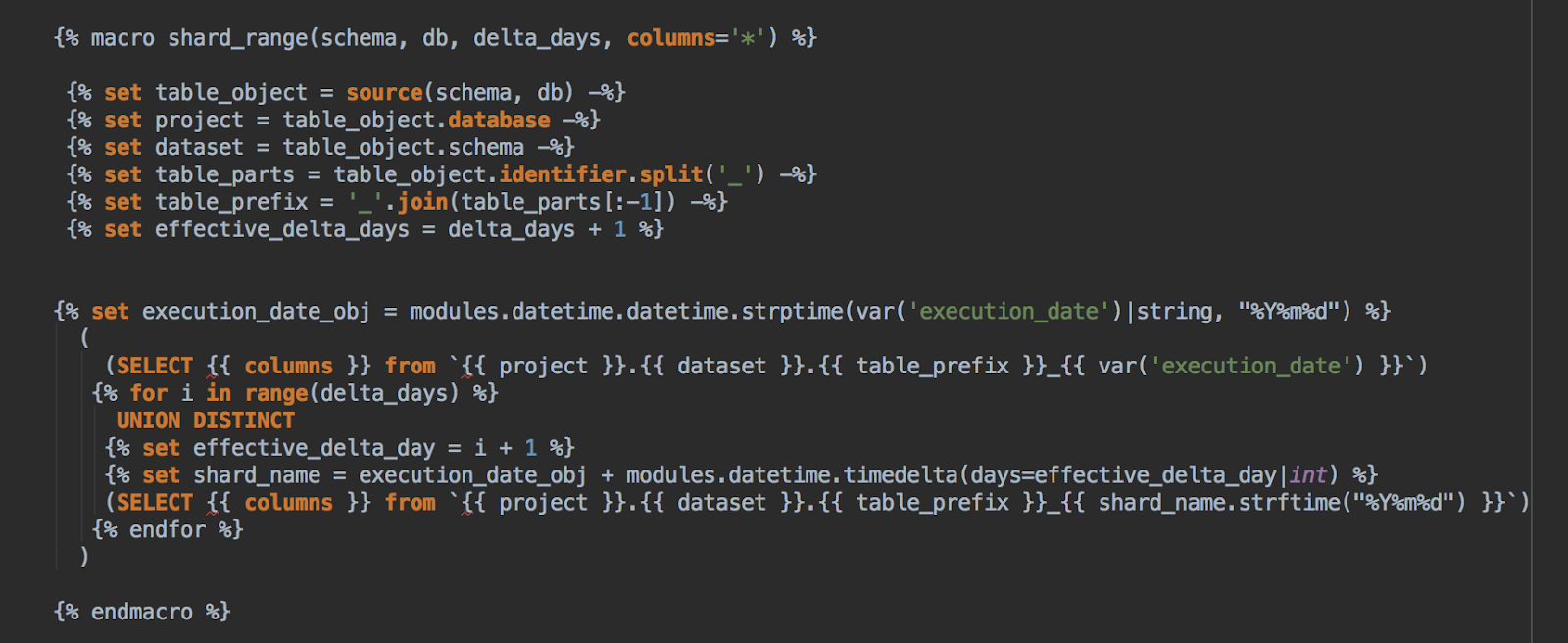
Telegraph DBT ( ) . , . , .
:
, .
.
DBT .
. SQL Python, , DBT.
DBT. .
. , BigQuery Snowflake.
- DBT .
( , , ) .
. , .
, .
:
SQL: .
. , DBT. UI, , , .
It takes a long time to create documentation for BigQuery due to a poor implementation that scans all the segments in the dataset.
DBT only covers T in ETL, so you need other tools to perform data extraction and loading into the warehouse.