
A great feature was recently added to the mainline of the Clang compiler . Using the
[[clang::musttail]]
or attributes,
__attribute__((musttail))
you can now get guaranteed tail calls in C, C ++, and Objective-C.
int g(int);
int f(int x) {
__attribute__((musttail)) return g(x);
}
( Online compiler )
Usually these calls are associated with functional programming, but I'm only interested in them from a performance point of view. In some cases, with their help, you can get better code from the compiler - at least with the available compilation technologies - without resorting to an assembler.
The use of this approach in parsing the serialization protocol gave amazing results: we were able to parse at speeds in excess of 2 Gb / s. , more than twice as fast as the previous best solution. This speedup will be useful in many situations, so it would be incorrect to limit itself to just the statement "tail calls == double speedup". However, these challenges are the key element that made these speed gains possible.
I will tell you what the advantages of tail calls are, how we parse the protocol using them, and how we can extend this technique to interpreters. I think that thanks to it, interpreters of all major languages written in C (Python, Ruby, PHP, Lua, etc.) can get significant performance gains. The main drawback is related to portability: today it
musttail
is a non-standard compiler extension. While I hope it will catch on, it will take some time before the extension spreads wide enough for the C compiler on your system to support it. When building, you can sacrifice efficiency in exchange for portability if it turns out to be
musttail
unavailable.
Tail Call Basics
A tail call is a call to any function in the tail position, the last action before the function returns a result. When optimizing tail calls, the compiler compiles the instruction for the tail call
jmp
, not
call
. This does not perform overhead actions that would normally allow the callee to
g()
return to the caller
f()
, such as creating a new stack frame or passing a return address. Instead, it
f()
refers directly to
g()
it as if it were part of itself, and
g()
returns the result directly to the caller
f()
. This optimization is safe because the stack frame
f()
is no longer needed after the start of the tail call, because it became impossible to access any local variable
f()
.
Even if it looks trivial, this optimization has two important features that open up new possibilities for writing algorithms. First, by executing n consecutive tail calls, the memory stack is reduced from O (n) to O (1). This is important because the stack is limited and overflow can crash the program. So, without this optimization, some algorithms are dangerous. Secondly, it
jmp
eliminates the overhead of
call
and as a result the function call becomes as efficient as any other branch. Both of these features allow tail calls to be used as an efficient alternative to conventional iterative control structures like
for
and
while
.
This idea is not new at all and dates back to 1977, when Guy Steele wrote a whole paper in which he argued that procedure calls are cleaner than architectures
GOTO
, while optimizing tail calls does not lose speed. It was one of the "Lambda Works" written between 1975 and 1980, which formulated many of the ideas behind Lisp and Scheme.
Tail call optimization is nothing new, even for Clang. He could optimize them before, like GCC and many other compilers. In fact, the attribute
musttail
in this example does not change the output of the compiler at all: Clang has already optimized tail calls for
-O2
.
New here is a guarantee . While compilers are often successful in optimizing tail calls, this is the “best possible” thing and you cannot rely on it. In particular, the optimization will surely not work in unoptimized builds: the online compiler . In this example, the tail call is compiled into
call
, so we are back on a stack of O (n) size. This is why we need
musttail
: Until we have a guarantee from the compiler that our tail calls will always be optimized in all assembly modes, it will be unsafe to write algorithms with such calls for iteration. And sticking to code that only works with optimizations enabled is a pretty tough constraint.
The problem with interpreter loops
Compilers are incredible technology, but they are not perfect. Mike Pall, the author of LuaJIT, decided to write the LuaJIT 2.x interpreter in assembly language, not C, and he called this the main factor that made the interpreter so fast . Paul later explained in more detail why C compilers have a hard time finding the main interpreter loops . Two main points:
- , .
- , .
These observations reflect well our experience in optimizing the parsing of the serialization protocol. And tail calls will help us to solve both problems.
You might find it odd to compare interpreter loops to serialization protocol parsers. However, their unexpected similarity is determined by the nature of the wire-format of the protocol: it is a set of key-value pairs in which the key contains the field number and its type. The key works like an opcode in the interpreter: it tells us what operation needs to be performed to parse this field. The field numbers in the protocol can go in any order, so you need to be ready at any time to jump to any part of the code.
It would be logical to write such a parser using a loop
while
with a nested expression
switch
... This has been the best approach for parsing a serialization protocol over the lifetime of the protocol. For example, here is the parsing code from the current C ++ version . If we represent the control flow graphically, we get the following scheme:
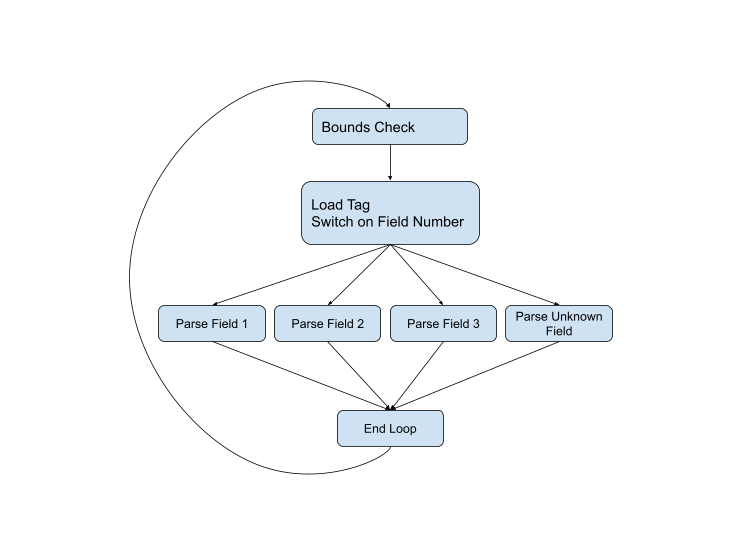
But the diagram is not complete, because problems can arise at almost every stage. The field type might be wrong, or the data might be corrupted, or we might just jump to the end of the current buffer. The complete diagram looks like this:
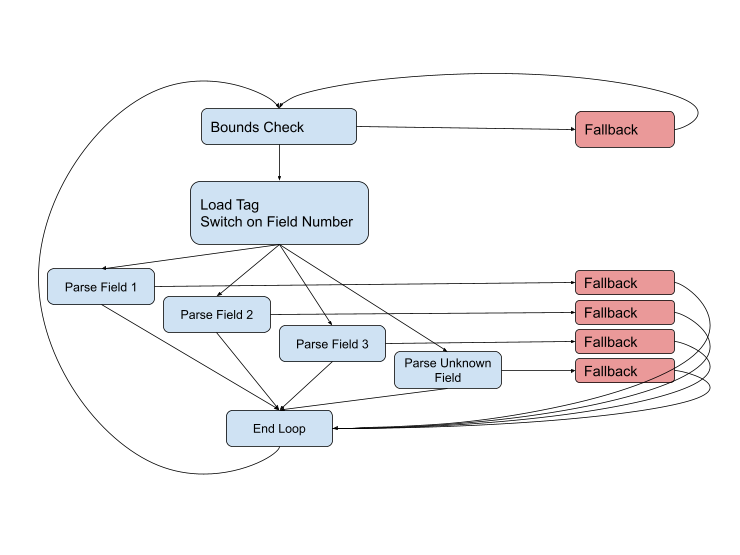
We need to stay on the fast paths (blue) as long as possible, but when faced with a difficult situation, we will have to handle it using the fallback code. Such paths are usually longer and more complex than fast paths, they involve more data and often use awkward calls to other functions to handle even more complex cases.
In theory, if you combine this schema with the profile, the compiler will get all the information it needs to generate the most optimal code. But in practice, with this size of function and the number of connections, we often have to struggle with the compiler. It throws out an important variable that we want to store in the register. It applies the manipulation of the stack frame that we want to wrap around the call to the fallback function. It concatenates identical code paths that we want to keep separate for branch prediction. It all looks like trying to play the piano with mittens.
Improving interpreter loops with tail calls
The reasoning described above is largely a rephrasing of Paul's observations about the main cycles of the interpreter . But instead of throwing ourselves into assembler, we found that tailored architecture can give us the control we need to get near-optimal code out of C. I worked on this with my colleague Gerben Stavenga, who came up with most of the architecture. Our approach is similar to the wasm3 WebAssembly interpreter , which calls this pattern "metamachine" .
We put the code for our 2- gigabit parser in upb, a small protobuf library in C. It is fully working and passes all tests for compliance with the serialization protocol, but has not yet been deployed anywhere, and the architecture has not been implemented in the C ++ version of the protocol. But when the extension came to Clang
musttail
(and upb was updated to use it ), one of the main barriers to the full implementation of our fast parser dropped.
We have moved away from one big parsing function and apply its own small function for each operation. Each tail function calls the next operation in the sequence. For example, here is a function for parsing a single field of a fixed size (the code is simplified compared to upb, I have removed many small details of the architecture).
The code
#include <stdint.h>
#include <stddef.h>
#include <string.h>
typedef void *upb_msg;
struct upb_decstate;
typedef struct upb_decstate upb_decstate;
// The standard set of arguments passed to each parsing function.
// Thanks to x86-64 calling conventions, these will be passed in registers.
#define UPB_PARSE_PARAMS \
upb_decstate *d, const char *ptr, upb_msg *msg, intptr_t table, \
uint64_t hasbits, uint64_t data
#define UPB_PARSE_ARGS d, ptr, msg, table, hasbits, data
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
const char *fallback(UPB_PARSE_PARAMS);
const char *dispatch(UPB_PARSE_PARAMS);
// Code to parse a 4-byte fixed field that uses a 1-byte tag (field 1-15).
const char *upb_pf32_1bt(UPB_PARSE_PARAMS) {
// Decode "data", which contains information about this field.
uint8_t hasbit_index = data >> 24;
size_t ofs = data >> 48;
if (UNLIKELY(data & 0xff)) {
// Wire type mismatch (the dispatch function xor's the expected wire type
// with the actual wire type, so data & 0xff == 0 indicates a match).
MUSTTAIL return fallback(UPB_PARSE_ARGS);
}
ptr += 1; // Advance past tag.
// Store data to message.
hasbits |= 1ull << hasbit_index;
memcpy((char*)msg + ofs, ptr, 4);
ptr += 4; // Advance past data.
// Call dispatch function, which will read the next tag and branch to the
// correct field parser function.
MUSTTAIL return dispatch(UPB_PARSE_ARGS);
}
For such a small and simple function, Clang generates code that is almost impossible to beat:
upb_pf32_1bt: # @upb_pf32_1bt
mov rax, r9
shr rax, 24
bts r8, rax
test r9b, r9b
jne .LBB0_1
mov r10, r9
shr r10, 48
mov eax, dword ptr [rsi + 1]
mov dword ptr [rdx + r10], eax
add rsi, 5
jmp dispatch # TAILCALL
.LBB0_1:
jmp fallback # TAILCALL
Note that there is no prologue or epilogue, no register preemption, no stack usage at all. The only exits are
jmp
from two tail calls, but no code is needed to pass parameters, because the arguments are already in the correct registers. Perhaps the only possible improvement we see here is a conditional jump for a tail call
jne fallback
instead of
jne
a subsequent call
jmp
.
If you saw a disassembly of this code without symbolic information, you would not realize that this was the entire function. It could equally well be the base unit of a larger function. And that's exactly what we do: we take the interpreter loop, which is a large and complex function, and program it block by block, passing control flow between them through tail calls. We have complete control over the distribution of registers on the boundary of each block (at least six registers), and since the function is simple enough and does not preempt registers, we have achieved our goal of storing the most important state along all the fast paths.
We can independently optimize each sequence of instructions. And the compiler will handle all sequences independently too, because they are located in separate functions (if necessary, you can prevent inlining with
noinline
). This is how we solve the problem described above, in which the code from the fallback paths degrades the quality of the code of the fast paths. By placing the slow paths in completely separate functions, the speed stability of the fast paths can be guaranteed. The beautiful assembler remains unchanged, it is not affected by any changes in other parts of the parser.
If we apply this pattern to Paul's example from LuaJIT , then we can roughly correlate his handwritten assembler with small degradations in code quality :
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
return fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
The resulting assembler:
ADDVN: # @ADDVN
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
movzx eax, dl
movsd xmm0, qword ptr [r8 + 8*rax] # xmm0 = mem[0],zero
mov eax, edi
addsd xmm0, qword ptr [r9 + 8*rax]
movsd qword ptr [r9 + 8*rax], xmm0
mov edx, dword ptr [rcx]
add rcx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [rsi + 8*rax]
jmp rax # TAILCALL
.LBB0_1:
jmp fallback
I see only one improvement opportunity here besides the above
jne fallback
: for some reason the compiler doesn't want to generate
jmp qword ptr [rsi + 8*rax]
, instead it loads into
rax
and then executes
jmp rax
. These are minor coding issues that I hope Clang will fix soon without too much difficulty.
Limitations
One of the main drawbacks of this approach is that all of these beautiful assembly language sequences are catastrophically pessimized in the absence of tail calls. Any non-tailored call will create a stack frame and push a lot of data onto the stack.
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
// When we leave off "return", things get real bad.
fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
Suddenly we get this
ADDVN: # @ADDVN
push rbp
push r15
push r14
push r13
push r12
push rbx
push rax
mov r15, r9
mov r14, r8
mov rbx, rcx
mov r12, rsi
mov ebp, edi
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
.LBB0_2:
movzx eax, dl
movsd xmm0, qword ptr [r14 + 8*rax] # xmm0 = mem[0],zero
mov eax, ebp
addsd xmm0, qword ptr [r15 + 8*rax]
movsd qword ptr [r15 + 8*rax], xmm0
mov edx, dword ptr [rbx]
add rbx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [r12 + 8*rax]
mov rsi, r12
mov rcx, rbx
mov r8, r14
mov r9, r15
add rsp, 8
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
jmp rax # TAILCALL
.LBB0_1:
mov edi, ebp
mov rsi, r12
mov r13d, edx
mov rcx, rbx
mov r8, r14
mov r9, r15
call fallback
mov edx, r13d
jmp .LBB0_2
To avoid this, we tried to call other functions only through inlining or tail calls. This can be tedious if the operation has many places in which an unusual situation may occur that is not an error. For example, when we parse the serialization protocol, integer variables are often one byte long, but longer ones are not an error. Inlining the handling of such situations can degrade the quality of the fast path if the fallback code is too complex. But the tail call of the fallback function does not make it easy to return to the operation when handling an abnormality, so the fallback function must be able to complete the operation. This leads to duplication and complication of the code.
Ideally this problem can be solved by adding __attribute __ ((preserve_most))in a fallback function followed by a normal call, not a tail call. The attribute
preserve_most
makes the callee responsible for preserving almost all registers. This allows you to delegate the task of preempting registers to fallback functions, if necessary. We experimented with this attribute, but ran into mysterious issues that we couldn't solve. Perhaps we made a mistake somewhere, we will return to this in the future.
The main limitation is that
musttail
it is not portable. I really hope that the attribute will take root, it will be implemented in GCC, Visual C ++ and other compilers, and one day it will even be standardized. But this will not happen soon, but what should we do now?
When the expansion
musttail
is not available, you need to execute at least one correct one
return
without a tail call for each theoretical iteration of the loop . We have not yet implemented such a fallback in the upb library, but I think that it will turn into a macro that, depending on availability,
musttail
will either make tail calls or simply return.