 Hello, Habitants! How to squeeze everything out of your data? How to make data-driven decisions? How to organize data science within the company? Who to Hire as an Analyst? How to bring machine learning and artificial intelligence projects to the top level? Roman Zykov knows the answer to these and many other questions, because he has been analyzing data for almost twenty years. Roman's track record includes creating his own company from scratch with offices in Europe and South America, which has become a leader in the use of artificial intelligence (AI) in the Russian market. In addition, the author of the book created analytics at Ozon.ru from scratch. This book is intended for the thinking reader who wants to try their hand at data analysis and create services based on it. It will be useful to you if you are a manager,who wants to set goals and manage analytics. If you are an investor, it will make it easier for you to understand the potential of a startup. Those who "saw" their startup will find here recommendations on how to choose the right technology and recruit a team. And the book will help beginners broaden their horizons and begin to apply practices that they have not thought about before, and this will set them apart from professionals in such a difficult and volatile field.
Hello, Habitants! How to squeeze everything out of your data? How to make data-driven decisions? How to organize data science within the company? Who to Hire as an Analyst? How to bring machine learning and artificial intelligence projects to the top level? Roman Zykov knows the answer to these and many other questions, because he has been analyzing data for almost twenty years. Roman's track record includes creating his own company from scratch with offices in Europe and South America, which has become a leader in the use of artificial intelligence (AI) in the Russian market. In addition, the author of the book created analytics at Ozon.ru from scratch. This book is intended for the thinking reader who wants to try their hand at data analysis and create services based on it. It will be useful to you if you are a manager,who wants to set goals and manage analytics. If you are an investor, it will make it easier for you to understand the potential of a startup. Those who "saw" their startup will find here recommendations on how to choose the right technology and recruit a team. And the book will help beginners broaden their horizons and begin to apply practices that they have not thought about before, and this will set them apart from professionals in such a difficult and volatile field.
Do I need to be able to program?
Yes need. In the 21st century, it is desirable for every person to understand how to use programming in their work. Previously, programming was available only to a narrow circle of engineers. Over time, applied programming has become more accessible, democratic and convenient.
I learned to program on my own as a child. My father bought a computer "Partner 01.01" in the late 1980s, when I was about eleven years old, and I began to immerse myself in programming. First, I mastered the BASIC language, then I got to the assembler. I studied everything from books - then there was no one to ask. The groundwork that was made in childhood was very useful to me in life. At that time, my main instrument was a blinking white cursor on a black screen, programs had to be recorded on a tape recorder - all this cannot be compared with the possibilities that we have now. The basics of programming are not so difficult to learn. When my daughter was five and a half years old, I put her in a simple Scratch programming course. With my little tips, she took this course and even got her entry-level MIT certification.
Application programming is what allows you to automate part of an employee's functions. The first candidates for automation are repetitive actions.
There are two ways in analytics. The first is to use ready-made tools (Excel, Tableau, SAS, SPSS, etc.), where all actions are performed with the mouse, and the maximum programming is to write a formula. The second is to write in Python, R, or SQL. These are two fundamentally different approaches, but a good person should be proficient in both. When working with any task, you need to find a balance between speed and quality. This is especially true for searching for insights. I have met both ardent adherents of programming and stubborn ones who could only use a mouse and at most one program. A good specialist will select his own tool for each task. In some case, he will write a program, in another he will do everything in Excel. And in the third, it will combine both approaches: it will upload data to SQL, process the dataset in Python, and analyze it in an Excel or Google Docs pivot table.The speed of work of such an advanced specialist can be an order of magnitude higher than that of a one-liner. Knowledge gives freedom.
While still a student, I was fluent in several programming languages and even managed to work for a year and a half as a software developer. Times were difficult then - I entered the Moscow Institute of Physics and Technology in June 1998, and in August there was a default. It was impossible to live on a scholarship, I did not want to take money from my parents. In my second year, I was lucky, I was hired as a developer in one of the companies at MIPT - there I deepened my knowledge of assembler and C. After some time, I got a job in the technical support of StatSoft Russia - here I improved my statistical analysis. At Ozon.ru he completed training and received a SAS certificate, and also wrote a lot in SQL. The programming experience helped me a lot - I was not afraid of something new, I just took it and did it. If I did not have such programming experience, there would not be many interesting things in my life, including the Retail Rocket company,which we founded with my partners.
Dataset
A dataset is a set of data, most often in the form of a table, that has been unloaded from storage (for example, via SQL) or obtained in another way. A table is made up of columns and rows, commonly referred to as records. In machine learning, the columns themselves are independent variables, or predictors, or more commonly features, and dependent variables, outcome. You will find this division in the literature. The task of machine learning is to train a model that, using the independent variables (features), will be able to correctly predict the value of the dependent variable (as a rule, there is only one in the dataset).
The main two kinds of variables are categorical and quantitative. A categorical variable contains the text or numeric encoding of "categories". In turn, it can be:
- Binary - can take only two values (examples: yes / no, 0/1).
- Nominal - can take more than two values (example: yes / no / don't know).
- Ordinal - when the order matters (for example, the rank of the athlete, the line number in the search results).
A quantitative variable can be:
- Discrete (discrete) - the value is calculated by the account, for example, the number of people in the room.
- Continuous - any value from the interval, for example, box weight, product price.
Let's look at an example. There is a table with apartment prices (dependent variable), one row (record) for an apartment, each apartment has a set of attributes (independent) with the following columns:
- The price of the apartment is continuous and dependent.
- The area of the apartment is continuous.
- The number of rooms is discrete (1, 2, 3, ...).
- The bathroom is combined (yes / no) - binary.
- Floor number - ordinal or nominal (depending on the task).
- Distance to the center is continuous.
Descriptive statistics
The very first step after unloading data from the warehouse is to do exploratory data analysis, which includes descriptive statistics and data visualization, possibly clearing the data by removing outliers.
Descriptive statistics usually include different statistics for each of the variables in the input dataset:
- The number of non-missing values.
- The number of unique values.
- Minimum / maximum.
- Mean.
- Median.
- Standard deviation.
- Percentiles - 25%, 50% (median), 75%, 95%.
Not all types of variables can be calculated - for example, the average can only be calculated for quantitative variables. Statistical packages and statistical analysis libraries already have out-of-the-box functions that count descriptive statistics. For example, the pandas Python library has a describe function that will immediately display several statistics for one or all of the variables in the dataset:
s = pd.Series([4-1, 2, 3])
s.describe()
count 3.0
mean 2.0
std 1.0
min 1.0
25% 1.5
50% 2.0
75% 2.5
max 3.0
While this book is not intended to be a textbook on statistics, I will give you some helpful hints. Often, in theory, it is assumed that we are working with normally distributed data, the histogram of which looks like a bell (Figure 4.1).
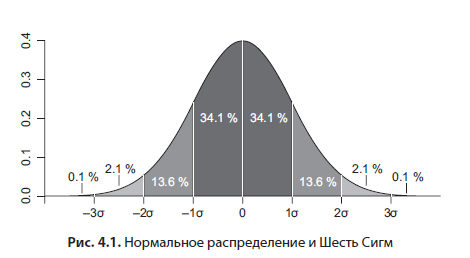
I highly recommend checking this assumption at least by eye. The median is the value that halves the sample. For example, if the 25th and 75th percentiles are at different distances from the median, this already indicates a shifted distribution. Another factor is the strong difference between mean and median; in a normal distribution, they practically coincide. You will often deal with an exponential distribution when analyzing customer behavior - for example, in Ozon.ru, the time between successive customer orders will have an exponential distribution. The mean and median for it differ significantly. Therefore, the correct number is the median, the value that halves the sample. In the example with Ozon.ru, this is the time during which 50% of users make the next order after the first one. The median is also more robust to outliers in the data.If you want to work with averages, for example, due to the limitations of the statistical package, and technically the average is calculated faster than the median, then in the case of an exponential distribution, you can process it with the natural logarithm. To return to the original data scale, you need to process the resulting average with the usual exponent.
Percentile is a value that a given random variable does not exceed with a fixed probability. For example, the phrase "the 25th percentile of the price of goods is equal to 150 rubles" means that 25% of goods have a price less than or equal to 150 rubles, the remaining 75% of goods are more expensive than 150 rubles.
For a normal distribution, if the mean and standard deviation are known, there are useful theoretically derived patterns - 95% of all values fall into the interval at a distance of two standard deviations from the mean in both directions, that is, the width of the interval is four sigma. You may have heard a term such as Six Sigma (Figure 4.1) - this figure characterizes production without scrap. So, this empirical law follows from the normal distribution: in the interval of six standard deviations around the mean (three in each direction), 99.99966% of the values fit - ideal quality. Percentiles are very useful for finding and removing outliers from data. For example, when analyzing experimental data, you can assume that all data outside the 99th percentile are outliers and delete them.
Charts
A good graph is worth a thousand words. The main types of charts that I use:
- histograms;
- scatter chart;
- time series chart with a trend line;
- box plot, box and whiskers plot.
The histogram (Figure 4.2) is the most useful analysis tool. It allows you to visualize the frequency distribution of the occurrence of a value (for a categorical variable) or to split a continuous variable into ranges (bins). The second is used more often, and if you additionally provide descriptive statistics to such a graph, then you will have a complete picture describing the variable you are interested in. The histogram is a simple and intuitive tool.
A scatterplot (Figure 4.3) allows you to see how two variables depend on each other. It is constructed simply: on the horizontal axis - the scale of the independent variable, on the vertical axis - the scale of the dependent. Values (records) are marked as dots. A trend line can also be added. In advanced statistics packages, you can interactively flag outliers.
Time series plots (Figure 4.4) are much the same as a scatter plot, in which the independent variable (on the horizontal axis) is time. Usually, two components can be distinguished from a time series - cyclical and trend. A trend can be built knowing the length of the cycle, for example, a seven-day one is a standard sales cycle in grocery stores, you can see a repeating picture on the chart every 7 days. Next, a moving average with a window length equal to the cycle is superimposed on the chart - and you get a trend line. Almost all statistical packages, Excel, Google Sheets can do this. If you need to get the cyclical component, this is done by subtracting the trend line from the time series. Based on such simple calculations, the simplest algorithms for forecasting time series are built.
The box plot (Fig. 4.5) is very interesting; to some extent, it duplicates the histograms, since it also shows an estimate of the distribution.
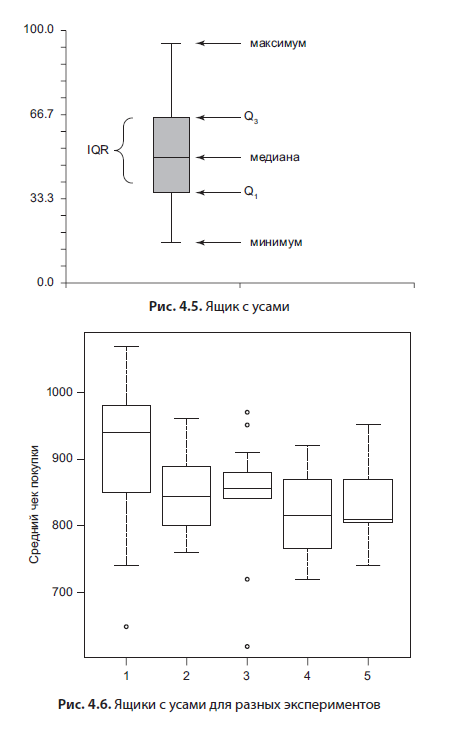
It consists of several elements: a mustache, which denote the minimum and maximum, a box, the upper edge of which is the 75th percentile, the lower edge is the 25th percentile. In the box, the line is the median, the value "in the middle", which divides the sample in half. This type of graph is useful for comparing experimental results or variables with each other. An example of such a graph is below (Fig. 4.6). I think this is the best way to visualize the results of hypothesis testing.
General approach to data visualization
Data visualization is needed for two things: to explore the data and to explain the findings to the customer. Often, several methods are used to present the results: a simple comment with a couple of numbers, Excel or another spreadsheet format, a presentation with slides. All three of these methods combine conclusion and proof - that is, an explanation of how this conclusion was reached. It is convenient to express the proof in graphs. In 90% of cases, those charts of the types described above are sufficient for this.
Exploratory charts and presentation charts are different from each other. The purpose of research is to find a pattern or cause, as a rule, there are many of them, and it happens that they are built at random. The purpose of the presentation graphs is to guide the decision maker (decision maker) to the conclusions in the problem. Everything is important here - both the title of the slide and their simple sequence that leads to the desired conclusion. An important criterion for the proof of inference scheme is how quickly the customer will understand and agree with you. It doesn't have to be a presentation. Personally, I prefer simple text - a couple of sentences with conclusions, a couple of graphs and a few numbers proving these conclusions, nothing more.
Gene Zelazny, director of visual communications at McKinsey & Company, states in his book Speak the Language of Diagrams:
“It is not the data (dollars or interest) or the parameters (profit, profitability, or salary) that determine the type of chart. and your idea is what you want to put into the diagram. "
I recommend that you pay attention to graphs in presentations and articles - do they prove the author's conclusions? Do you like everything about them? Could they be more convincing?
And here is what Jean Zelazny writes about slides in presentations:
"The widespread use of computer technology has led to the fact that now, in minutes, you can do something that used to require hours of painstaking work - and the slides are baked like pies ... insipid and tasteless."
I did quite a lot of reports: with and without slides, short, for 5-10 minutes, and long - for an hour. I can assure you that it is much more difficult for me to make a convincing text for a short presentation without slides than a PowerPoint presentation. Look at the politicians who are speaking: their task is to convince, how many of them show slides in their speeches? The word is more convincing, the slides are just visual material. And it takes more work to make your word clear and convincing than throwing slides. I found myself thinking about how the presentation looks when composing the slides. And when writing an oral report - how convincing are my arguments, how to work with intonation, how clear my thought is. Please considerdo you really need a presentation? Do you want to turn a meeting into boring slides instead of making decisions?
“Meetings should focus on short, written reports on paper, rather than abstracts or scraps of lists projected onto the wall,” says Edward Tufty, a prominent data visualization school spokesperson, in PowerPoint Cognitive Style.
Paired data analysis
I learned about pair programming from the developers [30] Retail Rocket. It is a programming technique in which the source code is created by pairs of people programming the same task and sitting at the same workstation. One programmer sits at the keyboard, the other works with his head, is focused on the big picture and continually looks at the code produced by the first programmer. From time to time they can change places.
And we managed to adapt it for the needs of analytics! Analytics, like programming, is a creative process. Imagine you need to build a wall. You have one worker. If you add one more, the speed will approximately double. In the creative process, this will not work. The speed of project creation will not double. Yes, you can decompose a project, but I am now discussing a task that cannot be decomposed, and it should be done by one person. The paired approach allows you to speed up this process many times over. One person is at the keyboard, the second is sitting next to him. Two heads are working on the same problem. When I solve difficult problems, I talk to myself. When two heads talk to each other, they look for a better reason. We use the paired work scheme for the following tasks.
- When it is necessary to transfer the knowledge of one project from one employee to another, for example, a newcomer was hired. The “head” will be an employee who transfers knowledge, “hands” at the keyboard - to whom it is transferred.
- When the problem is complex and incomprehensible. Then two experienced employees in a pair will solve it much more efficiently than one. It will be more difficult to make the analysis task one-sided.
Usually, during planning, we transfer a task to the category of paired ones, if it is clear that it fits the criteria of such.
The advantages of the pair approach are that time is used much more efficiently, both people are very focused, they discipline each other. Complex tasks are solved more creatively and an order of magnitude faster. Minus - it is impossible to work in this mode for more than a few hours, you get very tired.
Technical debt
Another important thing I learned from Retail Rocket engineers is dealing with technical debt. Technical debt is working with old projects, optimizing the speed of work, switching to new versions of libraries, removing old program code from hypothesis testing, engineering simplification of projects. All these tasks take a good third of the analytics development time. I will quote the technical director of Retail Rocket Andrey Chizh:
“I have not yet met any companies in my practice (and these are more than 10 companies in which I worked myself, and about the same number that I know well from the inside), except for ours, which had there would be tasks to remove the functionality, although, probably, such exist. "
I have not met either. I saw the "swamps" of software projects, where old stuff interferes with creating something new. The crux of tech debt is that everything you've done before needs to be serviced. It's like with a car maintenance - it needs to be done regularly, otherwise the car will break down at the most unexpected moment. Code that hasn't been changed or updated for a long time is bad code. Usually it already works on the principle of "works - do not touch". Four years ago, I spoke with a developer at Bing. He said that in the architecture of this search engine there is a compiled library, the code of which is lost. And nobody knows how to restore it. The longer it takes, the worse the consequences will be.
How Retail Rocket Analysts Serve Tech Debt:
- , . .
- - — , . , Spark , 1.0.0.
- - — .
- - — , , .
Dealing with technical debt is the road to quality. I was convinced of this by working on the Retail Rocket project. From an engineering point of view, the project is made as in the "best houses in California".
More details about the book can be found on the website of the publishing house
» Table of Contents
» Excerpt
For Habitants a 25% discount on coupon - Data Science
Upon payment for the paper version of the book, an e-book is sent to the e-mail.