Post # 4 for beginners is about data visualization techniques.
The importance of visualization
Simple visualization techniques, such as those shown earlier, allow you to convey a large amount of information concisely. They complement the summary statistics that we calculated earlier in this series of posts, and therefore it is very important to be able to use them. Statistics such as mean and standard deviation inevitably hide a lot of information because they collapse the sequence into a single number.
The English mathematician Francis Anscombe compiled a collection of four point plots, now known as the Anscombe quartet , that have nearly identical statistical properties (including mean, variance, and standard deviation). Despite this, they clearly show that the distribution of the values of the sequences and is highly divergent:

, . , 2013 .:
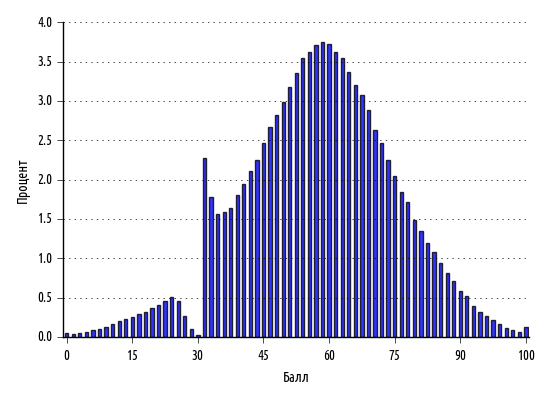
, — 30% — . , — - .
, , , . , , , . 30% , . , 5% .
, 1938 ., . , 50 : , 1, .
, , , , , , . , , , .
, , . sp.random.normal
scipy, . 0 1, , . 70150 7679.
. :
def ex_1_24():
'''
'''
emp = load_uk_scrubbed()['Electorate']
fitted = stats.norm.rvs(emp.mean(), emp.std(ddof=0), len(emp))
df = empirical_cdf(emp)
df2 = empirical_cdf(fitted)
ax = df.plot(0, 1, label='')
df2.plot(0, 1, label='', grid=True, ax=ax)
plt.xlabel('')
plt.ylabel('')
plt.legend(loc='best')
plt.show()
:
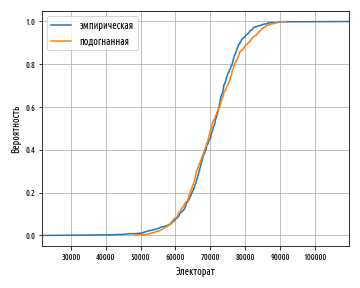
, . , .
, , :
def ex_1_25():
'''
'''
qqplot( load_uk_scrubbed()['Electorate'] )
plt.show()
, :

, . , , , .
, , , . Victors () , (Con) - (LD) , .
def ex_1_26():
''' ""
'''
df = load_uk_scrubbed()
df[''] = df['Con'] + df['LD']
freq = Counter(df['Con'].apply( lambda x: x > 0 ))
print(' "": %d, .. %d'
% (freq[True], freq[False]))
"": 631, .. 19
, 19 . , - : Con LD ( ), , ? Counter, :
'''
" " (Con)
"- " (LD)'''
df = load_uk_scrubbed()
Counter(df['Con'].apply(lambda x: x > 0)),
Counter(df['LD'].apply(lambda x: x > 0))
(Counter({False: 19, True: 631}), Counter({False: 19, True: 631}))
, , . isnull
, , , :
def ex_1_27():
''' ,
" " (Con)
"-" (LD) '''
df = load_uk_scrubbed()
rule = df['Con'].isnull() & df['LD'].isnull()
return df[rule][['Region', 'Electorate', 'Con', 'LD']]
|
Region |
Electorate |
Con |
LD |
12 |
Northern Ireland |
60204.0 |
NaN |
NaN |
13 |
Northern Ireland |
73338.0 |
NaN |
NaN |
14 |
Northern Ireland |
63054.0 |
NaN |
NaN |
… |
… |
… |
… |
… |
584 |
Northern Ireland |
64594.0 |
NaN |
NaN |
585 |
Northern Ireland |
74732.0 |
NaN |
NaN |
, . , . , ? . , - , - , . , , , — — , .
, , , , . , , :
def load_uk_victors():
''' ,
'''
df = load_uk_scrubbed()
rule = df['Con'].notnull()
df = df[rule][['Con', 'LD', 'Votes', 'Electorate']]
df[''] = df['Con'] + df['LD']
df[' '] = df[''] / df['Votes']
df[''] = df['Votes'] / df['Electorate']
return df
: Victors, Victors Share Turnout, .. , . , , :
def ex_1_28():
'''
'''
qqplot( load_uk_victors()[' '] )
plt.show()
:
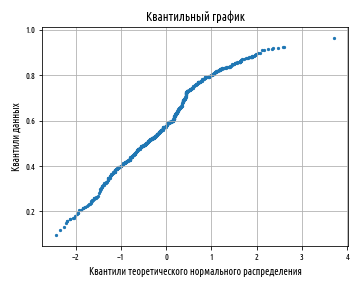
, , , , , « » . , , , .
Github. .
, 5, «Python, » .