Good afternoon, dear readers! The material is theoretical in nature and is addressed exclusively to novice analysts who first encountered BI analytics.
What is traditionally understood by this concept? In simple terms, this is a complex system (like, for example, budgeting) for collecting, processing and analyzing data, presenting the final results in the form of graphs, charts, tables.
This requires the well-coordinated work of several specialists at once. The data engineer is responsible for storage and ETL / ELT processes, the data analyst helps in filling the database, the BI analyst develops dashboards, the business analyst simplifies communication with the report customers. But this option is possible only if the company is ready to pay for the team's work. In most cases, small companies rely on one person to minimize costs, who often does not have a broad outlook in the field of BI at all, but has only a nodding acquaintance with the reporting platform.
In this case, the following happens: the collection, processing and analysis of data occurs by the forces of a single tool - the BI platform itself. In this case, the data is not preliminarily cleared in any way; The collection of information comes from primary sources without the participation of an intermediate storage. The results of this approach can be easily seen on thematic forums. If you try to summarize all the questions regarding BI tools, then the following will probably fall into the top 3: how to load poorly structured data into the system, how to calculate the required metrics from them, what to do if the report is running very slowly. Surprisingly, in these forums you will hardly find any discussion of ETL tools, data warehouse experiences, programming best practices, and SQL queries. Moreover, I have repeatedly come across the factthat experienced BI analysts did not speak very flatteringly about the use of R / Python / Scala, citing the fact that all problems can be solved only by means of the BI platform. At the same time, everyone understands that competent date engineering allows you to close a lot of problems when building BI reporting.
I propose to build the further conversation in the form of a parsing of simplified block diagrams. I will deliberately not name specific programs, but only indicate their class. Firstly, it is not of fundamental importance for the disclosure of the topic, and, secondly, the mention of tools immediately leads to unnecessary disputes in the comments.
"Data - BI" The easiest option. It is with him that prototyping of management panels begins. The data source is often a separate static file (csv, txt, xlsx, etc.).
. . , . , , . BI .
. (, 1). , . ( , , . .). BI-, . .
«Data – DB – BI» , , . , , .
. , . . SQL ( ), BI-. .
. , . . . SQL.
«Data – ETL – DB – BI» . ETL- , R/Python/Scala . . . .
. , . . BI-.
. ETL- SQL. . , .
. «» SQLite. , (). E-Commerce Data Kaggle.
#
import pandas as pd
#
pd.set_option('display.max_columns', 10)
pd.set_option('display.expand_frame_repr', False)
path_dataset = 'dataset/ecommerce_data.csv'
#
def func_main(path_dataset: str):
#
df = pd.read_csv(path_dataset, sep=',')
#
list_col = list(map(str.lower, df.columns))
df.columns = list_col
# -
df['invoicedate'] = df['invoicedate'].apply(lambda x: x.split(' ')[0])
df['invoicedate'] = pd.to_datetime(df['invoicedate'], format='%m/%d/%Y')
#
df['amount'] = df['quantity'] * df['unitprice']
#
df_result = df.drop(['invoiceno', 'quantity', 'unitprice', 'customerid'], axis=1)
#
df_result = df_result[['invoicedate', 'country', 'stockcode', 'description', 'amount']]
return df_result
#
def func_sale():
tbl = func_main(path_dataset)
df_sale = tbl.groupby(['invoicedate', 'country', 'stockcode'])['amount'].sum().reset_index()
return df_sale
#
def func_country():
tbl = func_main(path_dataset)
df_country = pd.DataFrame(sorted(pd.unique(tbl['country'])), columns=['country'])
return df_country
#
def func_product():
tbl = func_main(path_dataset)
df_product = tbl[['stockcode','description']].\
drop_duplicates(subset=['stockcode'], keep='first').reset_index(drop=True)
return df_product
Extract Transform. , . . , , .
#
import pandas as pd
import sqlite3 as sq
from etl1 import func_country,func_product,func_sale
con = sq.connect('sale.db')
cur = con.cursor()
##
# cur.executescript('''DROP TABLE IF EXISTS country;
# CREATE TABLE IF NOT EXISTS country (
# country_id INTEGER PRIMARY KEY AUTOINCREMENT,
# country TEXT NOT NULL UNIQUE);''')
# func_country().to_sql('country',con,index=False,if_exists='append')
##
# cur.executescript('''DROP TABLE IF EXISTS product;
# CREATE TABLE IF NOT EXISTS product (
# product_id INTEGER PRIMARY KEY AUTOINCREMENT,
# stockcode TEXT NOT NULL UNIQUE,
# description TEXT);''')
# func_product().to_sql('product',con,index=False,if_exists='append')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale;
# CREATE TABLE IF NOT EXISTS sale (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country_id INTEGER NOT NULL,
# product_id INTEGER NOT NULL,
# amount REAL NOT NULL,
# FOREIGN KEY(country_id) REFERENCES country(country_id),
# FOREIGN KEY(product_id) REFERENCES product(product_id));''')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale_data_lake;
# CREATE TABLE IF NOT EXISTS sale_data_lake (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country TEXT NOT NULL,
# stockcode TEXT NOT NULL,
# amount REAL NOT NULL);''')
# func_sale().to_sql('sale_data_lake',con,index=False,if_exists='append')
## (sale_data_lake) (sale)
# cur.executescript('''INSERT INTO sale (invoicedate, country_id, product_id, amount)
# SELECT sdl.invoicedate, c.country_id, pr.product_id, sdl.amount
# FROM sale_data_lake as sdl LEFT JOIN country as c ON sdl.country = c.country
# LEFT JOIN product as pr ON sdl.stockcode = pr.stockcode
# ''')
##
# cur.executescript('''DELETE FROM sale_data_lake''')
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
round(s.amount,1) as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
print(select(sql))
cur.close()
con.close()
(Load) . . . , . .
SQL, . , BI-.
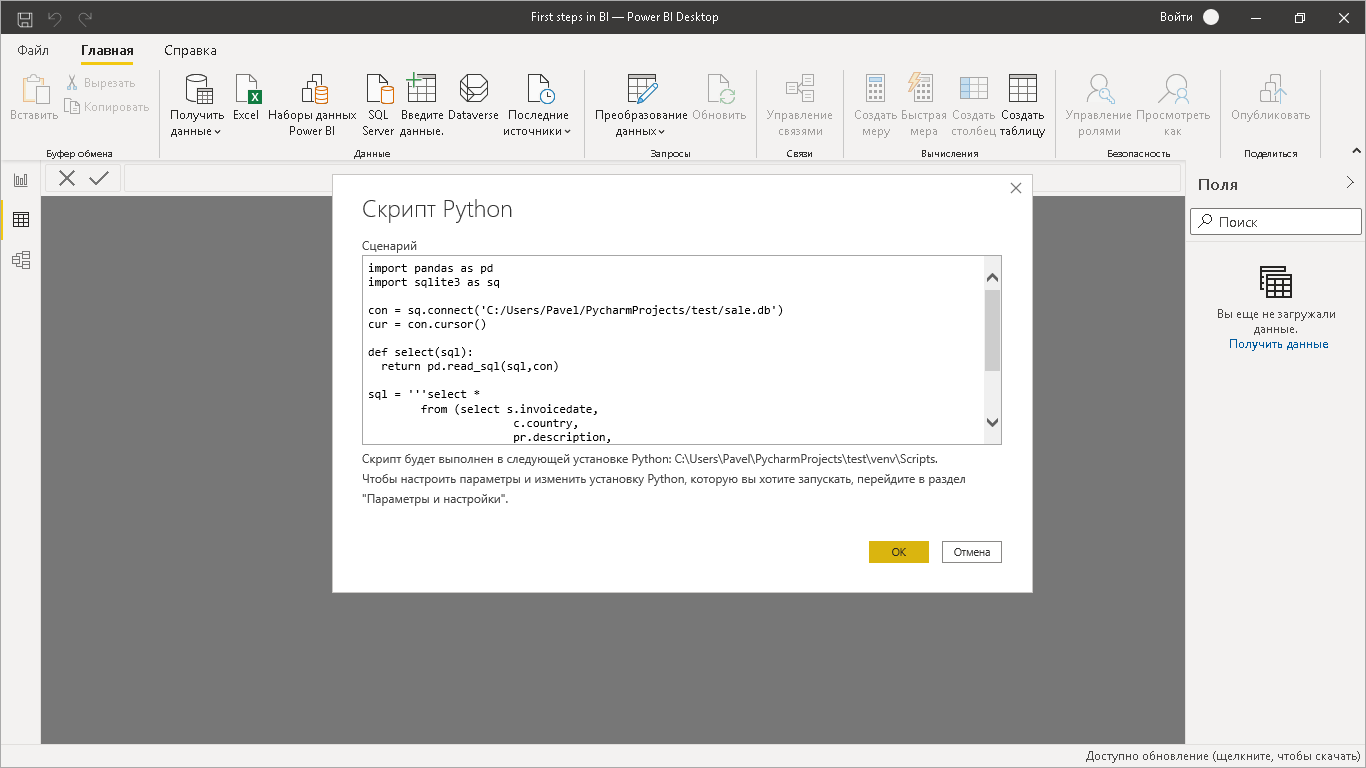
BI- SQLite Python.
import pandas as pd
import sqlite3 as sq
con = sq.connect('C:/Users/Pavel/PycharmProjects/test/sale.db')
cur = con.cursor()
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
replace(round(s.amount,1),'.',',') as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
tbl = select(sql)
print(tbl)
.
«Data – Workflow management platform + ETL – DB – BI» . .
. . .
. . BI. .
«Data – Workflow management platform + ELT – Data Lake – Workflow management platform + ETL – DB – BI» , : (Data Lake), (DB), .
. . , Data Lake.
. . Data Lake – , .
.
BI- .
BI , .
, SQL, - , , , .
That's all. All health, good luck and professional success!