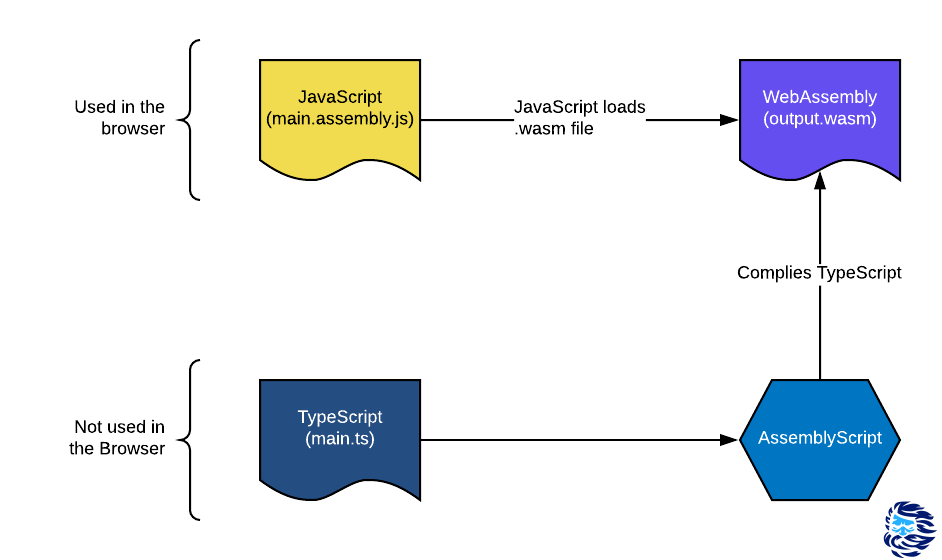
To improve the performance of web applications, use WebAssembly in conjunction with AssemblyScript to rewrite performance-critical JavaScript components of a web application. “And will it really help?” You ask.
Unfortunately, there is no clear answer to this question. It all depends on how you use them. There are many options: in some cases the answer will be negative, in others it will be positive. In one situation, it is better to choose JavaScript over AssemblyScript, and in another, it is the other way around. This is influenced by many different conditions.
In this article, we will analyze these conditions, propose a number of solutions, and test them on several test code examples.
Who am I and why am I doing this topic?
(You can skip this section, it is not essential for understanding further material).
I really like the AssemblyScript language . I even started helping developers financially at some point. They have a small team in which everyone is seriously passionate about this project. AssemblyScript is a very young TypeScript-like language capable of compiling to WebAssembly (Wasm). This is precisely one of its advantages. Previously, in order to use Wasm, a web developer had to learn foreign languages such as C, C ++, C #, Go or Rust, since such high-level, statically typed languages could initially be compiled into WebAssembly.
Although AssemblyScript (ASC) is similar to TypeScript (TS), it is not associated with that language and does not compile to JS. Similarity in syntax and semantics is needed to facilitate the process of "porting" from TS to ASC. This porting basically boils down to adding type annotations.
I was always interested in taking JS code, porting it to ASC, compiling it to Wasm, and comparing performance. When my colleague Ingvar sent me a JavaScript snippet to blur images , I decided to use it. I did a little experiment to see if it was worth exploring this topic more deeply. It turned out to be worth it. As a result, this article appeared.
To get a better understanding of AssemblyScript, you can explore the official website , join the Discord channel, or watch an introductory video on my Youtube channel. And we move on.
Benefits of WebAssembly
As I wrote above, for a long time the main task of Wasm was the ability to compile code written in high-level general-purpose languages. For example, at Squoosh (an online image processing tool) we use libraries from the C / C ++ and Rust ecosystem. These libraries were not originally designed for use in web applications, but WebAssembly makes it possible.
In addition, according to popular belief, compiling the source code in Wasm is also necessary because the use of Wasm binaries allows you to speed up the work of a web application. I agree, at a minimum, that under ideal (laboratory) conditions, WebAssembly and JavaScript binaries canprovide approximately equal values of peak performance. This is hardly possible on combat web projects.
In my opinion, it makes more sense to think of WebAssembly as one optimization tool for average, working performance values. Although recently, Wasm has the ability to use SIMD instructions and shared memory streams. This should increase its competitiveness. But in any case, as I wrote above, it all depends on the specific situation and initial conditions.
Below we will consider several such conditions:
Lack of warming up
The V8 JS engine processes the source code and presents it as an abstract syntax tree (AST). Based on the constructed AST, the optimized Ignition interpreter generates bytecode. The resulting bytecode is taken by the Sparkplug compiler and at the output it produces the not yet optimized machine code, with a large footprint. During the execution of the code, V8 collects information about the forms (types) of the objects used and then runs the optimizing compiler TurboFan. It generates low-level machine instructions optimized for the target architecture based on the collected information about the objects.
You can understand how JS engines work by studying the translation of this article .

JS engine pipeline. General schema
On the other hand, WebAssembly uses static typing, so you can immediately generate machine code from it. The V8 engine has a streaming Wasm compiler called Liftoff. Like Ignition, it helps you quickly prepare and run unoptimized code. And after that, the same TurboFan wakes up and optimizes the machine code. It will run faster than after compiling Liftoff, but it will take longer to generate.
The fundamental difference between the JavaScript pipeline and the WebAssembly pipeline: the V8 engine does not need to collect information about objects and types, since Wasm has static typing and everything is known in advance. This saves time.
Lack of de-optimization
The machine code TurboFan generates for JavaScript can only be used as long as the type assumptions are maintained. Let's say TurboFan has generated machine code, for example, for a function f with a numeric parameter. Then, upon encountering a call to this function with an object instead of a number, the engine again uses Ignition or Sparkplug. This is called de-optimization.
For WebAssembly, types cannot change during program execution. Therefore, there is no need for such de-optimization. And the types themselves that Wasm supports are organically translated into machine code.
Minimizing binaries for large projects
Wasm was originally designed with the compact binary file format in mind. Therefore, such binaries load quickly. But in many cases, they still turn out more than we would like (at least in terms of the volumes accepted on the network). However, with gzip or brotli, these files will compress well.
Over the years, JavaScript has learned a lot of things out of the box: arrays, objects, dictionaries, iterators, string processing, prototypal inheritance, and so on. All this is built into its engine. And the C ++ language, for example, can boast of a much larger scope. And every time you use any of these language abstractions when compiling to WebAssembly, the corresponding code under the hood must be included in your binary. This is one of the reasons for the proliferation of WebAssembly binaries.
Wasm doesn't really know anything about C ++ (or any other language). Therefore, the Wasm runtime does not provide a standard C ++ library and the compiler has to add it to each binary file. But such a code needs to be connected only once. Therefore, for larger projects, this does not greatly affect the resulting size of the Wasm binary, which in the end is often smaller than other binaries.
It is clear that, not in all cases it is possible to make an informed decision by comparing only the sizes of the binaries. If, for example, the AssemblyScript source code is compiled into Wasm, then the binary will really turn out to be very compact. But how fast will it run? I set myself the task of comparing different versions of JS and ASC binaries based on two criteria at once - speed and size.
Porting to AssemblyScript
As I already wrote, TypeScript and ASC are very similar in syntax and semantics. It's easy to assume there are similarities with JS, so porting is mostly about adding type annotations (or replacing types). To start porting Glur , JS-library for image blur.
Data type mapping
Built-in AssemblyScript types are implemented similarly to Wasm virtual machine (WebAssembly VM) types. If in TypeScript, for example, the Number type is implemented as a 64-bit floating point number (according to the IEEE754 standard), then in ASC there are a number of numeric types: u8, u16, u32, i8, i16, i32, f32, and f64. In addition, you can find common composite data types (string, Array, ArrayBuffer, Uint8Array, and so on) in the AssemblyScript standard library , which, with certain reservations, are present in TypeScript and JavaScript. I will not consider here the type mapping tables AssemblyScript, TypeScript and Wasm VM, this is a topic for another article. The only thing I want to note is that ASC implements the StaticArray type, for which I have not found analogues in JS and WebAssembly VM.
Finally, we turn to our example code from the glur library.
JavaScript:
function gaussCoef(sigma) {
if (sigma < 0.5)
sigma = 0.5;
var a = Math.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
return new Float32Array([
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
]);
}
AssemblyScript:
function gaussCoef(sigma: f32): Float32Array {
if (sigma < 0.5)
sigma = 0.5;
let a: f32 = Mathf.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
const r = new Float32Array(8);
const v = [
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
];
for (let i = 0; i < v.length; i++) {
r[i] = v[i];
}
return r;
}
The AssemblyScript code fragment contains an additional loop at the end, since there is no way to initialize the array through the constructor. ASC does not implement function overloading, so in this case we have only one constructor Float32Array (lengthOfArray: i32). AssemblyScript has callbacks, but no closures, so there is no way to use .forEach () to populate an array with values. So I had to use a regular for loop to copy one element at a time.
You may have noticed that in the code snippet on AssemblyScript Math, Mathf. , 64- , — 32-. Math . - , , f32. . .
:
It took me a long time to understand: the choice of types is very important. Blurring the image involves convolution operations, and that's a whole bunch of for loops going through all the pixels. It was naive to think that if all pixel indices are positive, the loop counters will also be positive. I shouldn't have chosen the u32 type (32-bit unsigned integer) for them. If any of these loops run in the opposite direction, it will become infinite (the program will loop):
let j: u32;
// ... many many lines of code ...
for (j = width — 1; j >= 0; j--) {
// ...
}
I did not find any other difficulties in porting.
D8 shell benchmarks
Okay, the bilingual code snippets are ready. Now you can compile ASC to Wasm and run the first benchmarks.
A few words about d8: this is a command shell for the V8 engine (it itself does not have its own interface), which allows you to perform all the necessary actions with both Wasm and JS. In principle, d8 can be compared with Node, which suddenly chopped off the standard library and only pure ECMAScript remained. If you do not have a compiled version of V8 in the locale (how to compile it is described here ), you cannot use d8. To install d8 use jsvu tool .
However, since the title of this section contains the word "Benchmarks", I find it important to provide some kind of disclaimer here: the numbers and results I received refer to code that I wrote in my chosen languages running on my computer (2020 MacBook Air M1) using the test scripts I created. Results are rough guidelines at best. Therefore, it would be rash to give generalized quantitative estimates of the performance of AssemblyScript with WebAssembly or JavaScript with V8 based on them.
You may have another question: why did I choose d8 and did not run scripts in the browser or Node? I believe that both the browser and Node, shall we say, are not sterile enough for my experiments. In addition to the necessary sterility, d8 makes it possible to control the pipeline of the V8 engine. I can capture any optimization scenario and use, for example, only Ignition, only Sparkplug or Liftoff so that the performance characteristics do not change in the middle of the test.
Experimental technique
As I wrote above, we have the opportunity to "warm up" the JavaScript engine before running the performance test. During this warm-up process, the V8 makes the necessary optimization. So I ran the blurring program 5 times before starting the measurements, then did 50 runs and ignored the 5 fastest and slowest runs to remove potential outliers and too large deviations in numbers.
See what happened:

On the one hand, I was glad that Liftoff produced faster code compared to Ignition and Sparkplug. But the fact that AssemblyScript, compiled in Wasm with the use of optimization, turned out to be several times slower than the JavaScript bundle - TurboFan, I was puzzled.
Although later I nevertheless admitted that the forces were not initially equal: a huge team of engineers has been working on JS and its V8 engine for many years, implementing optimization and other smart things. AssemblyScript is a relatively young project with a small team. The ASC compiler itself is one-pass and puts all optimization efforts on the Binaryen library ... This means that optimization is done at the Wasm VM bytecode level after most of the high-level semantics have already been compiled. The V8 has a clear advantage here. However, the blurring code is very simple - it is the usual arithmetic operations with values from memory. It seemed that ASC and Wasm should have done better with this task. What is the matter here?
Let's dig deeper
I quickly consulted the smart guys on the V8 team and the equally smart guys on the AssemblyScript team (thanks to Daniel and Max!). It turned out that when compiling ASC, the "bounds check" (boundary values) is not started.
V8 can look at the source JS code at any time and understand its semantics. It uses this information for repeated or additional optimization. For example, you have an ArrayBuffer containing a set of binary data. In this case, V8 expects that it would be most reasonable not just to chaotically run through memory cells, but to use an iterator through a for ... of loop.
for (<i>variable</i> of <i>iterableObject</i>) {
<i>statement</i>
}
The semantics of this operator ensures that we never overstep the bounds of the array. Consequently, the TurboFan compiler does not handle bounds checking. But before compiling ASC in Wasm, the semantics of the AssemblyScript language are not used for such optimization: all optimization is performed at the level of the WebAssembly virtual machine.
Fortunately, ASC still has a trump card up its sleeve - the unchecked () annotation. It indicates which values should be checked for the possibility of going out of bounds.
- prev_prev_out_r = prev_src_r * coeff [6];
- line [line_index] = prev_out_r;
The previous 2 lines need to be rewritten as follows:
+ prev_prev_out_r = prev_src_r * unchecked (coeff [6]);
+ unchecked (line [line_index] = prev_out_r);
Yes, there is more. In AssemblyScript, typed arrays (Uint8Array, Float32Array, and so on) are implemented in the image and likeness of ArrayBuffer. However, due to the lack of high-level optimization for accessing the array element with index i, each time you have to access memory twice: the first time - to load a pointer to the first array element and the second time - to load the element at offset i * sizeOfType. That is, you have to refer to the array as a buffer (via a pointer). In the case of JS, most often this does not happen, since V8 manages to do high-level optimization of array access using a single memory access.
To improve performance, AssemblyScript implements static arrays (StaticArray). They are similar to Array except that they have a fixed length. Therefore, the need to store a pointer to the first element of the array disappears. If possible, use these arrays to speed up your programs.
So, I took the AssemblyScript - TurboFan bunch (it worked faster) and called it naive. Then I added the two optimizations that I talked about in this section to it, and I got a variant called optimized.

Much better! We have made significant progress. AssemblyScript is still slower than JavaScript though. Is this all we can do? [spoiler: no]
Oh, these silences
The guys from the AssemblyScript team also told me that the --optimize flag is equivalent to -O3s. It optimizes the speed of work well, but does not bring it to the maximum, since at the same time it prevents the growth of the binary file. The -O3 flag optimizes only the speed and does it to the end. Using -O3s by default seems to be correct, since it is customary in web development to reduce the size of binaries, but is it worth it? At least in this particular example, the answer is no: -O3s saves a paltry ~ 30 bytes, but overlooks a significant drop in performance:

One single optimizer flag just flips the game: Finally, AssemblyScript has overtaken JavaScript (in this particular test case!).
I will no longer indicate the O3 flag in the table, but rest assured: from now on until the end of the article, it will be invisible to us.
Bubble sort
To make sure that the blurry example is not just an accident, I decided to take another one. I took the sorting implementation on StackOverflow and went through the same process:
- ported the code by adding types;
- launched the test;
- optimized;
- ran the test again.
(I haven't tested creating and populating an array for bubble sort).
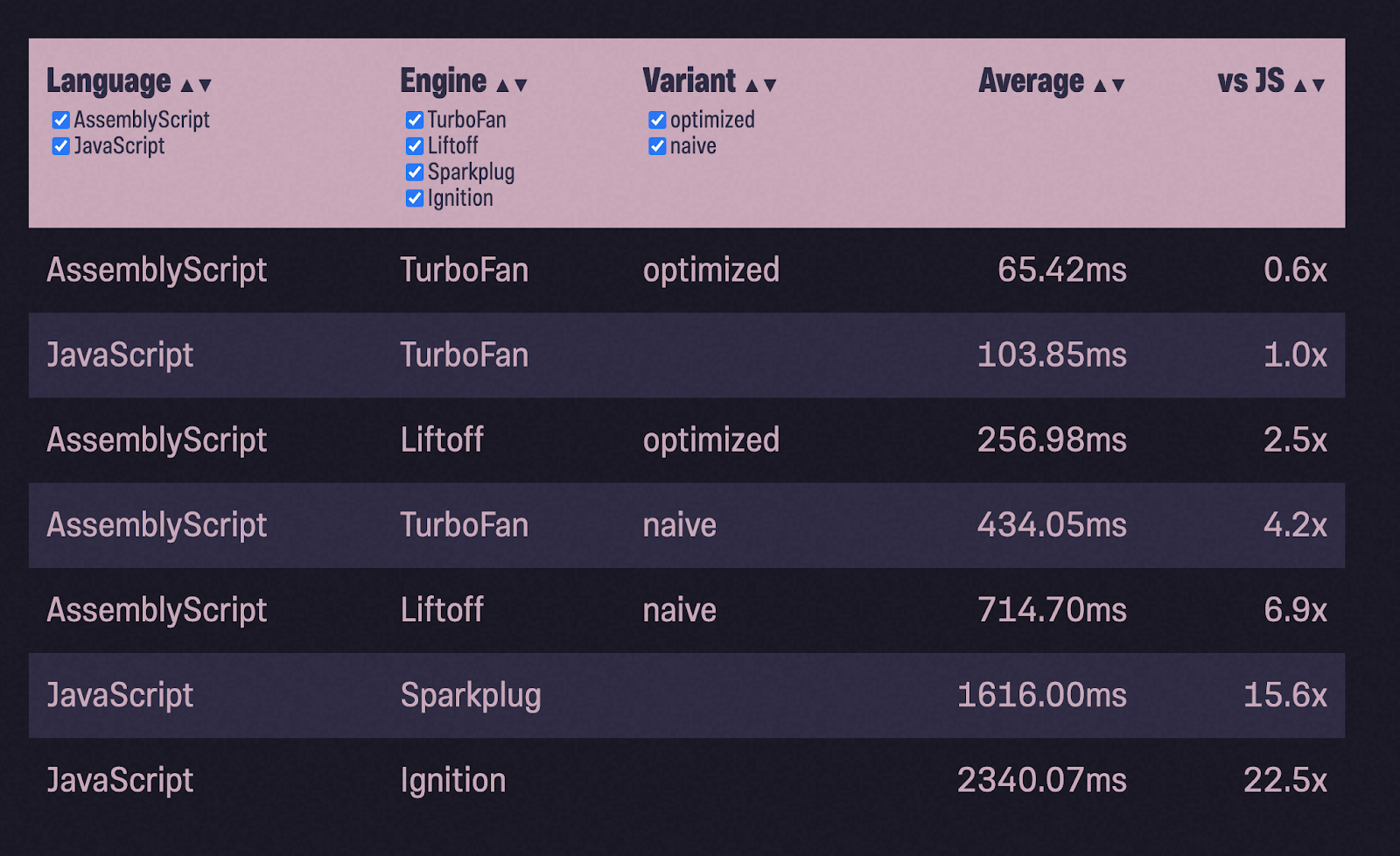
We did it again! This time with an even bigger speed gain: the optimized AssemblyScript is nearly twice as fast as JavaScript. But that's not all. Further ups and downs await me again. Please don't switch!
Memory management
Some of you may have noticed that both of these examples don't really show how to work with memory. In JavaScript, V8 takes care of all memory management (and garbage collection) for you. In WebAssembly, on the other hand, you end up with a chunk of linear memory and you have to decide how to use it (or rather Wasm has to decide). How much will our table change if we use heap intensively?
I decided to take a new example with a binary heap implementation ... During testing, I fill a heap with 1 million random numbers (courtesy of Math.random ()) and pop () returns them back, checking if the numbers are in ascending order. The general scheme of work remains the same: port the JS code to ASC, compile with the naive configuration, run the tests, optimize and run the tests again:
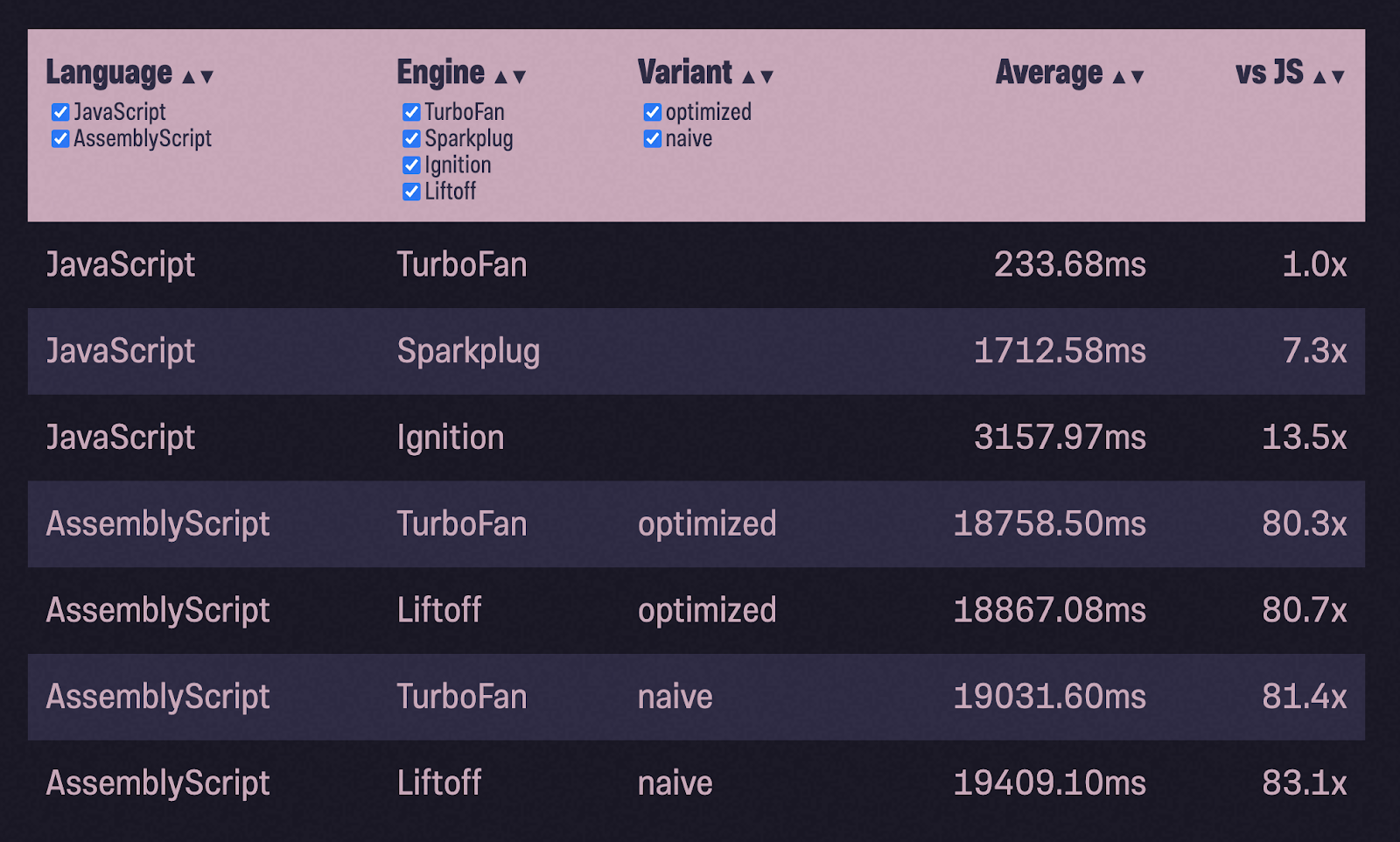
80x slower than JavaScript with TurboFan ?! And 6x slower than Ignition! What went wrong?
Setting up the runtime environment
All data that we generate in AssemblyScript must be stored in memory. But we need to make sure we don't overwrite anything else that's already there. Since AssemblyScript tends to mimic JavaScript behavior, it also has a garbage collector, and when compiled, it adds this collector to the WebAssembly module. ASC doesn't want you to worry about when to allocate and when to free memory.
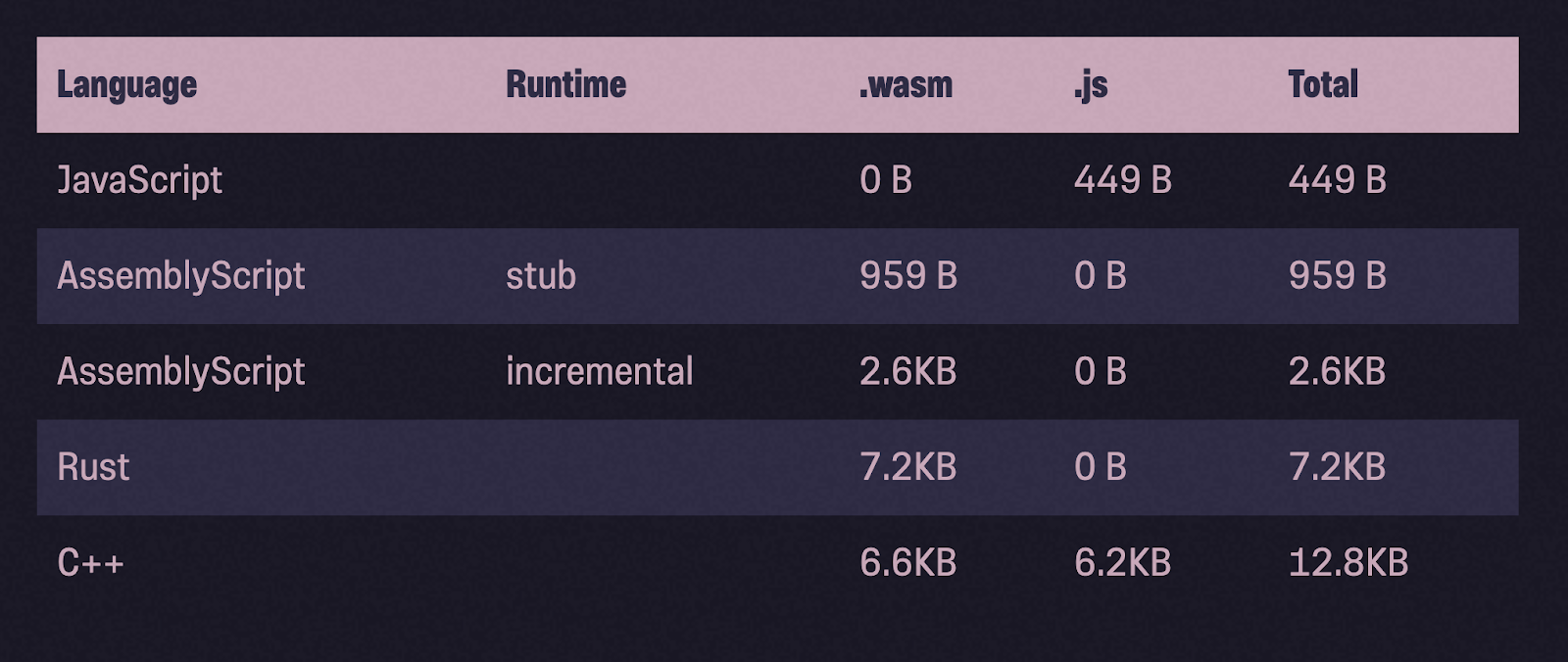
In this mode (called incremental) it works by default. At the same time, only about 2 KB in the gzip archive is added to the Wasm module. AssemblyScript also offers alternative modes, minimal and stub. Modes can be selected using the --runtime flag. Minimal uses the same memory allocator, but a lighter weight garbage collector that does not start automatically, but must be called manually. This is useful when developing high-performance applications (like games) where you want to control when the garbage collector pauses your program. In stub mode, very little code is added to the Wasm module (~ 400B in gzip format). It works quickly, since a backup allocator is used (more details about allocators are written here ).
Redundant allocators are very fast, but they cannot free memory. It may sound silly, but it can be useful for "one-time" instances of modules, where after completing the task, instead of freeing memory, you delete the entire WebAssembly instance and create a new one.
Let's see how our module will work in different modes:

Both minimal and stub brought us sharply closer to the level of JavaScript performance. I wonder why? As mentioned above, minimal and incremental use the same allocator. Both also have a garbage collector, but minimal doesn't run it unless it's called explicitly (which I don't). This means that the whole point is that incremental starts garbage collection automatically, and often does it unnecessarily. Well, why is this necessary if it only needs to track one array?
Memory allocation problem
After running the Wasm module in debug mode (--debug) several times, I found that the speed of work slows down due to the libsystem_platform.dylib library. It contains OS-level primitives for threading and memory management. Calls to this library are made from __new () and __renew (), which in turn are called from Array # push: I see: there is a memory management problem here. But JavaScript somehow manages to quickly process an ever-growing array. So why can't AssemblyScript do this? Fortunately, the AssemblyScript standard library source is publicly available , so let's take a look at this sinister push () function of the Array class:
[Bottom up (heavy) profile]:
ticks parent name
18670 96.1% /usr/lib/system/libsystem_platform.dylib
13530 72.5% Function: *~lib/rt/itcms/__renew
13530 100.0% Function: *~lib/array/ensureSize
13530 100.0% Function: *~lib/array/Array#push
13530 100.0% Function: *binaryheap_optimized/BinaryHeap#push
13530 100.0% Function: *binaryheap_optimized/push
5119 27.4% Function: *~lib/rt/itcms/__new
5119 100.0% Function: *~lib/rt/itcms/__renew
5119 100.0% Function: *~lib/array/ensureSize
5119 100.0% Function: *~lib/array/Array#push
5119 100.0% Function: *binaryheap_optimized/BinaryHeap#push
export class Array<T> {
// ...
push(value: T): i32 {
var length = this.length_;
var newLength = length + 1;
ensureSize(changetype<usize>(this), newLength, alignof<T>());
// ...
return newLength;
}
// ...
}
So far, everything is correct: the new length of the array is equal to the current length, increased by 1. Next, a call to the ensureSize () function follows to make sure that there is enough capacity in the buffer (Capacity) for the new element.
function ensureSize(array: usize, minSize: usize, alignLog2: u32): void {
// ...
if (minSize > <usize>oldCapacity >>> alignLog2) {
// ...
let newCapacity = minSize << alignLog2;
let newData = __renew(oldData, newCapacity);
// ...
}
}
The ensureSize () function, in turn, checks: Is Capacity less than the new minSize? If so, allocate a new minSize buffer using the _renew () function. This entails copying all data from the old buffer to the new buffer. For this reason, our test with filling the array with 1 million values (one element after the other) leads to the reallocation of a large amount of memory and creates a lot of garbage.
In other libraries (like std :: vec in Rust or slicesin Go), the new buffer has twice the Capacity of the old one, which helps make the process of working with memory less expensive and slow. I'm working on this problem in ASC, and so far the only solution is to create my own CustomArray, with its own memory optimization.

Now incremental is as fast as minimal and stub. But JavaScript remains the leader in this test case. I could probably make more optimizations at the language level, but this is not an article on how to optimize AssemblyScript itself. I've already sunk deep enough.
There are many simple optimizations the AssemblyScript compiler could do for me. To this end, the ASC team is working on a high-level IR (Intermediate Representation) optimizer called AIR. Can this make the job faster and save me from having to manually optimize the array access every time? Most likely. Will it be faster than JavaScript? Hard to say. But in any case, it was interesting for me to compete for ASC, evaluate the capabilities of JS and see what a more "mature" language with "very smart" compilation tools can achieve.
Rust & C ++
I rewrote the code in Rust, as idiomatically as I could, and compiled it to WebAssembly. It turned out to be faster than AssemblyScript (naive), but slower than our optimized AssemblyScript with CustomArray. Next, I optimized the module compiled from Rust in much the same way as AssemblyScript. With this optimization, the Rust-based Wasm module is faster than our optimized AssemblyScript, but still slower than JavaScript.
I took the same approach to C ++, using Emscripten to compile to WebAssembly . To my surprise, even the first option without optimization turned out to be no worse than JavaScript.

There is no picture URL here. I took a screenshot myself.
Versions marked as idiomatic were influenced by JS source code anyway. I tried to use my knowledge of the idioms of Rust, C ++, but the installation was firmly in my head that I was doing porting. I am sure that someone with more experience in these languages could implement the task from scratch and the code would look different.
I'm pretty sure Rust and C ++ modules could run even faster. But I did not have enough deep knowledge of these languages to squeeze more out of them.
Again about the size of binaries
Let's take a look at the sizes of the binaries after gzip compression. Compared to Rust and C ++, AssemblyScript binaries are indeed much lighter in weight.
And yet ... recommendations
I wrote about this at the beginning of the article, and I will repeat it now: the results are at best approximate guidelines. Therefore, it would be rash to give generalized quantitative estimates of productivity on their basis. For example, you can't say that Rust is 1.2 times slower than JavaScript in all cases. These numbers are very dependent on the code I wrote, the optimizations I applied, and the machine I used.
Still, I think there are some general guidelines that we can learn to help you better understand the topic and make better decisions:
- Liftoff AssemblyScript Wasm-, , , Ignition SparkPlug JavaScript. JS-, WebAssembly — .
- V8 JavaScript-. WebAssembly , JavaScript, , .
- , , .
- AssemblyScript modules are generally much lighter than Wasm modules compiled from other languages. In this article, the AssemblyScript binary was no smaller than the JavaScript binary, but the opposite is true for larger modules, as stated by the ASC development team.
If you don’t believe me (and you don’t have to) and want to figure out the code of the test cases on your own, here they are .
Our servers can be used for WebAssembly development.
Register using the link above or by clicking on the banner and get a 10% discount for the first month of renting a server of any configuration!
