Today I will tell you why outsourced delivery is not always good, why you need process transparency and how we wrote a platform in a year and a half that helps our couriers deliver orders. I will also share three stories from the development world.

Pictured is the courier platform team ten months ago. In those days, she was placed in one room. Now there are 5 times more of us.
Why did we do all this
When developing the courier platform, we wanted to upgrade three main things.
The first is quality . When we work with external delivery services, quality cannot be controlled. The contractor company promises that there will be such and such a deliverability, but a certain number of orders may not be delivered. And we wanted to reduce the percentage of delays to a minimum, so that almost any order was delivered on time.
Second is transparency... When something goes wrong (there are transfers, deadlines), then we do not know why they happened. We cannot go and tell: "Guys, let's do it like this." We ourselves do not see, and we cannot show the client any additional things. For example, that the order will arrive not at eight, but within 15 minutes. This is because there is no such level of transparency in the process.
The third is money... When we work with a contractor, there is a contract in which the amounts are spelled out. And we can change these numbers within the framework of the contract. And when we are responsible for the whole process from a to z, then you can see which parts of the system are designed economically unprofitable. And you can, for example, change the SMS provider or document flow format. Or you may notice that couriers have too high mileage. And if you build routes more closely, then in the end you will be able to deliver more orders. Thanks to this, you can also save money - delivery will become more efficient.
These were the three goals that we set at the head of everything.
What the platform looks like
Let's see what we got.
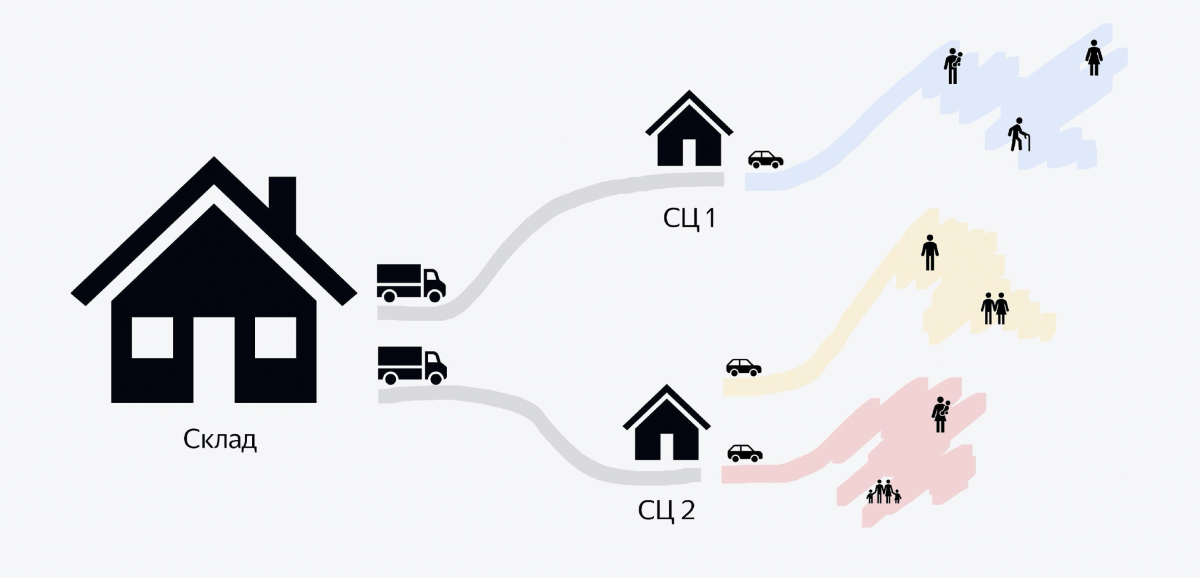
The image shows a diagram of the process. We have large warehouses that hold hundreds of thousands of orders. Trucks filled to the brim with orders leave each warehouse in the evening. There may be 5-6 thousand orders. These trucks travel to smaller buildings called sorting centers. In them, in a few hours, a large pile of orders turns into small piles for couriers. And when couriers arrive in their cars in the morning, each courier knows that he needs to pick up a bunch with this QR code, load it into his car and go to deliver.
And the backend that I want to talk about in this article is about the very last part of the process when orders are taken to customers. We'll leave aside everything before that.
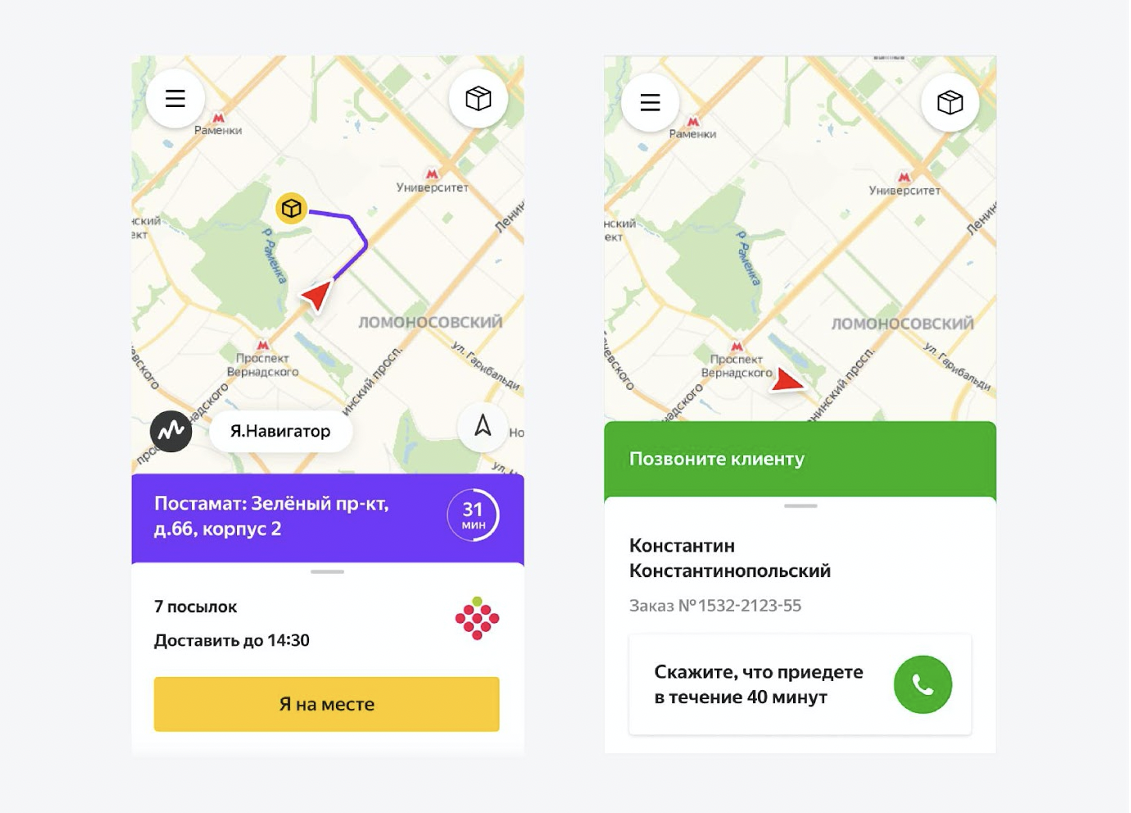
How the courier sees it
Couriers have an Android app written in React Native. And in this application, they see their whole day. They clearly understand the sequence: which address to go to first, which one later. When to call a customer, when to take returns to the sorting center, how to start the day, how to end it. They see everything in the application and practically do not ask unnecessary questions. We help them a lot. Basically, they are just doing assignments.
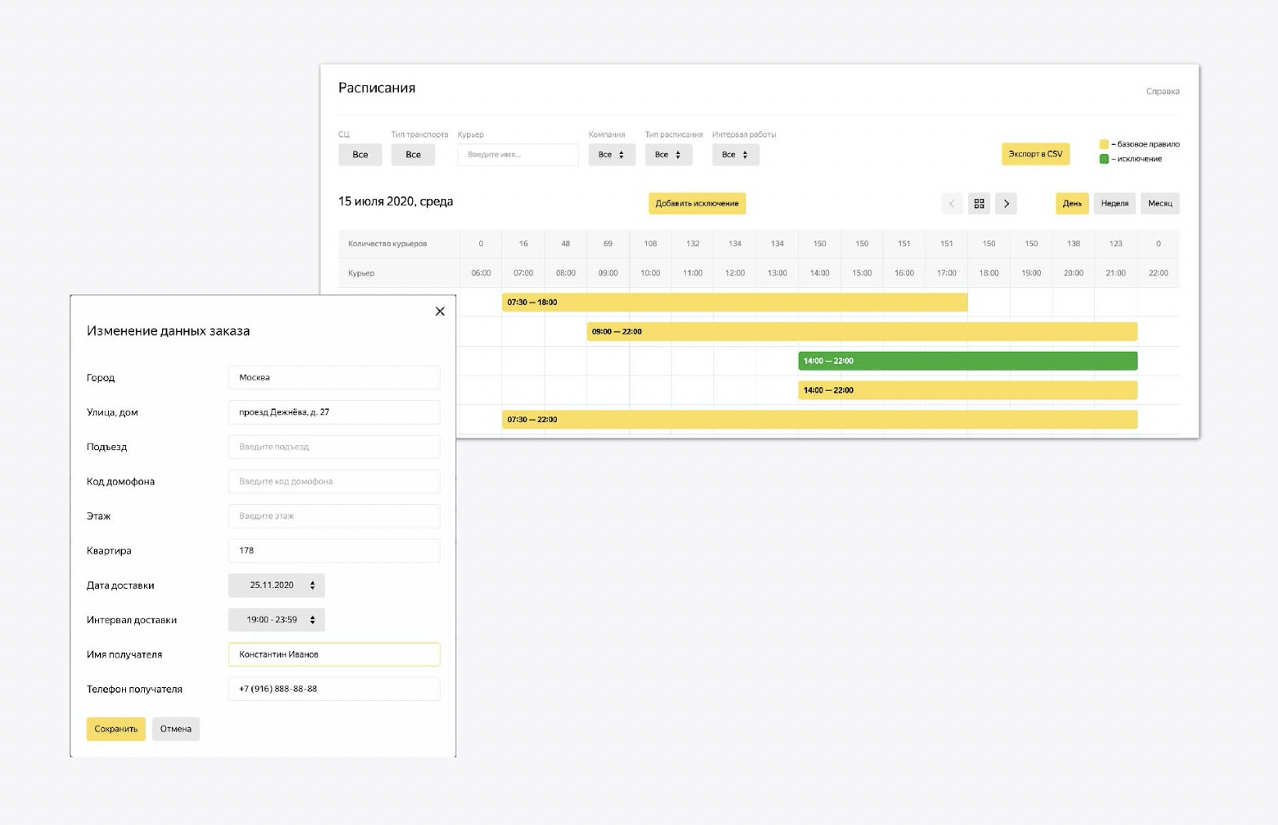
In addition, there are controls on the platform. This is a multifunctional admin panel that we reused from another Yandex service. In this admin area, you can configure the state of the system. We upload data about new couriers there, change the work intervals. We can adjust the process of creating tasks for tomorrow. Almost everything you need is regulated.
By the way, about the backend. We in the Market love Java very much, mainly version 11. And all the backend services, which will be discussed, are written in Java.
Architecture
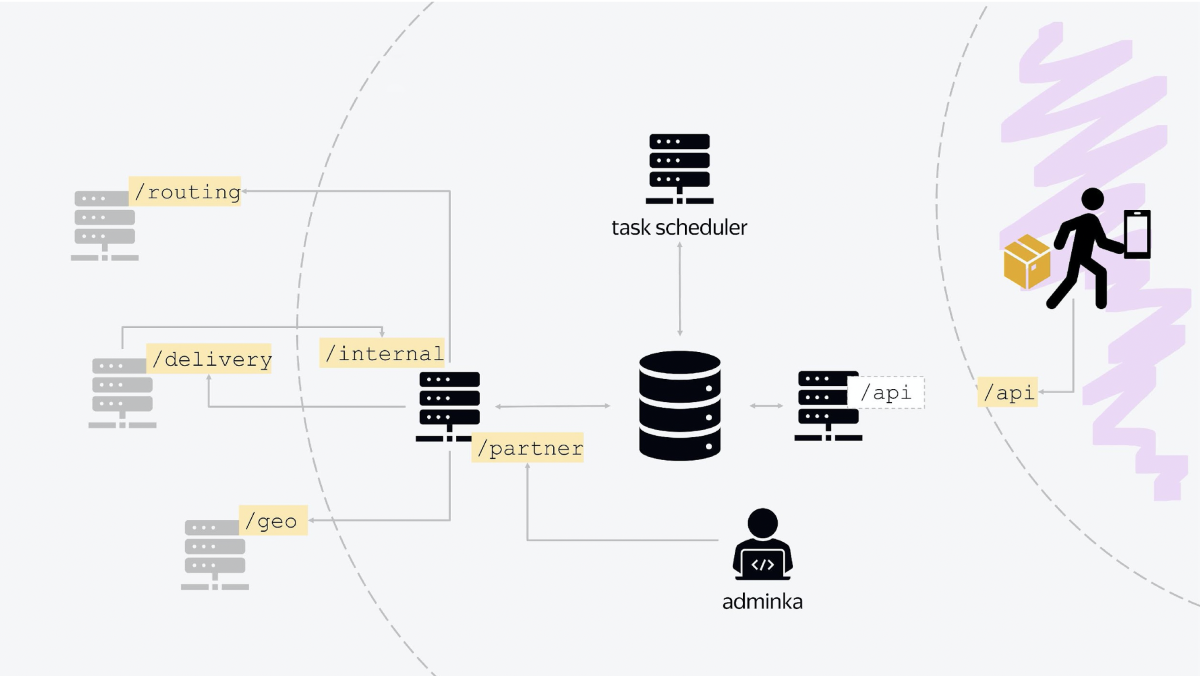
There are three main nodes in our platform architecture. The first is responsible for communication with the outside world. The courier application "knocks" on the balancer, which is brought out, communicating with it using the standard JSON HTTP API. In fact, this node is responsible for all the logic of the current day, when couriers transfer something, cancel something, issue orders, receive new tasks.
The second node is a service that communicates with Yandex internal services. All services are classic RESTful services with standard communication. When you place an order on the Market, after a while a document in JSON format will arrive to you, where everything will be written: when we deliver, to whom we deliver, at what interval. And we will save this state to the database. It's simple.
In addition, the second node also communicates with other internal services, not Market, but Yandex. For example, to clarify geocoordinates, we go to the geoservice. To send a push notification, we go to the service that sends push and SMS. We use another service for authorization. Another service for calculating routing for tomorrow. Thus, all communication with internal services is carried out.
This node is also an entry point, it has an API that our admin panel knocks on. It has its own endpoint, which is called, say, / partner. And our admin panel, the entire state of the system, is configured through communication with this service.
The third node is the background task base. Here Quartz 2 is used, there are tasks that are launched on the crown with different conditions for different points, for different sorting centers. There are tasks of updating the day, tasks of closing the day, starting a new day.
And at the center of everything is the database, which, in fact, stores all the state. All services are included in one database.
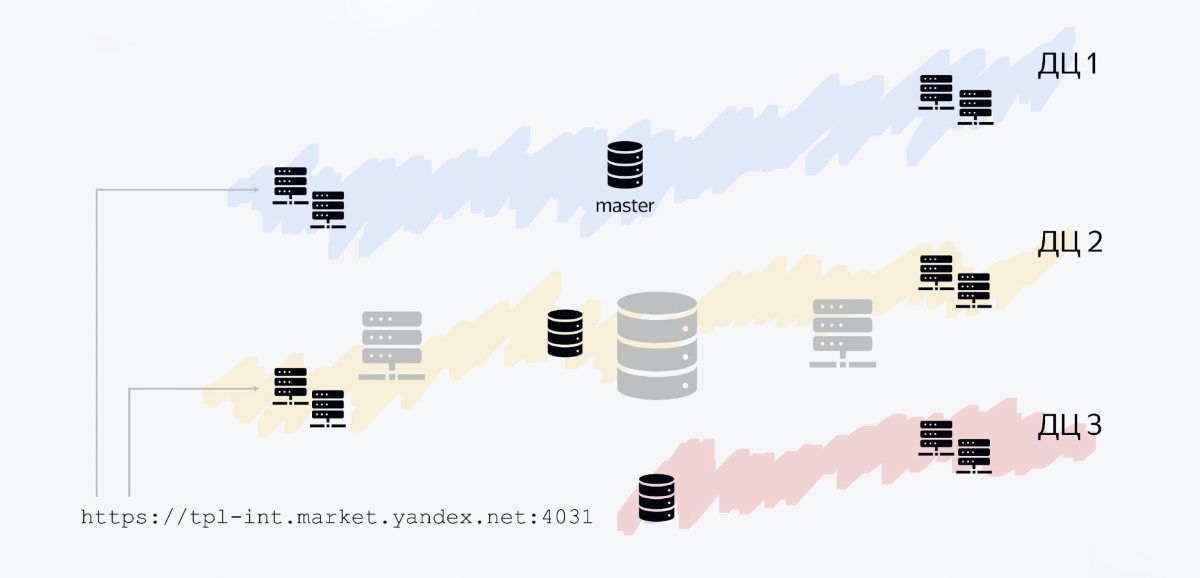
fault tolerance
Yandex has several data centers, and our service is regionally distributed across three data centers. What it looks like.
The database consists of three hosts, each in its own data center. One host is the master, the other two are replicas. We write to the master, we read from the lines. All other Java services are also Java processes that run in multiple data centers.
One of the nodes is our API. It runs in all three data centers, because the flow of messages is greater than from internal services. Moreover, such a layout allows you to scale horizontally quite easily.
For example, if your incoming traffic increases nine times, you can optimize, but you can also "flood" this business with iron by opening more nodes that will process the incoming traffic.
The balancer will simply have to divide the traffic into a larger number of points that fulfill requests. And now, for example, we have not one node, but two nodes in each data center.
Our architecture allows us to cope even with such cases as the shutdown of one of the data centers. For example, we decided to conduct an exercise and turned off the data center in Vladimir - and our service remains afloat, nothing changes. The database hosts that lie there disappear, and the service remains in operation.
The balancer understands after a while: yeah, I have not a single live host left in this data center, and it no longer redirects traffic there.
All services in Yandex are arranged in a similar way, we all know how to survive the failure of one of the data centers. We have already described how this is implemented, what graceful degradation is, and how Yandex services handle the shutdown of one of the data centers .
So that was architecture. And now the stories begin.
The first story - about Yandex.Rover
Recently we had Yet another Conference, where Rover received a lot of attention. I will continue the topic.
Once the guys from the Yandex.Rover team came to us and offered to test the hypothesis that people would want to receive orders in such an extraordinary way.
Yandex.Rover is a small robot the size of an average dog. You can put food there, a couple of boxes of orders - he will go around the city and bring orders without human help. There is a lidar, the robot understands its position in space. He knows how to deliver small orders.
And we thought: why not? We clarified the details of the experiment: at that time it was necessary to test the hypothesis that people would like it. And we decided to deliver 50 orders in a week and a half in a very light mode.
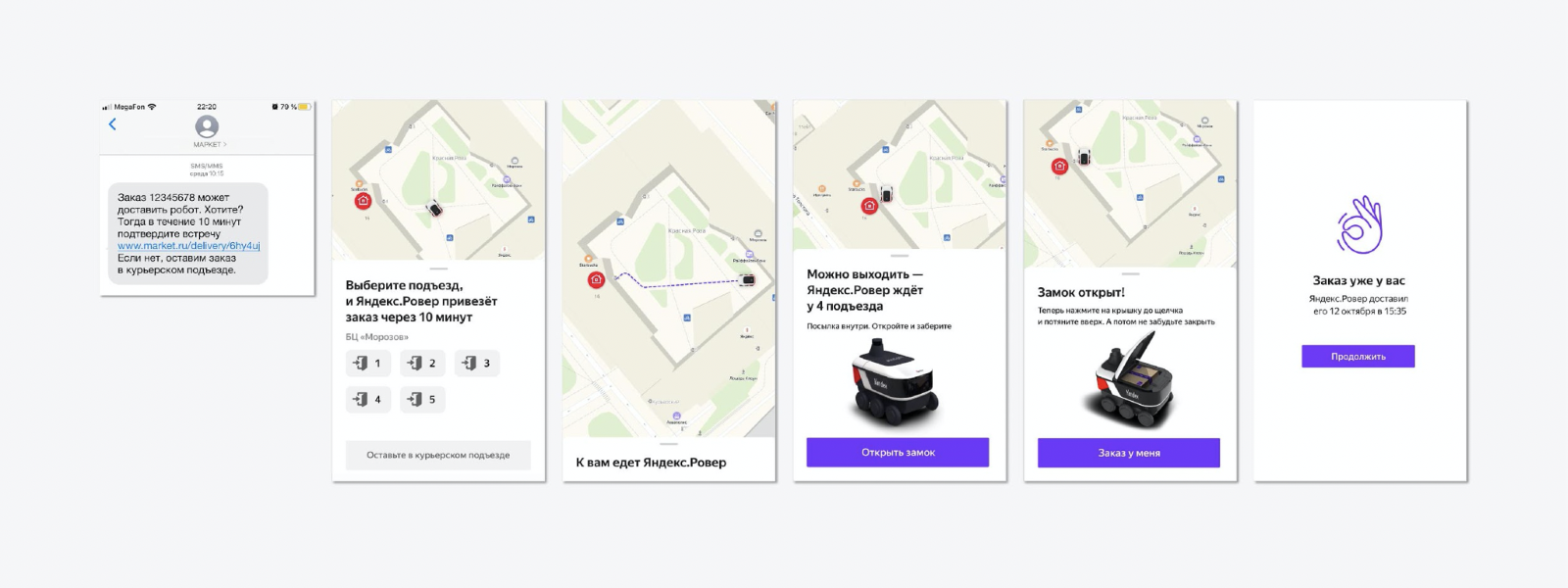
We came up with the most simple flow, when a person receives an SMS with a proposal for a non-standard delivery method - not the courier will bring it, but the Rover. The entire experiment took place in Yandex's courtyard. The man was choosing the entrance to which the Rover would drive up. When the robot arrived, the lid was opened, the client took the order, closed the lid, and Rover left for a new order. It's simple.
Then we went to Rover's team to negotiate an API.
There are simple methods in the Rover API: open the lid, close the lid, go to a certain point, get a state. Classic. Also JSON. Very simple.
What is also very important: both such small stories and any large stories are best done through feature flags. In fact, you have a switch by which you can enable this story in production. When you no longer need it, the experiment was completed successfully or not successfully, or you noticed some bugs, you just cut it down. And you don't need to do another deployment of the new version of the code for production. This thing makes life a lot easier.
It would seem that everything is simple and everything should work. There is even nothing to develop there for two weeks, you can do it in a few days. But look where the dog is buried.
All processes are mostly synchronous. The man presses a button, the lid opens. The man presses the button, the lid closes. But one of these processes is asynchronous. At the moment when the Rover goes to you, you need to have some kind of background process that will track that the robot has returned to the point.
And at this moment we will send an SMS to the person, for example, that the Rover is waiting at the place. This cannot be done synchronously, and you need to somehow solve this problem.
There are many different approaches. We've made it as simple as possible.
We decided that we can run the most common background Java thread or task in Executer. This background thread is immediately launched to track the process. And as soon as the process is done, we send a notification.
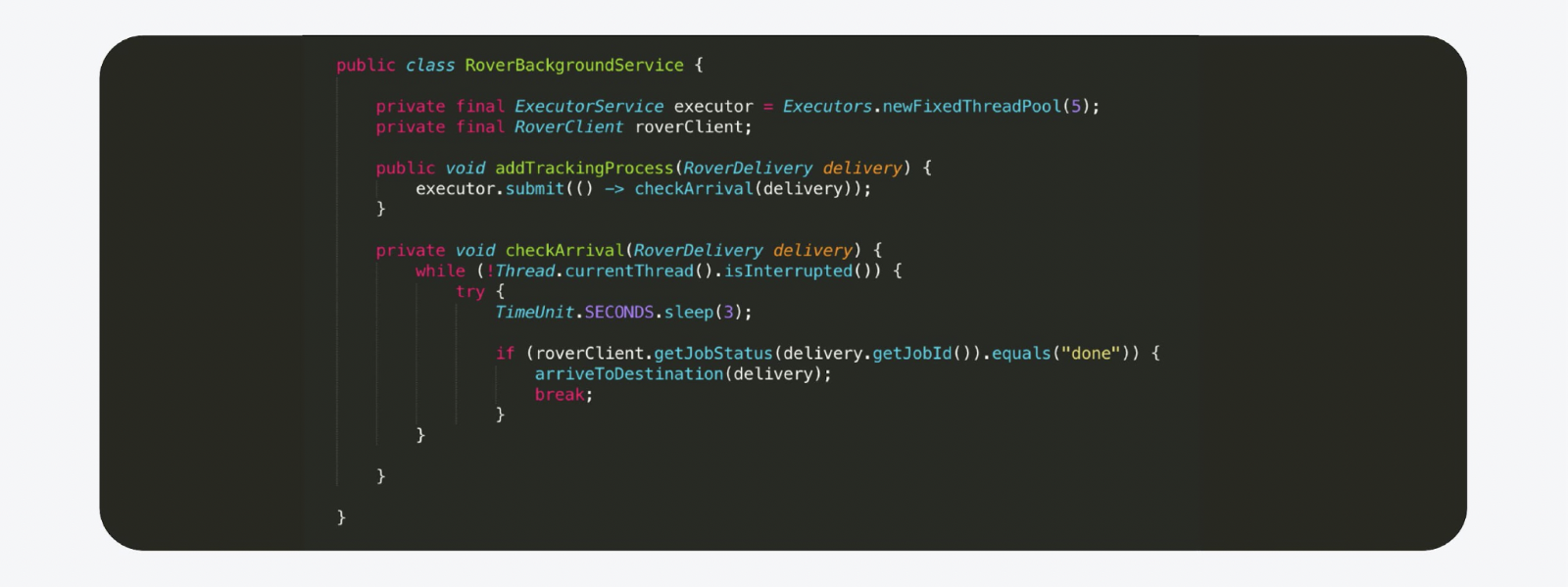
For example, it looks like this. This is practically a copy of the production code, with the exception of the stripped comments. But there is a catch. You cannot make serious systems in this way. Let's say we are rolling out a new version to the backend. The host reboots, the state is lost, and that's it, the Rover goes to infinity, no one else sees him.
But why? If we know that our goal is to deliver 50 orders in a week and a half, we choose the time when we monitor the backend. If something goes wrong, you can manually change something. For such a task, this solution is more than sufficient. And this is the moral of the first story.
There are situations for which you need to make the minimum version of the functionality. There is no need to fence a garden and over-engineering. It is better to make it as alienated as possible. So as not to change the logic of internal objects too much. And excess complexity, unnecessary technical debt did not accumulate.
The second story - about databases
But first, a few words about how the main entities are arranged. There is a Yandex.Routing service that builds routes for couriers at the end of the day.
Each route consists of points on the map. And at each point the couriers have a task. This can be a task to issue an order, or call a client, or in the morning load up at the sorting center, pick up all orders.
In addition, clients receive a tracking link in the morning. They can open the map and see how the courier travels to them. The client can also choose delivery by Rover, which I mentioned earlier.
Now let's see how these entities can be displayed in the database. This is done, for example, like this.
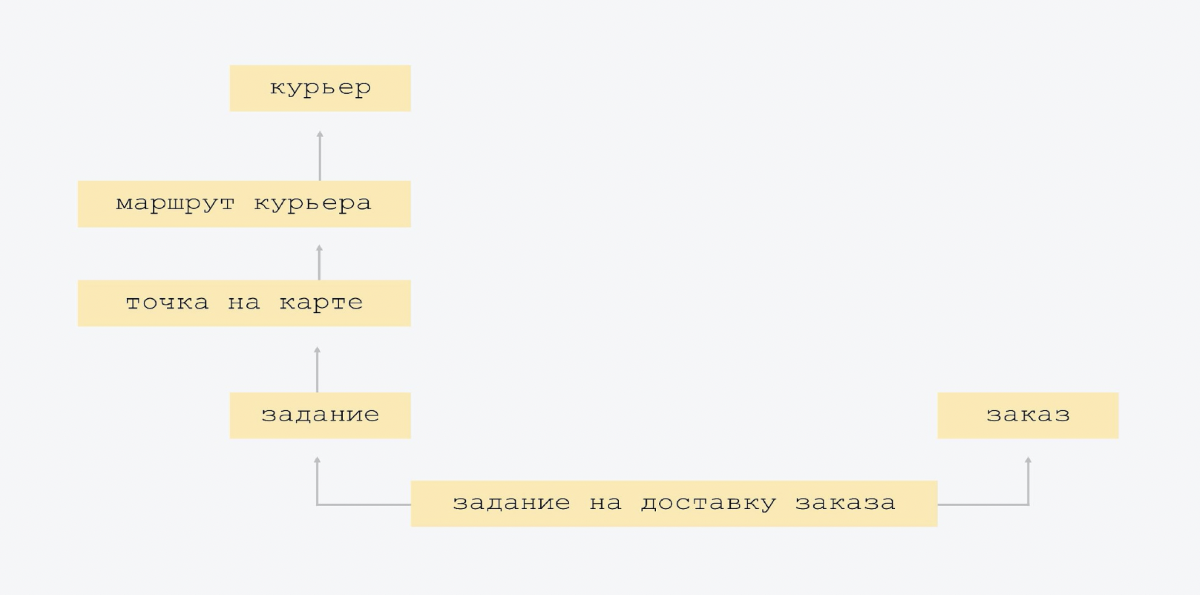
This is a very neat data model. We did not invent a single new entity, and we did not strongly collapse the existing ones.
The diagram shows that the arrow from bottom to top shows the courier's route, knows the courier whose route it is. The courier route sign contains the courier ID link. And the top plate does not know this. We have the most simple connectivity, there is no big intersection of entities. When everyone knows about everyone, it is more difficult to control and, most likely, there will be redundancy. Therefore, we have the simplest possible scheme.
The only "overkill" that we made at the very beginning of creating the platform is this. We had one type of delivery assignment. But we realized that in the future there will be other tasks. And we put in a little architectural flexibility: we have tasks, and one of the types of tasks is order delivery.
Then we added tracking and Rover. Just two tablets. In tracking, the courier sends his coordinates, we record them in a separate plate. And there is order tracking with its own state model, there are additional things, such as "SMS left / did not go away." You shouldn't add this directly to the task. It is better to put it in a separate plate, because this tracking is not needed for all types of tasks.
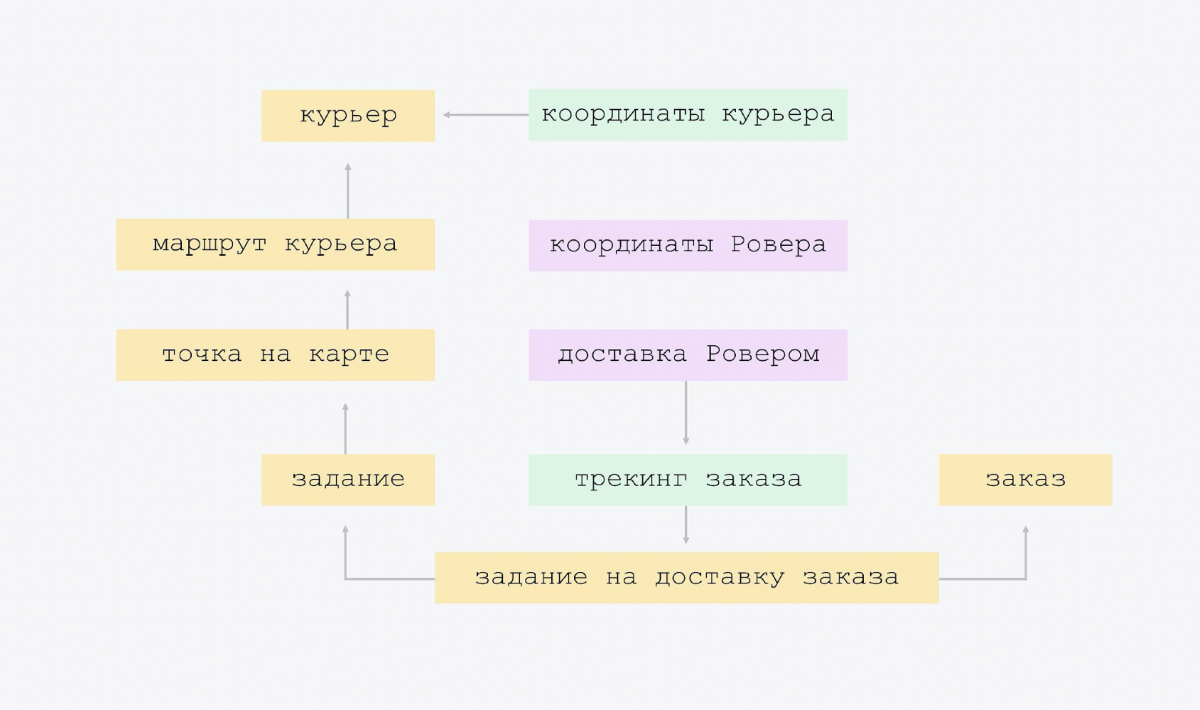
In Rover - his coordinates and delivery. Our delivery by Rover is like tracking for Rover. You can add it to the tracking order, but why? After all, when we get rid of this experiment, when it is turned off, these options will forever remain in the essence of tracking. There will be null fields.
The question may arise: why make a plate with coordinates? One Rover delivers five orders a day. You do not need to store coordinates in the database, you can just go to the Rover API and get them at runtime.
The bottom line is that this was done initially. This sign was not there, we immediately went to the service and took it all. But during the tests, we saw that many people open a map with a rolling Rover, and the load on this service increases many times. Let's say seven people opened it. And there on the page every two seconds Java Script asks for coordinates. And colleagues wrote to us in the chat: “Where does such a load come from? You have one person there to skate. "
And after that we added a sign. We began to add the coordinates there, the time at which they were received. And now, if people come to us too often for coordinates and two seconds have not passed since the last receipt, we take them from the plate. It turns out such a cache at the database level.
This story could be done with 20 tables. Two tables could be used: courier and order. But in the first case, it would be over-engineering, and in the second case, it would be too difficult to maintain. Complex logic, difficult to test.
And further. The structure of the databases, which we made a year and a half ago, the core of these entities has remained unchanged to this day. And we were very lucky that we were able to choose such entities on which the base did not have to be redone. There was no need to significantly redraw the databases, make complex migrations, then roll this release, test it for a very long time and then change the root structure.
The point of the story is that there are aspects to which it is better to pay extra attention. The first is pay special attention to the structure of the API and database . Try to notice what kind of entities you have in real life. Try to digitize this structure in much the same way. Try not to shorten it too much, not to expand it too much.
Second, there are mistakes that are expensive to fix . Errors at the API level are more difficult to fix than errors at the database level because there are usually many clients using the API. And when you change the API a lot, you have to:
- reach all clients, ensure backward compatibility;
- roll out the new API, switch all clients to the new API;
- cut out the old code about clients, cut out the old code on the backend.
This is very expensive.
Errors in the code are generally nonsense compared to this. You just rewrote the code, ran the tests. Tests are green - you have pushed into the master. Pay special attention to the database API.
And no matter how hard you try to keep track of the database, over time it will turn into something unmanageable. On the screenshot, you can see one tenth of our database, which now exists.
There is one piece of advice. When you develop something very quickly, there are inaccuracies in the database, sometimes a foreign key is missing or a duplicate field appears. Therefore, sometimes, once every two or three months, just look only at the base. The same Intellij IDEA is able to generate cool circuits. And there you can see it all.
Your database must be adequate. It is very easy to make a list of six tickets in an hour: add a foreign key here, there an index. No matter how hard you try, some debris will inevitably accumulate.
The third story is about quality
There are things that are best done well from the start. It is important to act according to the principle "do it normally, it will be fine."
For example, we have one process that is critical to the platform. All day we are collecting orders for tomorrow, but in the evening a note is triggered that after 22:00 we do not collect orders, but before 01:00 we are preparing for tomorrow. Then the distribution of orders to sorting centers begins. We go to Yandex.Routing, it builds routes.
And if this preparatory work fails, the whole tomorrow is in question. Tomorrow the couriers will have nowhere to go. They have not created a state. This is the most critical process in our platform. And such important processes cannot be done on a leftover basis, with minimal resources.
I remember we had a time when this process failed, and for several weeks almost half of the team in the chat was solving these problems, everyone was saving the day, reworking something, restarting.
We understood that if the process was not completed from ten in the evening until one in the morning, then sorting centers would not even know how to sort orders, into which heaps. Everything will be idle there. Couriers will come out later and we will have quality failures.
It is better to do such processes as well as possible right away, thinking over every step where something can go wrong. And put the maximum amount of straw everywhere.
I'll tell you about one of the options for how you can set up such a process.
This process is multi-component. The calculation of routes and their publication can be split into parts and, for example, queues can be created. Then we have several queues that are responsible for the completed sections of work. And there are consumers on these queues that sit and wait for messages.
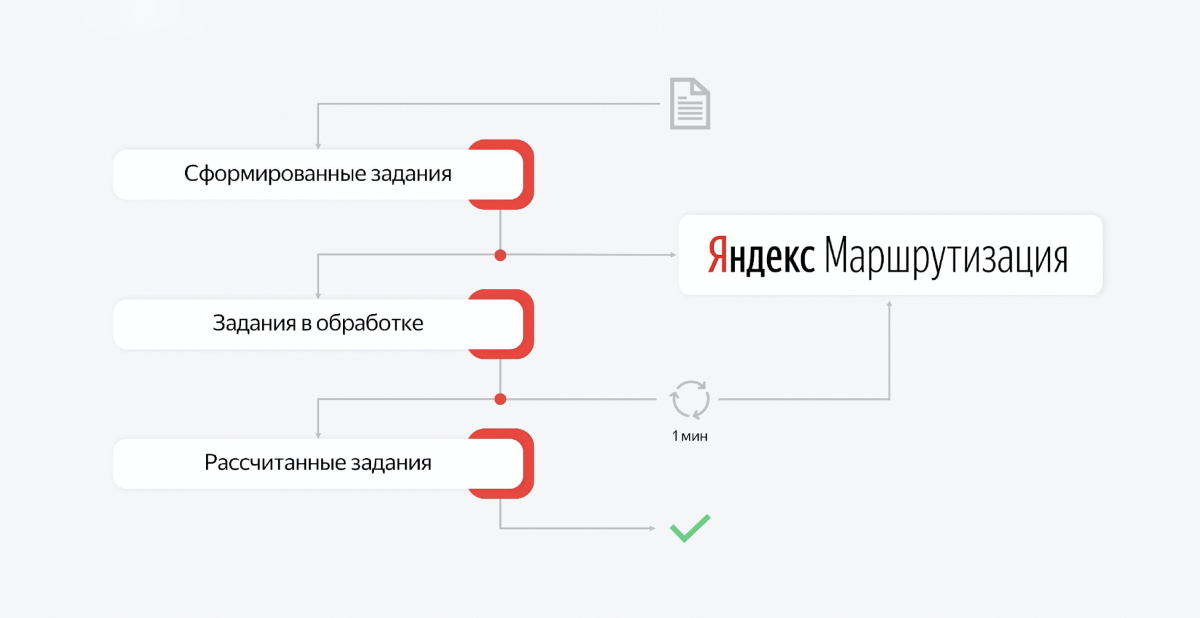
For example, the day is over, we want to calculate the routes for tomorrow. We send a request first of all: create a task and start the calculation. Consumer picks up the first message, goes to the routing service. This is an asynchronous API. The Consumer receives a response that the task has been taken to work.
He puts this ID in the base, and puts a new job in the queue with tasks in processing. And that's all. The message disappears from the first queue, the second consumer "wakes up". He takes the second task for processing, and his task is to regularly go to routing and check if this task has not yet been completed for the calculation.
The task of the level "create routes for 200 couriers who will deliver several thousand orders in Moscow" takes from half an hour to an hour. This is a very difficult task indeed. And the guys from this service are very cool, they solve the most complex algorithmic problem that takes a lot of time.
As a result, the consumer of the second queue will simply check, check, check. After some time, the task will be completed. When the task is completed, we receive an answer in the form of the required structure of tomorrow's routes and shifts for couriers.
We put what has been calculated in the third priority. The message disappears from the second queue. And the third consumer "wakes up", takes this context from the Yandex.Routing service and, on its basis, creates the state of tomorrow. He creates orders for couriers, he creates orders, creates shifts. This is also a lot of work. He spends some time on this. And when everything is created, this transaction ends and the job is removed from the queue.
If anything goes wrong anywhere in this process, the server will restart. Upon subsequent restoration, we will simply see the point at which we ended. Let's say the first phase and the second one have passed. And let's move on to the third.
With this architecture, in recent months, everything has been going pretty smoothly, there are no problems. But before there was a solid try-catch. It is not clear where the process failed, what statuses were changed in the database, and so on.
There are things you shouldn't skimp on. There are things with which you will save yourself a bunch of nerve cells if you do everything well right away.
What have we done offline
I have described most of what is happening on our platform. But something remained behind the scenes.
We learned about software that helps couriers deliver orders within a day. But someone should make these heaps for couriers. In a sorting center, people have to sort a large machine of orders into small piles. How it's done?
This is the second part of the platform. We wrote all the software ourselves. We now have terminals with which storekeepers read the code from the boxes and put them in the appropriate cells. There is rather complicated logic. This backend is not much simpler than the one I already talked about.
This second piece of the puzzle was necessary to allow, together with the first, to extend the process to other cities. Otherwise, we would have to look for a contractor in each new city who could arrange the exchange of some Excels by mail, or integrate with our API. And that would be a very long time.
When we have the first and second pieces of the puzzle, we can simply rent a building, hire couriers in cars. Tell them how to push, what to push, how to pick, which box to put where, and that's it. Thanks to this, we have already launched in seven cities, we have more than ten sorting centers.
And the opening of our platform in a new city takes very little time. Moreover, we have learned not only to deliver orders to specific people. We know how to deliver orders to pick-up points with the help of couriers. We also wrote software for them. And at these points we also issue orders to people.
Outcomes
In the beginning, I said why we started to create our own courier platform. Now I will tell you what we have achieved. It's incredible, but using our platform, we were able to get close to almost 100% hitting the interval. For example, over the last week the quality of delivery in Moscow was about 95–98%. This means that in 95–98% of cases we are not late. We fit into the interval chosen by the client. And we couldn't even dream of such precision when we relied solely on external delivery services. Therefore, we are now gradually expanding our platform to all regions. And we will improve deliverability.
We got unrealistic transparency. We also need this transparency. Everything is logged with us: all actions, the entire process of issuing an order. We have the opportunity to go back in history for five months and compare some metric with the current one.
But we also gave this transparency to the clients. They see a courier coming to them. They can interact with him. They do not need to call the support service, say: "Where is my courier?"
In addition, it turned out to optimize costs, because we have access to all elements of the chain. As a result, now it costs a quarter less to deliver one order than it was before when we worked with external services. Yes, the cost of order delivery has decreased by 25%.
And if you summarize all the ideas that were discussed, the following can be distinguished.
You must clearly understand at what stage of development your current service is, your current project. And if this is an established business, used by millions of people, used, perhaps in several countries, you cannot do everything at the same level as with Rover.
But if you have an experiment ... The experiment is different in that at any moment, if we do not show the promised results, we can be closed. It didn't take off. And that's okay.
And we were in this regime for about ten months. We had reporting intervals, every two months we had to show the result. And we did it.
In this mode, it seems to me that you have no right to do something by investing in long-term and not getting anything in the short run. It is impossible to lay such a strong foundation for the future in this format of work, because the future may simply not come.
And any competent developer, technical leader must constantly choose between doing on crutches or building a spaceship right away.
In short, try to keep it as simple as possible, while leaving room for expansion.
There is a first level when you need to do it quite simply. And there is the first level with an asterisk, when you keep it simple, but leave at least a little room for maneuver so that it can be expanded. With this mindset, it seems to me that the results will be much better.
And the last thing. I talked about Rover that it is good to do such processes using feature flags. I advise you to listen to the talk by Maria Kuznetsova from the Java meetup. She told how feature flags are arranged in our system and monitoring.