The campaign "to abolish Stallman", which began with the publication on Medium, provides us with a lot of interesting data. Since signing open letters for cancellation and support for Stallman is done on github, we can analyze some characteristics of both parties using statistics that are available through the API.
This is helped by the fact that on github it is difficult to edit data "retroactively" without losing new signatures.
The following assumptions can be tested ("X" can be either a proposal to cancel Stallman or an expression of his support):
Opponents of X are more often associated with large companies than supporters
X proponents commit code more often and more and are therefore more useful to the open source community.
Opponents of X are significantly less likely to commit to a repository with free licenses.
Opponents of X prefer Rust (or JS), proponents of C (or C ++, Python)
Opponents of X are more socially active, they have social accounts. networks, twitter, they often write.
Opponents of X do not commit code on weekends (only work during business hours, not enthusiasts)
Most of X's opponents were registered on github less than half a year ago
We have tried to test some of these assumptions and invite anyone interested to test the rest of the assumptions and contribute (and test) any others.
We have created a repository in which the work will take place. It also contains this article, its copy on Habré will be updated as pull requests are added. Join the research!
The details will follow.
A note on scientific honesty
Any hypotheses and any testable evidence will be accepted and added to the article. We do not consider it possible to hide data that contradicts our position. All interpretations will be added as well. We invite supporters of both positions to work together (yes, it is possible). Collaboration repository .
Stallman Cancellation Campaign Runs From One Center
23 Mar 2021 10:42:36 AM PDT, - 23 Mar 2021 01:23:39 PM PDT. , . , , ( ) .
$ cat get-stars.sh
#!/bin/bash
set -ue
page=1
owner_repo=$1
while true; do
curl -s -H "Authorization: token $GITHUB_OAUTH_" \\
-H "Accept: application/vnd.github.v3.star+json" \\
"<https://api.github.com/repos/$owner_repo/stargazers?per_page=100&page=$page>"| \\
jq -r .[].starred_at_ | grep . || break
((page++)) || true
done
$ echo "epoch,con" >con.stars.csv
$ ./get-stars.sh 'rms-open-letter/rms-open-letter.github.io'|while read a; do date -d $a +%s; done|sort -n|cat -n|awk '{print $2","$1}' >>con.stars.csv
$ echo "epoch,pro" >pro.stars.csv
$ ./get-stars.sh 'rms-support-letter/rms-support-letter.github.io'|while read a; do date -d $a +%s; done|sort -n|cat -n|awk '{print $2","$1}' >>pro.stars.csv
$ join -t, -e '' -o auto -a1 -a2 con.stars.csv pro.stars.csv >joined.stars.csv
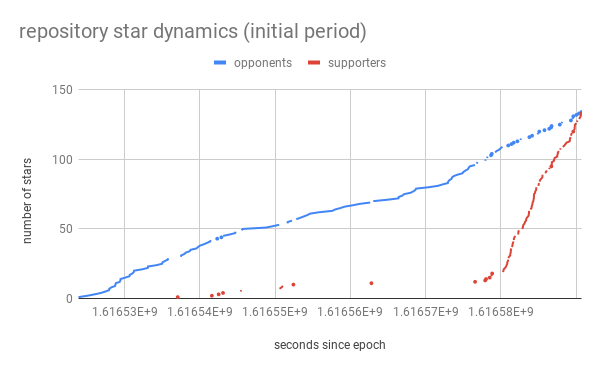
, . , , / .
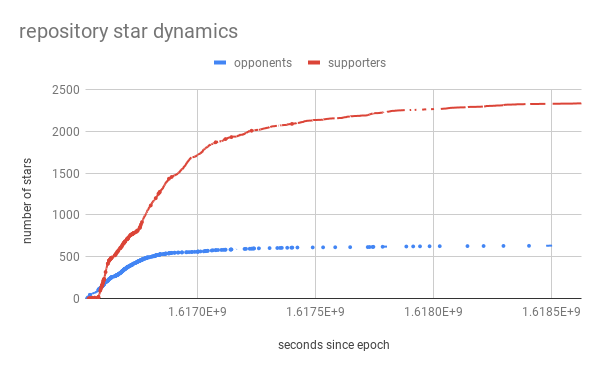
, -, . , - .
1345 5000+ . :
$ cat get-commits.py
#!/usr/bin/env python
import os
import requests
import json
import sys
repo = sys.argv[1]
headers = {'Authorization': 'token {}'.format(os.environ["GITHUB_OAUTH"])}
commits = []
page = 0
while page < 300:
page += 1
data = requests.get('https://api.github.com/repos/{}/commits?per_page=100&page={}'.format(repo, page), headers=headers).json()
if len(data) == 0:
break
commits += data
print(json.dumps(commits, indent=4))
$ ./get-commits.py 'rms-open-letter/rms-open-letter.github.io' >con.commits.json
$ ./get-commits.py 'rms-support-letter/rms-support-letter.github.io' >pro.commits.json
:
$ jq -r .[].commit.author.date pro.commits.json|sort -u|cat -n|awk '{print $2","$1}'|sed -e 's/T/ *' -e 's/Z/*' >pro.commits.csv
$ jq -r .[].commit.author.date con.commits.json|sort -u|cat -n|awk '{print $2","$1}'|sed -e 's/T/ *' -e 's/Z/*' >con.commits.csv
$ join -t, -e '' -o auto -a1 -a2 con.commits.csv pro.commits.csv >joined.commits.csv
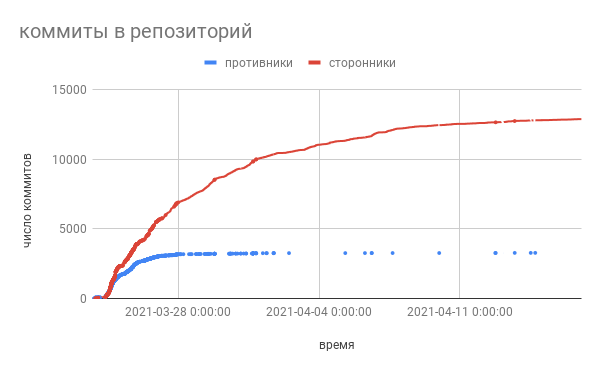
, . . .
.
$ jq -r .[].commit.author.date con.commits.json |./weekday-from-date.py >con.rms_commits.csv
$ jq -r .[].commit.author.date pro.commits.json |./weekday-from-date.py >pro.rms_commits.csv
$ join -t, con.rms_commits.csv pro.rms_commits.csv >joined.rms_commits.csv
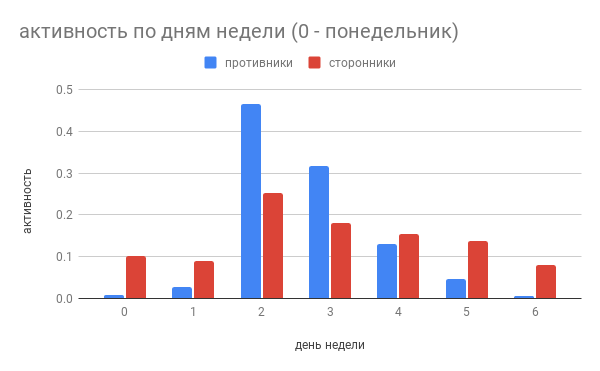
A , . , no meeting day.
.
, 100 :
$ jq -r .[].author.login con.commits.json|sort -u >con.logins
$ jq -r .[].author.login pro.commits.json|sort -u >pro.logins
$ cat get-user-events-data.sh
#!/bin/bash
set -ue
script_dir=$(dirname $(realpath $0))
get_data() {
local data_dir=$script_dir/$1 userdata events
for x in $(cat $1.logins); do
userdata=$data_dir/$x.userdata
[ -r $userdata ] && continue
curl -s -H "Authorization: token $GITHUB_OAUTH" "<https://api.github.com/users/$x>" >$userdata
sleep 1
events=$data_dir/$x.events
[ -r $events ] && continue
curl -s -H "Authorization: token $GITHUB_OAUTH" "<https://api.github.com/users/$x/events?per_page=100>" >$events
sleep 1
done
}
get_data $1
$ ./get-user-events-data.sh con
$ ./get-user-events-data.sh pro
, :
{
"login": "zyxw59",
"id": 3157093,
"node_id": "MDQ6VXNlcjMxNTcwOTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3157093?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zyxw59",
"html_url": "https://github.com/zyxw59",
"followers_url": "https://api.github.com/users/zyxw59/followers",
"following_url": "https://api.github.com/users/zyxw59/following{/other_user}",
"gists_url": "https://api.github.com/users/zyxw59/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zyxw59/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zyxw59/subscriptions",
"organizations_url": "https://api.github.com/users/zyxw59/orgs",
"repos_url": "https://api.github.com/users/zyxw59/repos",
"events_url": "https://api.github.com/users/zyxw59/events{/privacy}",
"received_events_url": "https://api.github.com/users/zyxw59/received_events",
"type": "User",
"site_admin": false,
"name": "Emily Crandall Fleischman",
"company": "Commure",
"blog": "",
"location": null,
"email": "emilycf@mit.edu",
"hireable": null,
"bio": null,
"twitter_username": null,
"public_repos": 24,
"public_gists": 0,
"followers": 2,
"following": 12,
"created_at": "2012-12-31T05:33:30Z",
"updated_at": "2021-03-14T01:53:51Z"
}
, twitter_username, company, bio blog:
|
|
|
|
twitter_username |
31% |
8% |
company |
48% |
20% |
bio |
53% |
31% |
blog |
63% |
31% |
. ( , , .
public_repos, public_gists, followers following:
|
|
|
|
||
|
|
|
|
|
|
public_repos |
62 |
34 |
21 |
9 |
public_gists |
18 |
4 |
4 |
0 |
followers |
105 |
23 |
16 |
2 |
following |
30 |
8 |
14 |
1 |
. followers, , . followers / following 3, 1.1.
events_url, .
Now let's take a look at the actions of the users. There is a lot of data downloaded and you can analyze it in many ways. You can check user activity by day of the week to see how this data correlates with activity specific to the pros and cons of Stallman.
The code
cat weekday-from-date.py
#!/usr/bin/env python
import datetime
import sys
out = [0] \* 7
total = 0
for line in sys.stdin.readlines():
weekday = datetime.datetime.strptime(line.strip(), '%Y-%m-%dT%H:%M:%SZ').weekday()
out[weekday] += 1
total += 1
for day, count in enumerate(out):
print("{},{}".format(day, count / total))
$ jq -r .[].created<sub>at</sub> con/\*.events|./weekday-from-date.py >con.event<sub>day.normalized.csv</sub>
$ jq -r .[].created<sub>at</sub> pro/\*.events|./weekday-from-date.py >pro.event<sub>day.normalized.csv</sub>
$ join -t, con.event<sub>day.normalized.csv</sub> pro.event<sub>day.normalized.csv</sub>
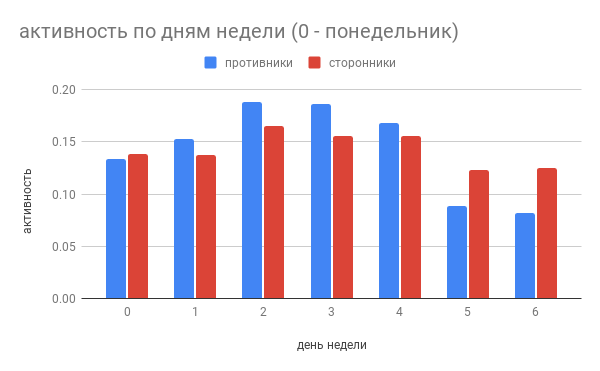
It can be seen that the trend has continued: the activity of opponents is sharply reduced on the weekend. It can be assumed that they use github at work and, possibly, work on open source projects for a salary. If this assumption is correct, their opinion may be due to the selection made by companies that hire programmers to work on open source projects.