
I am sure that most readers are at least a little familiar with the terms "Unicode" and "UTF-8". But does everyone know what exactly is behind them? In essence, they refer to character encoding standards, also known as character sets. The concept appeared in the days of the optical telegraph, and not in the computer age, as one might think. Back in the 18th century, there was a need for fast transmission of information over long distances, for which the so-called telegraph codes were used. The information was encoded using optical, electronic and other means.
In the hundreds of years that have passed since the invention of the first telegraph code, there has been no real attempt at international standardization of such coding schemes. Even the early decades of the teletype and home computer era changed little. While EBCDIC (IBM's 8-bit character encoding, shown on a punched card in the header illustration) and ASCII improved things a bit, there was still no way to encode a growing collection of characters without significant memory usage.
The development of Unicode began in the late 1980s, when the growth in the exchange of digital information around the world made the need for a single coding system more urgent. These days, Unicode allows us to use a single encoding scheme for everything from basic English text to Traditional Chinese, Vietnamese, even Mayan, to the pictograms we used to call emojis.
From code to graphs
Back in the days of the Roman Empire, it was well known that the speedy transmission of information matters. For a long time, this meant the presence of messengers on horseback who carried messages over long distances, or their equivalent. How to improve the information delivery system was invented back in the 4th century BC - this is how a water telegraph and a system of signal lights appeared. But it wasn't until the 18th century that data transmission over long distances really became effective.
We have already written about the optical telegraph, also called "semaphore", in an article on the history of optical communication. It consisted of a number of relay stations, each of which was equipped with a turn signal system used to display telegraphic code symbols. The Chappe brothers' system, which was used by the French troops between 1795 and 1850, was based on a wooden bar with two movable ends (levers), each of which could move to one of seven positions. Together with the four positions for the crossbar, the semaphore in theory could indicate 196 characters (4x7x7). In practice, the number was reduced to 92-94 positions.
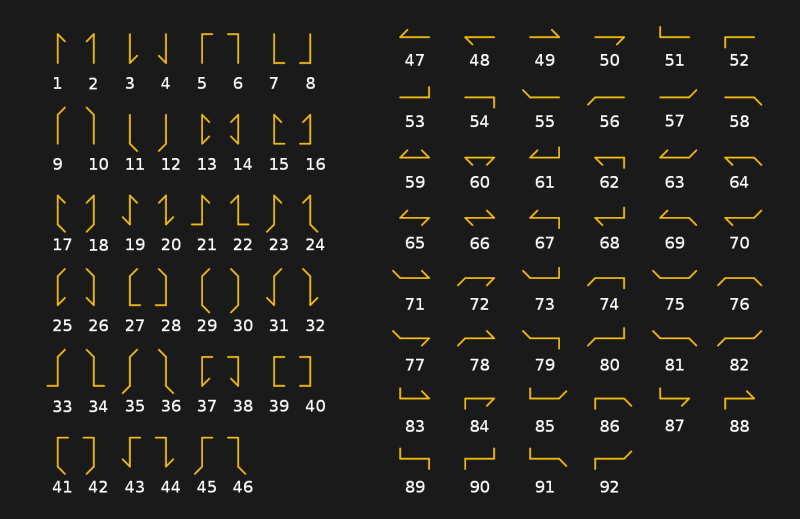
The semaphore system was used not so much to directly encode characters as to denote certain strings in a codebook. The method implied that it was possible to decipher the entire message using several code signals. This made the transmission faster and made it meaningless to intercept messages.
Performance improvement
Then the optical telegraph was replaced by an electrical one. This meant that the days when codings were captured by people watching the nearest relay tower were over. With two telegraph devices connected by a metal wire, electric current became the instrument for transmitting information. This change led to new electrical telegraph codes, and Morse code eventually became an international standard (with the exception of the United States, which continued to use American Morse code outside of radiotelegraphy) since its invention in Germany in 1848.
International Morse code has an advantage over its American counterpart: it uses more dashes than dots. This approach slows down the transmission speed but improves message reception at the other end of the line. This was necessary when long messages were transmitted over miles of wires by operators of different skill levels.
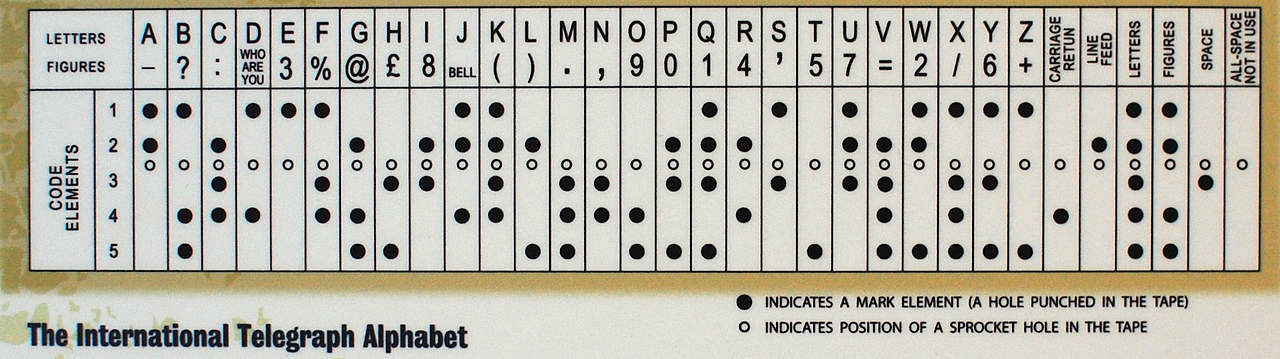
With the development of technology, the manual telegraph was replaced in the West by an automatic one. It used the 5-bit Baudot code, as well as the Murray code derived from it (the latter was based on the use of paper tape in which holes were punched). Murray's system made it possible to prepare a tape of messages in advance, and then load it into a reader for the message to be transmitted automatically. The Baudot code formed the basis for the International Telegraphic Alphabet Version 1 (ITA 1), and the modified Baudot-Murray code formed the basis for ITA 2, which was used until the 1960s.
By the 1960s, the 5-bit per character limit was no longer required, leading to the development of 7-bit ASCII in the United States and standards such as JIS X 0201 (for Japanese katakana characters) in Asia. In combination with teletypewriters, which were then widely used, this allowed the transmission of fairly complex messages, including upper and lower case characters.
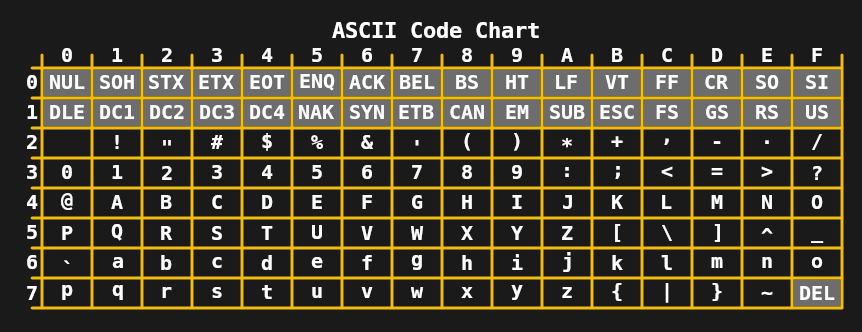
During the 1970s and early 1980s, the limitations of 7- and 8-bit encodings such as extended ASCII (such as ISO 8859-1 or Latin 1) were sufficient for mainstream home computers and office needs. Despite this, the need for improvement was clear, as common tasks such as exchanging digital documents and text often wreaked havoc with the many ISO 8859 encodings. The first step was taken in 1991 with 16-bit Unicode 1.0.
Development of 16-bit encodings
Surprisingly, in just 16 bits, Unicode managed to cover not only all Western writing systems, but also many Chinese characters and many special characters used, for example, in mathematics. With 16 bits allowing up to 65,536 code points, Unicode 1.0 easily accommodated 7,129 characters. But by the time Unicode 3.1 appeared in 2001, it contained at least 94,140 characters.
Now, in its 13th version, Unicode contains a total of 143,859 characters excluding control characters. Initially, Unicode was intended to be used only for encoding the notation systems that are currently in use. But by the 1996 release of Unicode 2.0, it became clear that this goal needed to be rethought to encode even rare and historical characters. To achieve this without the obligatory 32-bit encoding of each character, Unicode has changed: it allowed not only to encode characters directly, but also to use their components, or graphemes.
The concept is somewhat similar to vector images, where every pixel is not specified, but instead the elements that make up the picture are described. As a result, Unicode Transformation Format 8 (UTF-8) encoding supports 2 31 code point, with most characters in the current Unicode character set typically requiring one or two bytes.
Unicode for every taste and color
At this point, quite a few people are probably confused by the various terms that are used when it comes to Unicode. Therefore, it is important to note here that Unicode refers to the standard and the various Unicode Transformation Format are implementations of it. UCS-2 and USC-4 are older 2- and 4-byte implementations of Unicode, with UCS-4 being identical to UTF-32 and UCS-2 replacing UTF-16.
UCS-2, as the earliest form of Unicode, made its way into many operating systems in the 1990s, making the transition to UTF-16 the least dangerous option. This is why Windows and MacOS, window managers like KDE, and the Java and .NET runtimes use UTF-16 internally.
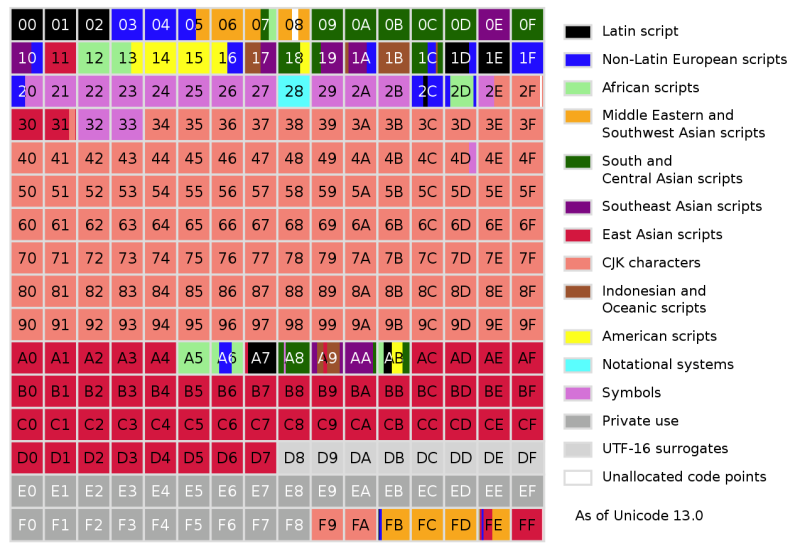
UTF-32, as the name suggests, encodes each character in four bytes. It's a bit wasteful, but completely predictable. The same UTF-8 character can encode a character in the range of one to four bytes. In the case of UTF-32, determining the number of characters in a string is simple arithmetic: take the entire number of bytes and divide by four. This has led to compilers and some languages, such as Python, that allow UTF-32 to represent Unicode strings.
However, of all Unicode formats, UTF-8 is by far the most popular. This has been largely facilitated by the worldwide Internet, where most websites serve their HTML documents in UTF-8 encoding. Because of the layout of the different planes of code points in UTF-8, Western and many other common writing systems fit within two bytes. Compared to the old ISO 8859 and Shift JIS encodings, in fact the same text in UTF-8 does not take up more space than before.
From optical towers to the Internet
The days of horse messengers, relay towers and small telegraph stations are over. Communication technology has evolved a lot. Even the days when teletypes were common in offices are hard to remember. However, at every stage in the development of history, mankind had a need to encode, store and transmit information. And this led us to the point where we can now instantly transmit a message around the world in a system of symbols that can be decoded no matter where you are.
For those who have happened to switch between ISO 8859 encodings in email clients and web browsers to get something that looks like the original text message, Unicode support has been a blessing. I can understand these people. When 7-bit ASCII (or EBCDIC) was the uncontested technology, sometimes you had to spend hours sorting out the symbolic confusion of a digital document received from a European or American office.
Even if Unicode is not without its problems, it's hard not to feel grateful comparing it to what it used to be. Here they are, 30 years of Unicode.
