
Very often, the use of ready-made tools in the development becomes a sub-optimal solution. So it happened with us. To manage data pipelines, we decided to develop our own system - Wombat. We will tell you what came of it, and what the refusal to use the ready-made solution gave us.
Why we are developing our own system
Making your own data pipeline management system is not an obvious choice. Today there are many ready-made solutions that can solve the problem: Airflow, MLflow, Kubeflow, Luigi and a bunch of others. We have experimented with many of these systems and have come to the conclusion that none of them suits us.
For example, consider the most common solution - Airflow. It combines six main blocks: an API for describing pipelines, a wokflow collector, a control panel and interfaces, a task scheduler and task orchestrator, and, finally, monitoring Airflow components. But in order to manage pipelines, this functionality was not enough in our case.
For us, such features as integration of the pipeline management system with the build system and CI, integration with Kubernetes, the ability to manage artifacts and data validation were critical.

We figured out what it would cost us to increase the functionality of the finished system to the required level and realized that it would be much easier and faster to develop our own system. We called it Wombat - because the animal is very cute, and secondly, because it is considered the savior of Australian nature. And for us, a system that would allow us to combine development and all stages of working with data would also be a real salvation.
What problems did we solve
Historically, in our development team, DevOps engineers support services in production. And they are used to working with pipelines, which are described not by code, but by configs in formats like yaml. Because of this discrepancy, you either have to share support or train engineers to work with a non-classical continuous integration system.
All of this would be redundant and unnecessary work, because pipelines in the form of directed acyclic graphs are perfectly described in the format that is used in standard CI and DevOps tools.

The second problem we faced was the storage and versioning of artifacts. Working with artifacts in the data pipeline management system allows you to get two very useful opportunities: reuse the results of working with pipelines and reproduce experiments with data, saving time for organizing new experiments.
If the organization of storing artifacts is not automated, then sooner or later new artifacts will begin to overwrite old ones, or free space will start running out on production machines. In addition, the production will need to apply special requirements to ensure the reliability and fault tolerance of the storage, which is another costly process.
Therefore, we wanted to get a solution that would perform all tasks related to managing pipelines in the background, while allowing data specialists to work with artifacts from other projects, and at the same time not think about the cost of data storage.
The third problem is the typing of data streams. Yes, Python allows you to develop prototypes and test various hypotheses at high speed. But when working with data, you have to pay attention to the types you are working with if you don't want unexpected surprises. To reduce the number of such problems in production, we need support for describing data schemas, right down to describing data-frame schemas, and data typing should be done separately for development and for production.
What happened in the end
Conventionally, the Wombat architecture can be represented like this:

This diagram shows the role of the system. It is an intermediate layer between the description of pipelines and the CI system, with the help of which you can work with them in production.
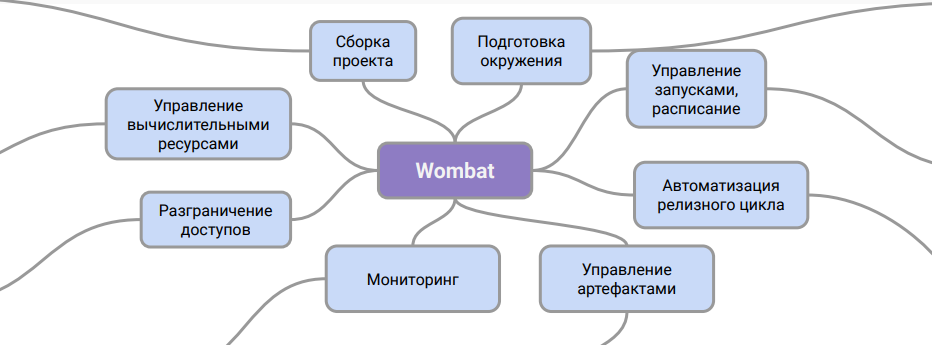
Thanks to this scheme of work, we can organize support for pipelines in the DevOps department without additional training for engineers and without involving data specialists in this process. In addition, the problem with the storage of data artifacts and their versioning is solved.
Now we are developing functionality that will allow introducing the tool into the early stage of prototyping and experimentation in a form native to data Scientists, which will significantly speed up the launch of projects into pilot and production.
We are preparing to release this tool in open source in the very near future. We will be glad if you shared your opinion about our project and your experience of working with modern data pipeline systems.
Also, realizing that this article is more informational than technical, in the near future we plan to prepare a more detailed, hardcore text. Write in the comments what you would like to see and find out in technical terms. We will take into account, describe and write. Thanks for attention!
PS We are still interested in talented programmers. Come, it will be interesting !