It is usually not customary to talk about such errors, because only sinless, heavenly people work in all integrators. As you know, at the DNA level, there is no possibility of being wrong or being wrong.
But I will risk it. I hope my experience will be useful to someone. We have one major customer, online retail, for whom we fully support the Cisco ACI factory. The company does not have its own administrator competent for this system. A network fabric is a group of switches that have a single control center. Plus, there are a bunch of useful features that the manufacturer is very proud of, but in the end, in order to drop everything, you need one admin, not dozens. And one control center, not dozens of consoles.
The story begins like this: the customer wants to transfer the core of the entire network to this group of switches. This decision is due to the fact that the ACI architecture, in which this group of switches is "assembled", is very fault-tolerant. Although this is not typical and in general, a factory in any data center is not used as a transit network for other networks and only serves to connect the end load (stub network). But such an approach is quite possible, so the customer wants - we do it.
Then a banal thing happened - I confused two buttons: deleting the policy and deleting the config of a fragment of the network:
Well, then, according to the classics, it was necessary to reassemble part of the collapsed network.
In order
The customer's request was as follows: it was necessary to build separate port groups for the transfer of equipment directly to this factory.
Colleagues, please transfer the settings of ports Leaf 1-1 101 and leaf 1-2 102, ports 43 and 44, to Leaf 1-3 103 and leaf 1-4 104, ports 43 and 44. To ports 43 and 44 on Leaf 1- 1 and 1-2, the 3650 stack is connected, it has not yet been put into operation, you can transfer port settings at any time.
That is, they wanted to transfer the server cluster. It was necessary to configure a new virtual port group for the server environment. In fact, this is a routine task; there is usually no service downtime for such a task. In essence, a port-group in APIC terminology is a VPC that is assembled from ports that are physically located on different switches.
The problem is that in the factory, the settings of these port groups are tied to a separate entity (which arises due to the fact that the factory is controlled from the controller). This object is called a port policy. That is, to the group of ports that we add, we also need to apply a general policy from above as an entity that will manage these ports.
That is, it was necessary to analyze which EPGs are used on ports 43 and 44 on nodes 101 and 102 in order to assemble a similar configuration on nodes 103-104. After analyzing the necessary changes, I began to configure nodes 103-104. To configure a new VPC in the existing interface policy for nodes 103 and 104, it was necessary to create a policy in which interfaces 43 and 44 would be brought in.
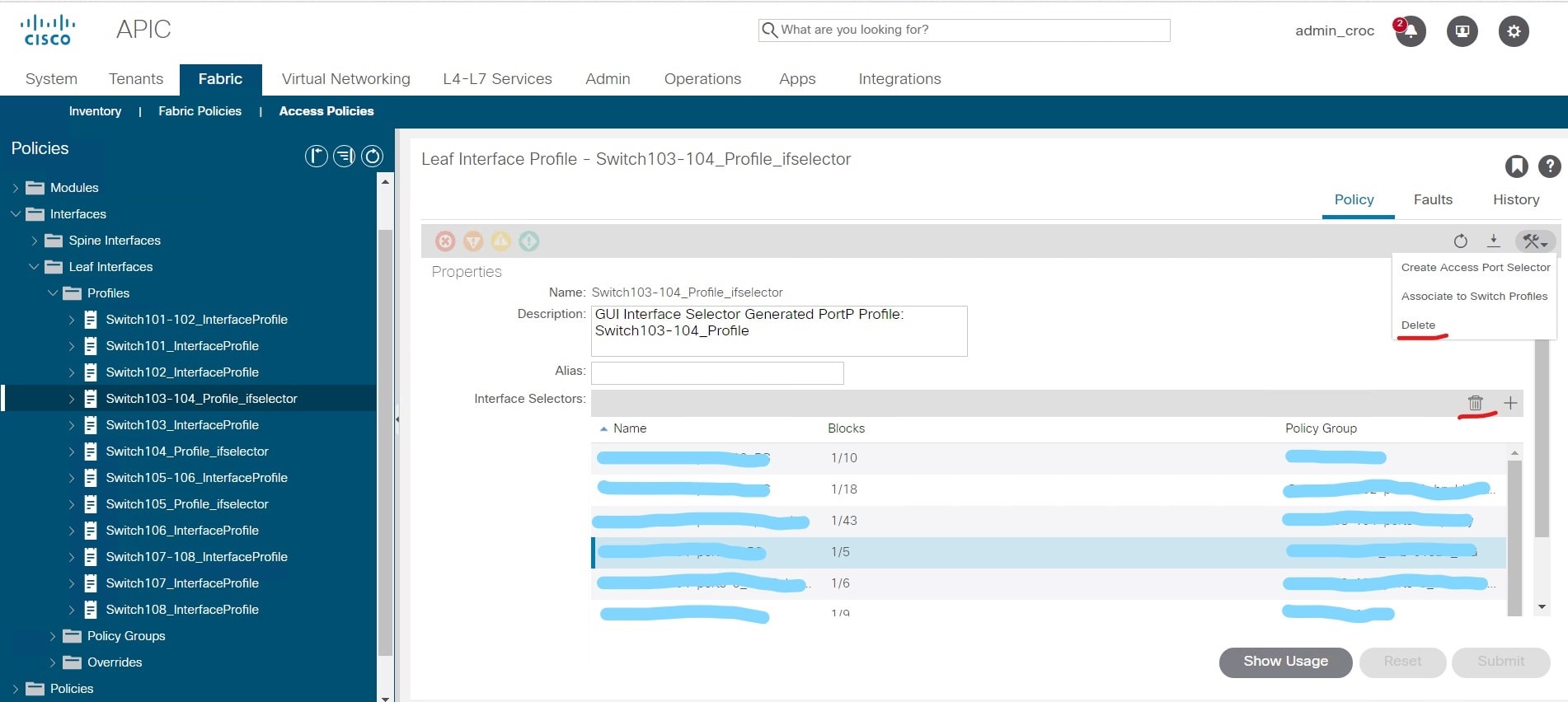
And there is one nuance in the GUI. I created this policy and realized that during the configuration process I made a minor mistake - I called it differently from the customer's custom. This is not critical - because the policy is new and does not affect anything. And I had to delete this policy, since changes can no longer be made to it (the name does not change) - you can only delete and re-create the policy.
The problem is that the GUI has delete icons that refer to interface policies, and there are icons that refer to switch policies. Visually, they are almost identical. And instead of deleting the policy I created, I deleted all the configuration for the interfaces on switches 103-104:
Instead of deleting one group, I actually deleted all VPCs from the node settings, used delete instead of trashbin.
These links had business-sensitive VLANs. In fact, after deleting the config, I disabled part of the grid. Moreover, this was not immediately noticeable, because the factory is not controlled through the kernel, but it has a separate management interface. I was not thrown out right away, there was no error in the factory because the action was taken by the administrator. And the interface thinks - well, if you said to delete, then it should be so. There was no indication of errors. The software decided that there was some kind of reconfiguration. If the admin deletes the leaf profile, then for the factory it ceases to exist and it does not write an error stating that it does not work. It doesn't work - because it was deliberately removed. It shouldn't work for software.
So the software decided that I was Chuck Norris and knew exactly what I was doing. Everything's under control. The admin cannot be wrong, and even when he shoots himself in the foot, this is part of a cunning plan.
But after about ten minutes I was kicked out of the VPN, which I initially did not associate with the APIC configuration. But this is at least suspicious, and I contacted the customer to clarify what was happening. And for the next few minutes, I thought that the problem was technical work, a sudden excavator or a power failure, but not the factory config.
The customer's network is complex. We see only part of the environment by our access. When restoring events, everything looks like the traffic rebalancing has begun, after which, after a few seconds, the dynamic routing of the remaining systems simply did not take out.
The VPN I was on was the admin VPN. Ordinary employees sat on the other, everything continued to work for them.
In general, it took a couple more minutes of negotiations to understand that the problem is still in my config. The first action in battle in such a situation is to rollback to the previous configs, and only then read the logs, because this is prod.
Factory restoration
It took 30 minutes to restore the factory - including all the calls and collecting all those involved.
We found another VPN that you can go through (this required an agreement with the security guards), and I rolled back the factory configuration - in Cisco ACI, this is done in two clicks. There is nothing complicated. The restore point is simply selected. It takes 10-15 seconds. That is, the recovery itself took 15 seconds. The rest of the time was spent figuring out how to get remote control.
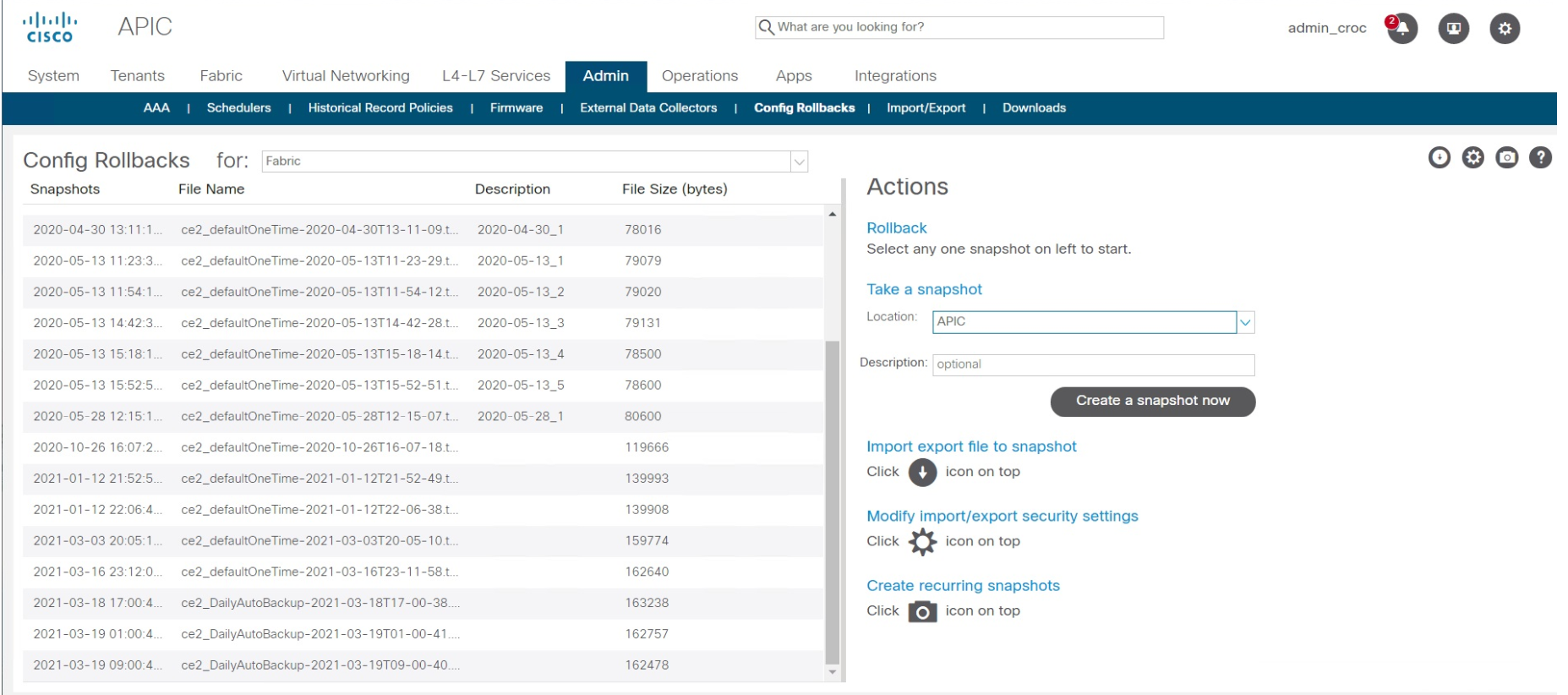
After the incident
Another day we parsed the logs and restored the chain of events. Then they assembled a call with the customer, calmly stated the essence and causes of the incident, proposed a number of measures to minimize the risks of such situations and the human factor.
We agreed that we only touch the configs of the factory during non-working hours: at night and in the evening. We carry out work with a duplicate remote connection (there are working VPN-channels, there are backup ones). The customer receives a warning from us and at this time monitors the services.
The engineer (that is, me) remained the same on the project. I can say that the feeling of trust in me has become even greater than before the incident - I think, precisely because we quickly worked in the situation and did not allow a wave of panic to cover the customer. The main thing is that they did not try to hide the joint. From practice, I know that in this situation it is easiest to try to switch to the vendor.
We applied similar networking policies to other outsourced customers: it’s harder for customers (additional VPN channels, additional admin changes during off-hours), but many understood why this was necessary.
We also dug deeper into the Cisco Network Assurance Engine (NAE) software, where we found the opportunity to do two simple, but very important things at the ACI factory:
- first, the NAE allows us to analyze the planned change, even before we rolled it out to the factory and shot everything for ourselves, predicting how the change will positively or negatively affect the existing configuration;
- second, the NAE, after the change, allows you to measure the overall temperature of the factory and see how this change ultimately affected its health.
If you are interested in more details - tomorrow we will have a webinar about the internal kitchen of technical support, we will tell you how everything works with us and with vendors. We will also analyze errors)