I've never had to deal with parsing data from the internet before. Usually, all data for work (data analyst) comes from the company's unloadings using a simple internal interface, or is formed by sql-queries to tables directly from the storage, if you need something more complex than “look at the revenue for the previous month”.
Therefore, I wanted to master some simple tool for parsing html pages in order to be able to collect data from the Internet using code in a convenient IDE without involving third-party tools.
The sites for collecting data were selected on the principle “there is no parser blocker” and “something interesting may come out of the analysis of this data”. Therefore, the choice fell on the assortment of dishes for the delivery of three restaurants in St. Petersburg - "Tokyo City", "Eurasia" and "2 Berega". They have approximately the same cuisine focus and a similar assortment, so there is clearly something to compare.
I will share the parser itself for one of the restaurants.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
print(" : " + str(datetime.datetime.now()))
#
urllist = ['https://www.tokyo-city.ru/spisok-product/goryachie-blyuda1.html',
'https://www.tokyo-city.ru/spisok-product/sushi.html',
'https://www.tokyo-city.ru/spisok-product/rolly.html',
'https://www.tokyo-city.ru/spisok-product/nabory.html',
'https://www.tokyo-city.ru/spisok-product/new_lunches.html',
'https://www.tokyo-city.ru/spisok-product/pitctca.html',
'https://www.tokyo-city.ru/spisok-product/salaty.html',
'https://www.tokyo-city.ru/spisok-product/-supy-.html',
'https://www.tokyo-city.ru/spisok-product/goryachie-zakuski1.html',
'https://www.tokyo-city.ru/spisok-product/wok.html',
'https://www.tokyo-city.ru/spisok-product/pasta.html',
'https://www.tokyo-city.ru/spisok-product/gamburgery-i-shaverma.html',
'https://www.tokyo-city.ru/spisok-product/Tokio-FIT.html',
'https://www.tokyo-city.ru/spisok-product/deserty.html',
'https://www.tokyo-city.ru/spisok-product/childrensmenu.html',
'https://www.tokyo-city.ru/spisok-product/napitki1.html',
'https://www.tokyo-city.ru/new/',
'https://www.tokyo-city.ru/spisok-product/postnoe-menyu.html',
'https://www.tokyo-city.ru/hit/',
'https://www.tokyo-city.ru/vegetarian/',
'https://www.tokyo-city.ru/hot/',
'https://www.tokyo-city.ru/offers/',
'https://www.tokyo-city.ru/spisok-product/sauces.html',
'https://www.tokyo-city.ru/spisok-product/Pirogi-torty.html']
#
names_all = []
descriptions_all = []
prices_all = []
categories_all = []
url_all = []
weight_all = []
nutr_all = []
#
for url in urllist:
response = requests.get(url).text
soup = BeautifulSoup(response, features="html.parser")
items = soup.find_all('a', class_='item__name')
itemsURL = []
n = 0
for n, i in enumerate(items, start=n):
itemnotfullURL = i.get('href')
itemURL = 'https://www.tokyo-city.ru' + itemnotfullURL
itemsURL.extend({itemURL})
m = 0
namesList = []
descriptionsList = []
pricesList = []
weightList = []
nutrList = []
itemResponse = requests.get(itemURL).text
itemsSoup = BeautifulSoup(itemResponse, features="html.parser")
itemsInfo = itemsSoup.find_all('div', class_='item__full-info')
for m, u in enumerate(itemsInfo, start=m):
if (u.find('h1', class_='item__name') == None):
itemName = 'No data'
else:
itemName = u.find('h1', class_='item__name').text.strip()
if (u.find('p', class_='item__desc') == None):
itemDescription = 'No data'
else:
itemDescription = u.find('p', class_='item__desc').text.strip()
if (u.find('span', class_='item__price-value') == None):
itemPrice = '0'
else:
itemPrice = u.find('span', class_='item__price-value').text
if (u.find('div', class_='nutr-value') == None):
itemNutr = 'No data'
else:
itemNutr = u.find('div', class_='nutr-value').text.strip()
if (u.find('div', class_='item__weight') == None):
itemWeight = '0'
else:
itemWeight = u.find('div', class_='item__weight').text.strip()
namesList.extend({itemName})
descriptionsList.extend({itemDescription})
pricesList.extend({itemPrice})
weightList.extend({itemWeight})
nutrList.extend({itemNutr})
df = pd.DataFrame((
{'Name': namesList,
'Description': descriptionsList,
'Price': pricesList,
'Weight': weightList,
'NutrInfo': nutrList
}))
names_all.extend(df['Name'])
descriptions_all.extend(df['Description'])
prices_all.extend(df['Price'])
weight_all.extend(df['Weight'])
nutr_all.extend(df['NutrInfo'])
df['Category'] = soup.find('div', class_='title__container').text.strip()
categories_all.extend(df['Category'])
result = pd.DataFrame((
{'Name': names_all,
'Description': descriptions_all,
'Price': prices_all,
'Category': categories_all,
'NutrInfo': nutr_all,
'Weight': weight_all,
}))
print(" : " + str(datetime.datetime.now()))
- / . , . , , , - - .
- .
:
, , , , , , .
:
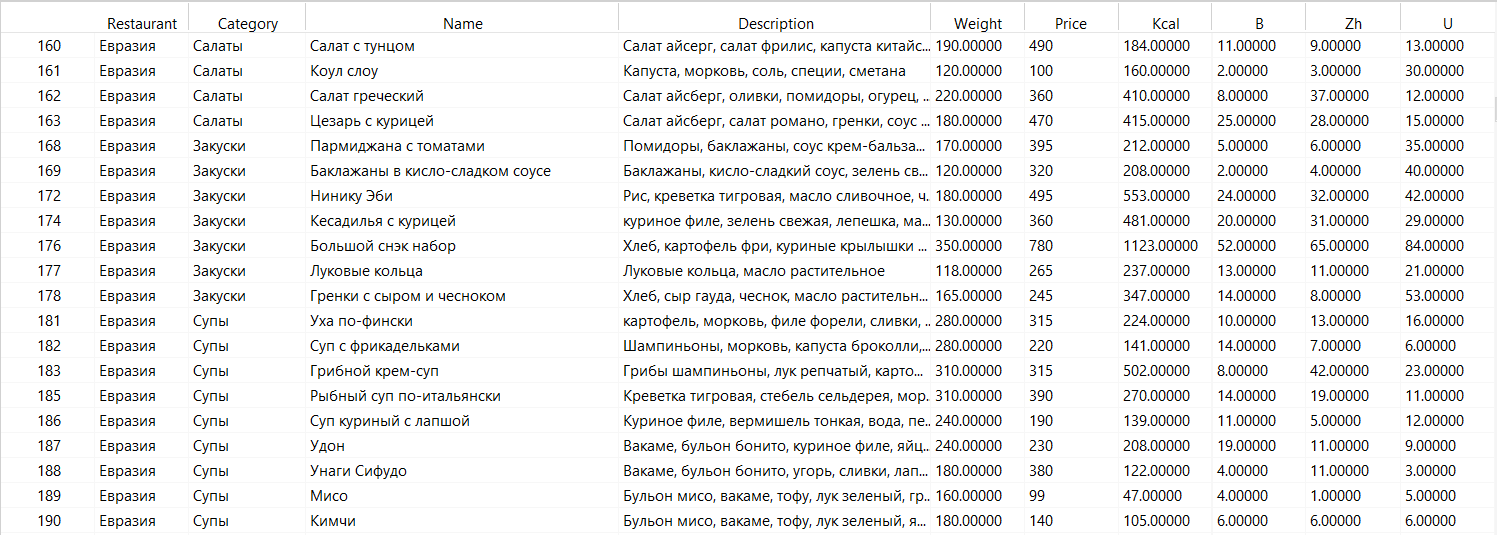
. , . , , , , .
City
“ City” 19 5 , , (, ). - 351.

“” - 13 , 301 . , “ City” , 40% , , , “”.

2
- 241 15 .

, , , .
№1: ?
, “” .
, , , . , “”, “ ”, “”, “”, “” “” + .
:

, “2 ” - №1 . , “” (“ City” - 20, “” - 17 “2 ” - 51).
- , “” .
№2: ?
, - “”, “” “ ”. . , , “ ”, .
100 , :

“2 ” , “ ”. , “ + ” . “ ” “ City” “”.
“ City” . “2 ” 2 . “” . 100 “” 30% ( , ), “ City” .
, :

“” . “” 30% .
“2 ” , . , “ ” , , 2 + ( ). .
“ City” .
№3: ?
, , . , .

“ City” 205 100 , . , . “2 ” 35% , . , , , .
: ?
, , , , .

Despite the highest calorie content per 100 grams and a large amount of fast food, “2 Shores” offers a fairly balanced menu, while the same “Tokyo City” has a clear bias towards carbohydrates.
BJU "Eurasia" is somehow too uniform, practically without emissions, therefore it raises suspicions.
In general, there are doubts about the correctness of the conclusions I made in this particular question - perhaps, for the correct answer to the question, these indicators need to be assessed somehow differently.
Here is such a small, but curious, in my opinion, research came from the random thought “to parse something”.