
We use the approach described in the previous article to manage code for Spark applications .
It is about managing the quality of the code when developing Spark ETL, so as not to turn the work on the project into a flight of the soul, frightening even the author. As a result, the Spark ETL application looks just like a sequence of Spark SQL queries. The ETL transformation itself is described as an object in a separate configuration file.
What are the advantages of this approach?
- It has great flexibility. Actually, the application code does not depend on the transformation logic and can be easily added or even written from scratch on a new project. For example, if you need to parse JSON or XML.
- The important thing is that the code remains easy for a new person in the team to learn, no matter how complex transformations are encountered in the project. Only the number and size of configuration files describing individual transformations is growing.
- To expand the project, you can hire people who know only SQL.
However, this approach also has disadvantages, which are a consequence of the fact that it is not a full-fledged tool, but rather an internal development regulation. As a result, not much of what we would like. And I would like the following:
- Create autotests
- Maintain templating
- Create project documentation
- Validate a Model Describing a Transformation
- And the main thing is that a number of obvious things, such as showcases of various save formats and support for full, partial and incremental loading, are supported out of the box.
As it turned out, such a tool already exists and this application is based on similar principles, providing the ability to describe ETL transformation as a set of SQL queries and execute them on Spark - Data Build Tool (DBT) The
application is mentioned as an obvious tool for ETL to use. Moreover, you can verify this by looking at how this tool is promoted by Databriks or here by reading the article .
I myself really liked this material: DBT (Data Build Tool) Tutorial from Fishtown Analytics
DBT offers to conduct an ETL transformation project in the form of a hierarchy of SQL queries, supports a templating engine, checks the validity of query references to each other, generates autotests and documentation. In addition, it supports various query execution environments, is able to create a dependency graph of project tasks. It is distributed free of charge, but it also contains paid versions with support for the development environment, and is also supported by many other tools: for example, there are many materials on the Dagster - DBT bundle.
How does DBT manage the task, according to those who have had to solve the same problems on their own?
The most interesting, as always, is hidden in the details, so it is interesting to see them.
Great, let's try this app. What does the product offer?
- Spark. . DBT , , Spark. Spark : Thrift Server ;
- SQL . DBT – SQL , , – DBT, ;
- . : , , ;
- . DBT , ;
- . DBT Ninja Template ;
- DBT addhook-, , id ;
- DBT , , .
In general, there is everything that one way or another met in such projects and that had to be added to our own developments.
The only thing I had to tinker with, and it turned out to be unexpected, was connecting to Spark. DBT offers various options for executing requests. We are only interested in Spark for connecting to which there are also different options. Since we are talking about our own clusters running Cloudera, we are left with the Spark Thrift server option. And then suddenly it turns out that Cloudera includes Spark in the distribution without a Thrift server.
It turns out that they think you need Impala, so they diligently build a Spark distribution without Thrift and happily include it in the cluster distribution.
Who is to blame is clear. What to do?
Download the required Spark distribution kit, install it on the cluster node. Specify in the settings a link to / etc / hadoop / conf. We launch Spark Thrift Server from the distribution kit, after which we specify the host-port of our Thrift server in the DBT settings.
Maybe someone knows another way? I did not find. OK. We create a test project. Configuring a DBT Profile:

In a project, a model that accesses queries from one of the Hive tables to verify that the settings have been read.
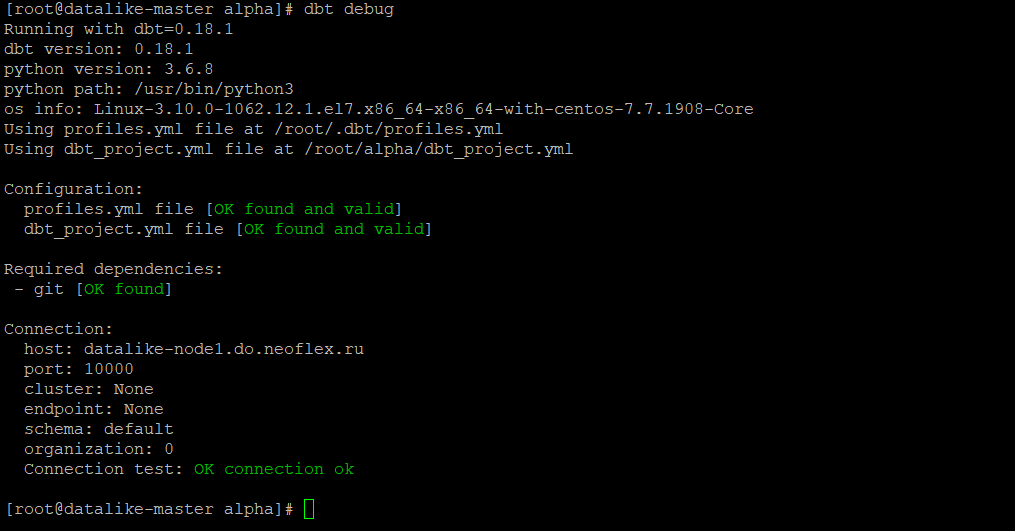
First, we check that the DBT sees Spark.
DBT debug
Now we check the test model, which makes a Spark request to Hive:

Connected, requests pass, everything is fine.