Inspector and even somewhere "interpreter", LIT or Language Interpretability Tool is a powerful open source platform for visualizing and interpreting NLP models. The platform was presented at EMNLP 2020 by Google Research in November 2020. LIT is still in development status, so the developers do not guarantee anything, including work on the windows platform. But I did it, I share my experience.
LIT is an interactive, extensible, visual tool for developers and researchers of NLP models who, among other things, want to understand which cases the model does not cope with, why the forecast is exactly the same, which words in the text affect the result, and what will happen if one or a different token, or even the entire text. LIT is an open platform. You can add your own calculation of metrics, new methods of interpretation or custom visualization tools. It is important that the architecture of the model allows you to pull out the information you need.
The platform handles various kinds of models and frameworks, including TensorFlow 1.x, TensorFlow 2.x, PyTorch. LIT can run custom Python code on top of a neural network and even RPC models .
Two words about architecture. The frontend is based on TypeScript. It is a single page application made up of independent web components. The backend is based on a WSGI server. The backend manages models, datasets, metrics, generators and interpretation components, as well as a cache that speeds up model and data manipulation, which is very important for large models. More details here .
Out of the box, LIT supports classification, regression, text generators including seq2seq, masked models, NER models, and multifunction models with multiple output heads. Key features in the table:
Widget |
Short description |
Attention |
Visualization of the attention mechanism by attention layers and attention heads in combination. |
Confusion Matrix |
, , . |
Counterfactual Generator |
. |
Data Table |
. — 10k . |
Datapoint Editor |
. . |
Embeddings |
3D : UMAP PCA. . Data Table . , , , . |
Metrics Table |
— Accuracy Recall BLEU ROUGE. , . |
Predictions |
. . |
Salience Maps |
. . — local gradients, LIME. |
Scalar Plot |
2D . |
Slice Editor |
. |
— pip install .
pip Windows 10 GPU:
# :
conda create -n nlp python==3.7
conda activate nlp
# tensorflow-gpu pytorch:
conda install -c anaconda tensorflow-gpu
conda install -c pytorch pytorch
# pip tensorflow datasets, transformers LIT:
pip install transformers=2.11.0
pip install tfds-nightly
pip install lit-nlp
tensorflow datasets glue datasets, tfds . PyTorch , .
. 5432, PostgreSQL. netstat -ao. :
python -m lit_nlp.examples.quickstart_sst_demo —port=5433.
< >\anaconda3\envs\nlp\Lib\site-packages\lit_nlp\examples , quickstart_sst_demo windows. , , 5 GPU 20 CPU. ASCII- LIT .

http://127.0.0.1:5433/ , .
.
git clone https://github.com/PAIR-code/lit.git ~/lit
#
cd ~/lit
conda env create -f environment.yml
conda activate lit-nlp
conda install cudnn cupti # , GPU
conda install -c pytorch pytorch
#
pushd lit_nlp; yarn && yarn build; popd
continuumio/anaconda3 WSL2. . environment.yml tensorflow-datasets tfds-nightly. gcc g++. yarn. yarn apt-get, yarn! — :
curl https://deb.nodesource.com/setup_12.x | bash
curl https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add -
echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list
apt-get update && apt-get install -y nodejs yarn postgresql-client
yarn && yarn build
NLP , , . «» LIT , quickstart_sst_demo, - .
:
Lenta.Ru, Kaggle. : , , . 70 150. 50k .
:
, BERT. . RuBert DeepPavlov , huggingface.co. 180 . . , 8 GPU. , . , max_seq_length, 128 , 64 .
LIT :
, , datasets/lenta.py, models/lenta_models.py examples/quickstart_lenta.py . — quickstart_sst_demo. . EDIT.
datasets/lenta.py: tfds, , .
models/lenta_models.py: «DeepPavlov/rubert-base-cased» : max_seq_length 64 , — 32 16.
examples/quickstart_lenta.py: , .
:
python -m lit_nlp.examples.quickstart_lenta —port=5433
RuBert – . . lenta_models num_epochs ( train). , . 50k 3000 . RTX2070 25 .
:

.
. , .

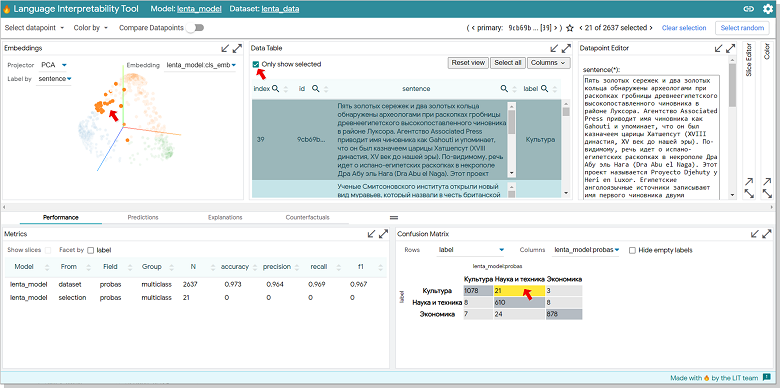
, 21 , , , .
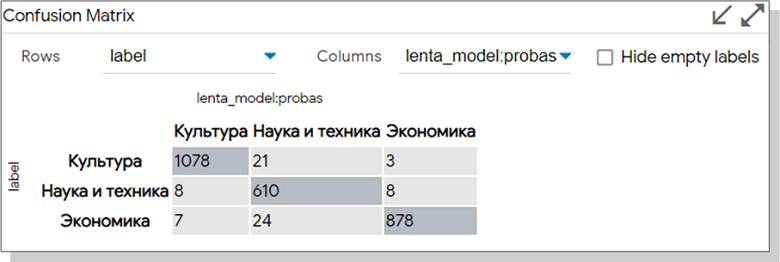
. Data Table «Only show selected». Embedding.
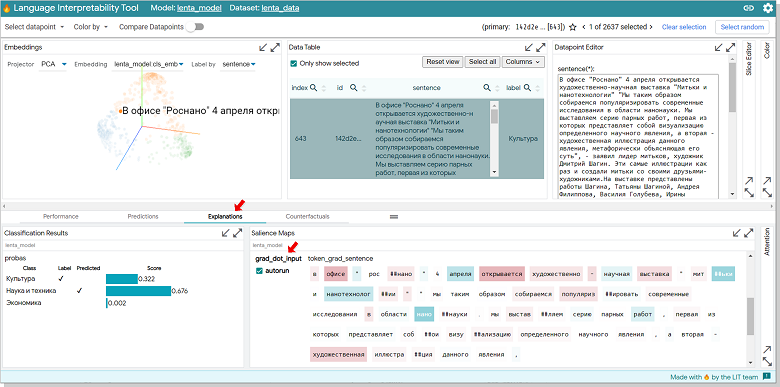
Data Table - Explanation. . 32% , 68, . Silence Maps grad_dot_input. , " " , — .
.
Datapoint Editor «-» , «Analyze new datapoint» ( ).
:

:

Scalar. , Y. , , ROUGE. .
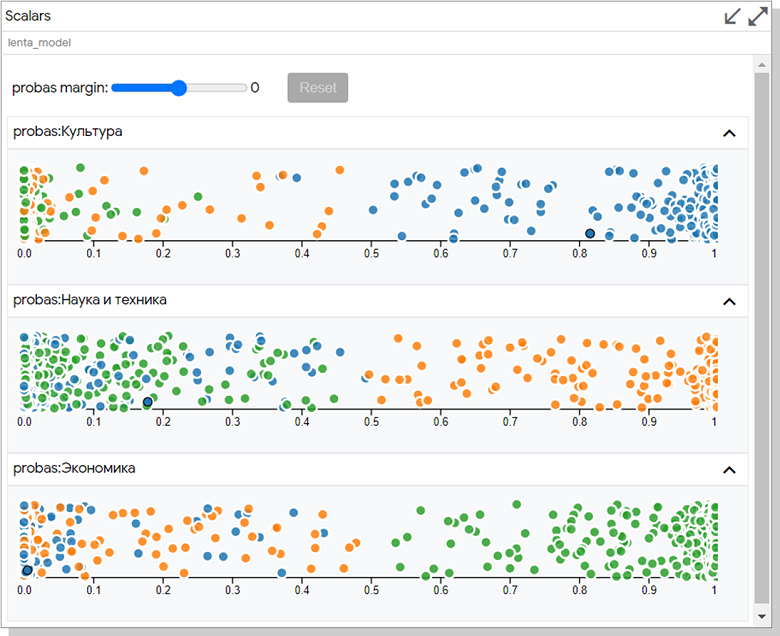
:
RuBert LIT , . , . . Slinece Maps Embeddings , - .
LIT, . , . :
BERT fills in gaps in text
Generating text on T5
The ability to estimate the likelihood of tokens and see alternatives when generating text in the last example looks very useful. I haven't tried such a model locally yet, but I can't help but share a screenshot from the demo:
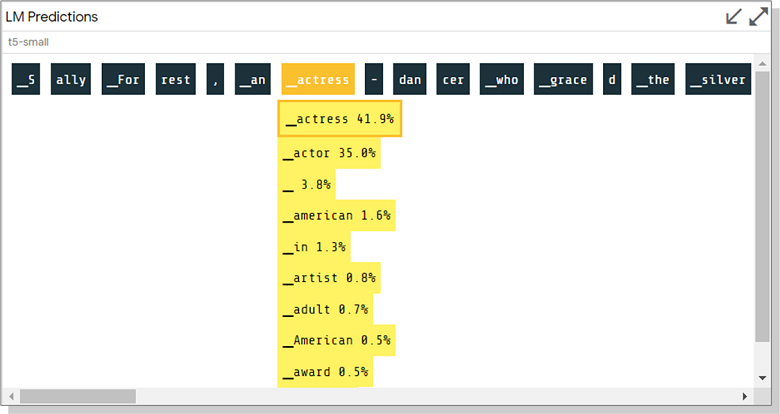
I sincerely wish you all interesting experiments with LIT and some patience in the process!
Links
Publication of The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models for EMNLP 2020
Forum on github with discussion of problems and errors in LIT