The technological infrastructure of M.Video-Eldorado Group today is much more than a gigantic chain of cash registers in more than 1000 stores across the country. Under the hood, we have an online platform that provides customer interaction, machine learning, smart search algorithms, chat bots, a recommendation system, automation of key business processes and electronic document flow. Under the cut, there is a detailed story about what pushed us towards breaking the monolith into microservices.
Legends of deep antiquity
In order for all this to work like clockwork, we need to follow the development of technologies and promptly respond to business requests. Unfortunately, the basic functionality of global ERP systems is far from always capable of responding quickly to the emerging needs of internal customers. In 2016, this became one of the arguments in favor of our transition to a microservice architecture.
The company was faced with a rather difficult task, to implement a unified business logic of working with various promotional mechanics in the process of placing orders by customers in all sales channels and points of contact (at that time: website, mobile application, cash desks and terminals in stores and operators in call center).
At the same time, within the IT landscape, we had large monolithic systems like Oracle ATG E-commerce platform, SAP CRM and others. Repetition of logic in each of them or implementation in one and reuse in another of the necessary functionality, according to our calculations, resulted in years of time and tens of millions of investments.
Therefore, we gathered a small team of developers and technically competent people who were at our disposal at that time, and thought about how we could make a separate service for our needs. In the process of elaboration, we realized that we actually need not one, but three or four working tools. This is how we come to the concept of microservice architecture for the first time.
We decided to code in Java, since we had the necessary experience in this. We chose Spring version 3.2. As a result, we got a kind of distributed micromonolith in three or four services, closely interconnected with each other. Despite the fact that they were developed independently, only everyone could work together.
However, it was a big leap forward in terms of developing its own technology. We switched from Java 6 to Java 8, started to master Spring 3, smoothly moving to Spring 4. Of course, it was a certain tryout.
We have successfully reduced the project implementation timeframe from obscure "months for development", having implemented the required cross-channel business logic in virtually two months.
Technological evolution
In 2017-18, we started a global refactoring of the micromonolith. The concept of microservices development was liked by both IT-specialists and business. The flow of work tasks began to grow. In addition, we continued to isolate functional blocks that are needed by different consumers from the corporate IT landscape and translate them onto the rails of microservices.
We tried to keep up with the times and jump to Java 9, but it was not crowned with success. Unfortunately, we did not get any tangible benefit from this exercise, so we stayed on Java 8. There
were more and more services, they had to be centrally managed and work with them standardized. This is where we tried containerization for the first time. Docker containers were then large and heavy, several hundred megabytes each.
Later, we had to solve issues with balancing traffic and load on services. We chose Consul for external clients and Eureka for internal ones as solutions. We tried different tools of interservice communication gRPC, RMI. We lived like this for almost a year, and it seemed to us that we learned how to successfully create microservices and build a microservice architecture.
Fasten your seat belts, we're drowning!
In 2019, the number of our microservices has increased significantly, exceeding the 100+ mark. We applied new solutions for interservice communication, where possible, tried to implement event based approaches.
Meanwhile, the issues of orchestration and dependency management were becoming more and more acute. But the biggest change that touched us already at the beginning of 2019 related to the change in the company's policy regarding the use of Java.
We had a choice of what to do next: stay with Oracle and pay them a lot of money, invest in our own build of open jdk, or try to find some real alternatives.
We chose the third option and together with BellSoft, which is one of the five world leaders involved in the development of the OpenJDK project, after a series of meetings and discussions, we formed a plan for the transition and piloting of the new version of Java, and combined this with the transition directly to Java 11. The process was difficult, but on all tests, we did not feel serious and unsolvable problems.
The next step for us was the implementation of container management for Kubernetes. Thanks to this, for some time it seemed to us that everything is fine and we have achieved serious success. But then the next problems with the infrastructure appeared. She simply could not cope with the constant increase in load.
We simply did not have time to scale. The need for the next cardinal technical transformations became obvious. So we began to look towards cloud technologies and strive to try them on ourselves.
Rise above the clouds
The beginning of 2020 promised us a big step in the development of our internal technologies, understanding and improvement of our microservice architecture. Ahead was a big step into the clouds. Alas, the plans had to be corrected, as they say, right in the course of the play.
Because of the COVID-19 pandemic, instead of gradually migrating and exploring the possibilities of cloud services, the whole company had to look for new tools to meet the changing needs of our customers due to the pandemic. We actually wrote the next microservices, simultaneously introducing new technologies and still moving to the cloud infrastructure.
For us, the size of containers has become critical for two simple reasons: it is money for the consumed cloud computing power and the time that the developer, and therefore the whole company, spends on lifting containers, synchronizing and configuring them, running autotests, and so on. And here we fully felt the advantage and usefulness of our compact containers with the Liberica JDK runtime.
Despite the height of the pandemic, in a few months we have implemented and successfully launched into productive operation two dozen microservices, entirely based on the cloud infrastructure.
At the end of 2020, we focused on process things: we invested a lot of time and effort in building a product approach, in developing microservices, in the selection and formation of separate teams with their own metrics and KPIs around various areas of business units.
Sawing the monolith into microservices using the example of the order calculation service
In order not to test your patience, I would like to demonstrate specific examples and logic of working with a microservice infrastructure. Let's take a typical order calculation in a standard IT environment.
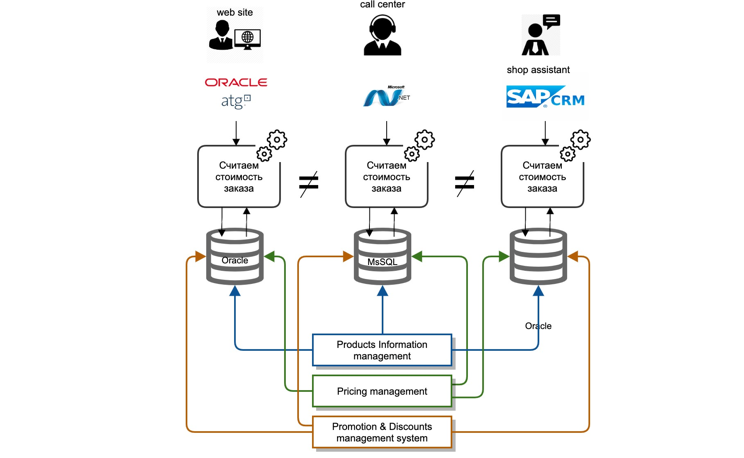
We faced a whole range of challenges. Our master data was deep in the systems in the back office. Each IT system is a classic monolith: database, application server. The integration of master systems with other participants in the IT landscape was carried out as a "point-to-point", that is, each IT system integrated itself, in its own way and every time anew.
The integrations were mainly of two types: replication at the database level, file transfer. The calculation logic was repeated in each IT system separately, namely in different development languages, there is no way to reuse even the code of a neighboring team.
It was extremely costly and almost impossible to synchronize the calculation logic simultaneously in all systems, due to different roadmaps and resource costs of various IT systems.
In addition, when dealing with customer complaints, it was extremely difficult for us to determine why the correct price or one or another discount was not provided.
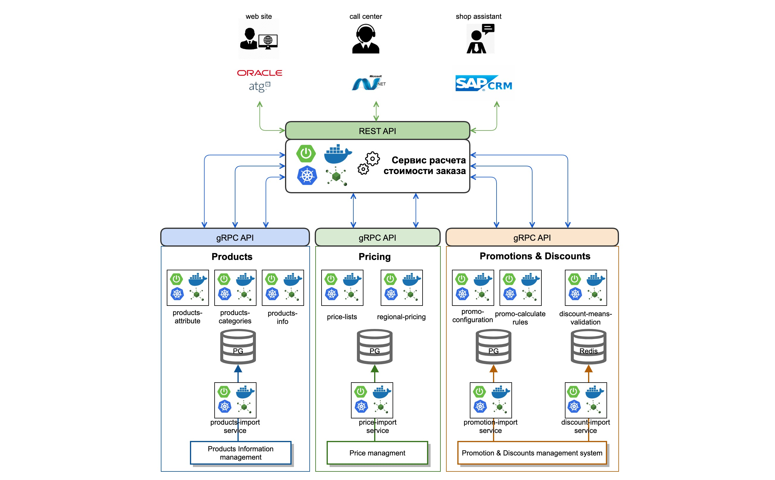
What have we done? We analyzed and determined the context that is necessary for the correct calculation of the order value. Next, we selected business domains and divided them internally into separate microservices. So, for example, we highlighted data on goods that had to be taken into account in the process of calculating the cost of an order.
We have implemented a service for importing data from master systems online using queues (Kafka). On top of the data, we have implemented atomic microservices that operate with product categories and their attributes (products-attribute-service, products-categories-service). We did the same with domains in the context of Price and Promotion.
Separately, we moved the logic and procedure for calculating order prices into a separate order-calculation-engine, implementing a single unified logic for calculating prices and costs, using discount funds and promotional cards.
We have also implemented a standardized REST API for all clients who implement the logic of order settlement. For interservice communication, we chose the gRPC protocol with a description on protobuf3.
As a result, a standard microservice today looks something like this: it is a spring boot application, which is collected in a docker container using GitLab CI and deployed in the Kubernetes cluster.
What's the bottom line?
On the way of our technical evolution, firstly, we have revised the approach to the process of developing the services themselves and forming teams. We focused on a product approach, recruited teams based on the maximum principles of autonomy.
At the same time, so that the teams correspond to specific business domains and areas and, accordingly, can, along with the heads of business functions, participate in the development of a particular business area.
In terms of technical development, we chose asynchronous connectivity using Kafka, including Kafka streams, as one of the tools for interservice communication. This allowed the teams to become practically independent from others. We also actively use and practice reactive development practices, using the reactor project as an example. We still really want to try project Loom.
To speed up development, we focused on the development of several technical and organizational factors that allowed us to significantly influence the timing.
The technological aspect is the transition to cloud technologies, which ensured the optimal speed of automation of the CI \ CD processes. The speed and duration of full regression and deployment of a particular microservice is critical here.
For example, today a full run (with all types of unit testing, contract, integration) CI \ CD Pipeline for a working productive business application ─ and this is about 12-15 microservices interconnected) is about 31 minutes, which is 7-8 minutes less than indicators early 2020.
Thus, we spend about 17-18% less time waiting for the result. This savings allows us to tackle other grocery tasks. This is largely due to the fact that we use compact containers based on Alpine Linux, which are getting faster and lighter every hour.
We have become more efficient in terms of microservice development in general. And this has a positive effect on the user experience of our customers. Speed is one of the key metrics of our online products (website and mobile apps) right now, and Liberica JDK also allows us to achieve this increase in performance, which we convert into a positive experience for our customers.
In addition, the right approach to microservices development allowed us to significantly speed up the time to launch our product to market. We learned how to bring individual services into production, using various strategies for deployment A \ B, cannery and others as needed. This makes it possible to quickly receive feedback on the work of microservices.
In two months we developed and implemented a couple of new services in the shopping experience. We are talking about the so-called fast delivery of goods within 2 hours (we use various taxi and delivery aggregators) and the issuance of our orders in the most unexpected places (in Pyaterochka stores or Russian Post offices, even in parking lots of large business centers).
Thanks to our microservices, some of the clients of the M.Video-Eldorado Group have the opportunity to take a taxi with their goods straight home from the store.
Creative plans
Our plans for 2021 include the active development of cloud infrastructure and the transition entirely to the concept of Infrastructure as a code ("Infrastructure as a code").
We plan to pay great attention to building transparent solutions for the control and interaction of microservices in the form of a Service Mesh solution based on Istio and Admiral. We have a lot of work ahead of us to tweak and improve the entire Observability stack, monitor request tracing and message logging.
We also plan to try using serverless technologies, including a desire to try it in java. In addition, there is a so far distant but not seemingly unrealistic idea to build a multi-Cloud infrastructure and ecosystem.
If you are interested in touching our technology stack with your hands, do not hesitate, there is enough work for everyone. Volunteer registration is carried out 24/7: here . You are welcome .
Benefits, life hacks, personal experience

Dmitry Chuiko , BellSoft Senior Performance Architect, on the secrets of tiny Docker containers for Java microservices:
─ . , . Docker-. , : , .
Linux , . JDK. , , .
1.
CentOS CentOS slim. ? Debian. Alpine musl. BellSoft Alpine Linux, — Linux. Liberica JDK 11.0.10 + 11.0.10 Linux.
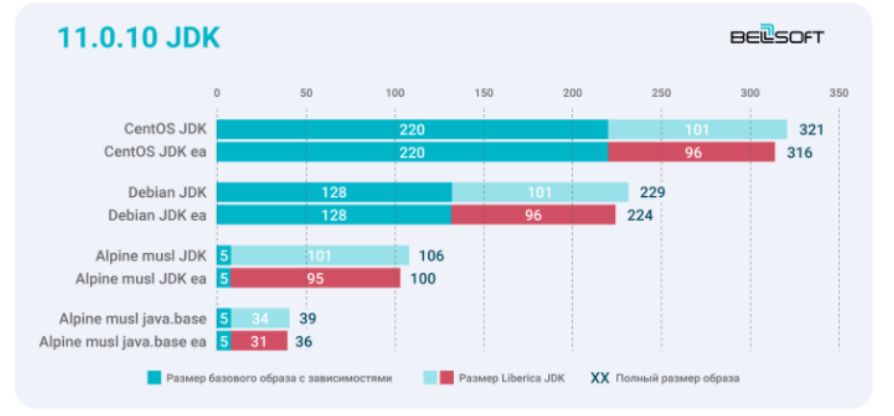
Liberica EA 3–6 14,7 % Alpine musl java.base. 7,6 %. Docker-, JRE java.base. Liberica JRE EA — 16 %.
Liberica Lite . , , — . - Java SE JVM, Standart, JIT- (C1, C2, Graal JIT Compiler), (Serial, Parallel, CMS, G1, Shenandoah, ZGC) serviceability, .
2. JDK
— jdeps JLINK. . Java (JDeps). - Java, . . JAR, , . JDeps JDK, Java-. , , .

jdeps , java.base. jlink. , BellSoft Docker- java.base. DockerHub, .
docker run –rm bellsoft/liberica – openjdk -demos- asciiduke.
CLI-like java.base. Liberica JDK Lite Alpine Linux musl 40,4 .
.
Enjoy!