Hello everyone. We are entering the home stretch: today is the final article on what data science can provide for predicting COVID-19.
The first article is here . The second is here .
Today we are talking with Alexander Zhelubenkov about his decisions to predict the spread of COVID-19.
Our conditions are as follows:
Given : Colossal data science capabilities, three talented specialists.
Find : Ways to predict the spread of COVID-19 a week ahead.
And here is the decision from Alexander Zhelubenkov
- Alexander, hello. First, tell us a little about yourself and your job.
- I work at Lamoda as the head of the data analysis and machine learning group. We are engaged in a search engine and algorithms for ranking products in the catalog. Data Science interested me when I was studying at Moscow State University at the Faculty of Computational Mathematics and Cybernetics.
- Knowledge and skills came in handy. You made a quality model: simple enough not to be overfitted. How did you manage to achieve this?
- The problem of forecasting time series is well studied, and what approaches can be applied to it is understandable. In our task, the samples are quite small by the standards of machine learning - several thousand observations in the training data and only 560 predictions need to be made for each week (forecast for 80 regions for each day of the next week). In such cases, coarser models are used that work well in practice. In fact, I ended up with a neat baseline.
As a model, I used gradient boosting on trees. You may notice that out of the box wooden models do not know how to predict trends, but if we switch to incremental targets, then it will be possible to predict the trend. It turns out that you need to teach the model to predict how much the number of cases will increase relative to the current day over the next X days, where X from 1 to 7 is the forecasting horizon.
Another feature was that the quality of the model's predictions was assessed on a logarithmic scale, that is, the penalty was not for how much you were wrong, but for how many times the model's predictions turned out to be inaccurate. And this had the following effect: the final quality of forecasts for all regions was greatly influenced by the accuracy of forecasts in small regions.
Timelines for each region were known: the number of cases in each of the days in the past and literally a few qualitative characteristics, such as population and the proportion of urban residents. Basically, that's all. It is difficult to retrain such data if it is normal to do the validation and determine where in the training of boosting it is worth stopping.
- What gradient boosting library did you use?
- I am in the old fashioned way - XGBoost. I know about LightGBM and CatBoost, but for such a task, it seems to me that the choice is not so important.
- Okay. But still the target. What did you take for the target? Is it the logarithm of the relationship of two days or the logarithm of the absolute value?
- As a target, I took the difference in the logarithms of the number of cases. For example, if today there were 100 cases, and tomorrow there are 200, then when forecasting one day ahead, you need to learn how to predict the logarithm of twofold growth.
In general, it is known that the first weeks there is an exponential increase in the spread of the virus. This means that if we use increments on a logarithmic scale as targets, then in fact it will be possible to predict a constant multiplied by the forecasting horizon every day. Gradient boosting is a versatile model, and copes well with such tasks.
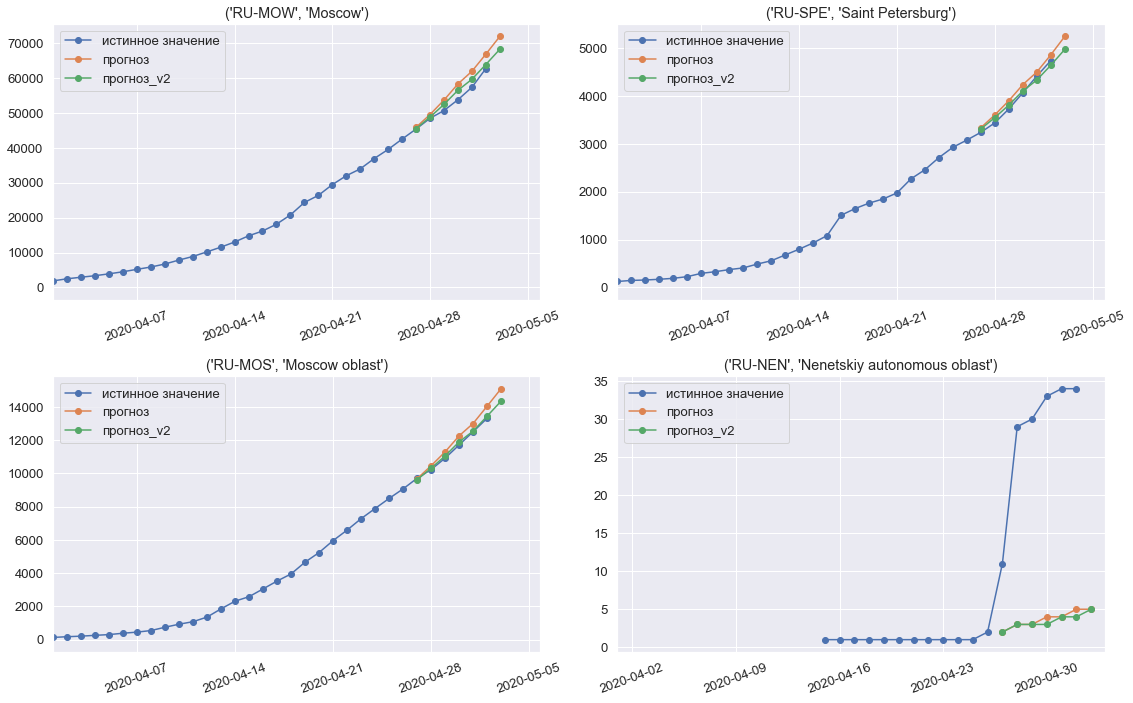
Model predictions for the third, final week of the competition
- What training sample did you take?
- To predict regions, I took information on distribution by country. It seems that this helped, since somewhere already the sharp growth was slowing down, and countries began to reach a plateau. In the regions of Russia, I cut off the initial period, when there were some isolated cases. For training, I used data from February.
- How are you validated?
- Validated in time, as for time series and it is customary to do. I used the last two weeks for the test. If we predict the last week, then for training we use all the data before it. If we predict the penultimate one, then we use all the data, without the last two weeks.
- Did you use something else? Some days, 10th or 20th day, meaning from there?
- The main factors that were important were different statistics: averages, median, increases over the last N days. For each region, it can be calculated separately. You can also add the same factors together separately, only calculated for all regions at once.
- Question about validation. Are you looking more at stability or accuracy? What was the criterion?
- I looked at the average quality of the model, which was obtained in the last two weeks selected for validation. When adding some factors, we got such a picture that with a fixed boosting configuration and varying only the random seed parameter, the quality of the predictions could jump a lot - that is, a large variance was obtained. In order not to retrain and get a more stable model, in the end I did not use such dubious factors in the final model.
- What do you remember? Surprised? A feature that worked, or some kind of boosting trick?
- I learned two lessons. First, when I decided to blend two models: linear and boosting, and at the same time, for each region, the coefficients with which these two models were taken (they turned out to be different) were simply adjusted in the last week - that is, for seven days. In fact, I set up 1-2 coefficients for each region for 7 days. But the discovery was this: the forecast turned out to be much worse as compared to if I had not made these settings. In some regions, the model was heavily retrained, and as a result, the forecasts in them turned out to be bad. At the third stage of the competition, I decided not to do this.
And the second point: it seems that the number of days from the beginning should be useful as a feature: from the first sick person, from the tenth sick person. I tried to add them, but on validation it made the situation worse. I explained it this way: the distribution of values in samples shifts over time. If you study on the 20th day from the beginning of the spread of the virus, then in predicting the distribution of the values of this feature will go seven days ahead, and, perhaps, this does not allow such factors to be used with benefit.
- You said that the proportion of the urban population played a role. And what else?
- Yes, the share of the urban population for both countries and regions of Russia has always been used. This factor consistently gave a small boost to the quality of forecasts. As a result, apart from the time series itself, I did not take anything else into the final model. Tried adding misc but didn't work.
- What is your opinion: SARIMA is the last century?
- Models of autoregressive - moving average - are more difficult to set up, and it is more expensive to add additional factors to them, although I am sure that with (S) ARIMA (X) models it would be possible to make good predictions, but not as good as compared to boosting.
- And for a longer period than a week, you can make predictions, what do you think?
- It would be interesting. Initially, the organizers had an idea to collect long-term forecasts. The month seems like a turning point when you can still try the approaches that I did.
- What do you think will happen next?
- We need to rebuild the model, look. By the way, my solution can be found here:
github.com/Topspin26/sberbank-covid19-challenge For the
latest COVID data science news from the international community, visit https://www.kaggle.com/tags/covid19 . And of course we invite you to the #coronavirus channel at opendatascience.slack.com (invited by ods.ai ).