The article is aimed at beginners like me.
Start
First, let's take a look at the problem. I took a little-known news site about Israel, since I myself live in this country, and I want to read news without advertising and not interesting news. And so, there is a site where news is posted: there are news marked in red, and there are ordinary ones. Those that are ordinary are nothing interesting, and those marked in red are the very juice. Consider our site.
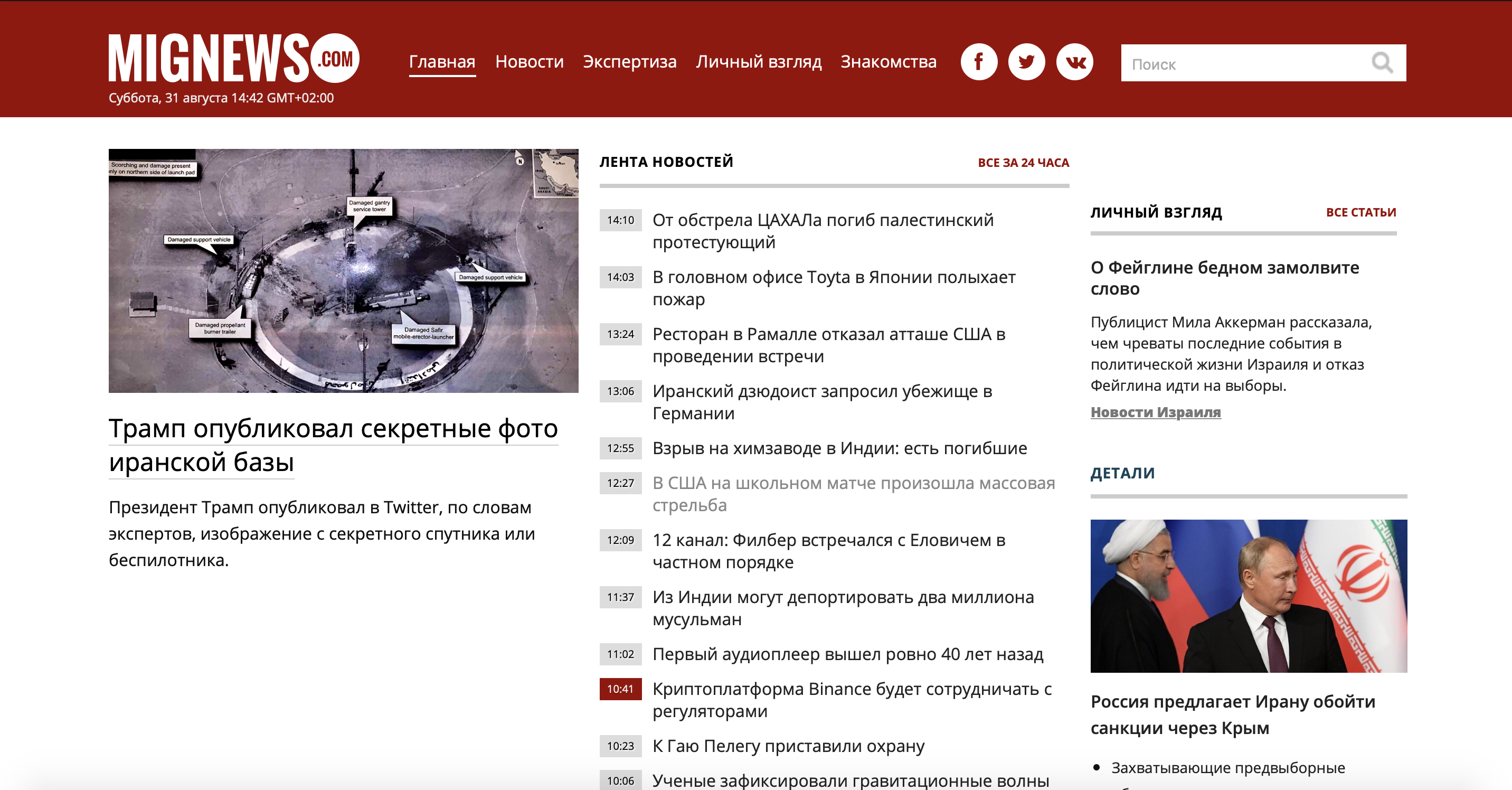
As you can see, the site is large enough and there is a lot of unnecessary information, but we only need to use the news container. Let's use the mobile version of the site
to save ourselves the same time and effort.

As you can see, the server gave us a beautiful container of news (which, by the way, is more than on the main site, which is in our favor) without ads and garbage.
Let's take a look at the source code to understand what we are dealing with.

As you can see, each piece of news lies separately in the 'a' tag and has the 'lenta' class. If we open the 'a' tag, we will notice that inside there is a 'span' tag, which contains the 'time2' or 'time2 time3' class, as well as the publication time, and after closing the tag, we observe the news text itself.
What separates important news from unimportant news? The same class 'time2' or 'time2 time3'. News marked 'time2 time3' is our red news. Since the essence of the task is clear, let's move on to practice.
Practice
To work with parsers, smart people came up with the "BeautifulSoup4" library, which has many more cool and useful functions, but more on that next time. We also need the Requests library that allows us to send various http requests. We go to download them.
(make sure you have the latest pip version)
pip install beautifulsoup4
pip install requests
Go to the code editor and import our libraries:
from bs4 import BeautifulSoup
import requests
First, let's save our URL to a variable:
url = 'http://mignews.com/mobile'
Now let's send a GET () request to the site and save the received data to the 'page' variable:
page = requests.get(url)
Let's check the connection:
print(page.status_code)
The code returned us the status code '200', which means that we are successfully connected and everything is in order.
Now let's create two lists (I'll explain what they are for later):
new_news = [] news = []
It's time to use BeautifulSoup4 and feed it our page, indicating in quotes how it will help us 'html.parcer':
soup = BeautifulSoup(page.text, "html.parser")
If you ask him to show what he saved there:
print(soup)
We will get out all the html-code of our page.
Now let's use the search function in BeautifulSoup4:
news = soup.findAll('a', class_='lenta')
Let's take a closer look at what we have written here.
In the previously created 'news' list (to which I promised to return), save everything with the 'a' tag and the 'news' class. If we ask to output to the console everything that it found, it will show us all the news that was on the page:

As you can see, along with the news text, the tags 'a', 'span', the classes 'lenta' and 'time2', and also 'time2 time3', in general, everything that he found according to our wishes.
Let's continue:
for i in range(len(news)):
if news[i].find('span', class_='time2 time3') is not None:
new_news.append(news[i].text)
Here, in a for loop, we iterate over our entire list of news. If in the news under the [i] index we find the 'span' tag and the class 'time2 time3', then we save the text from this news into a new list 'new_news'.
Note that we are using '.text' to reformat the strings in our list from the 'bs4.element.ResultSet' that BeautifulSoup uses for its searches to plain text.
Once I got stuck on this problem for a long time due to a misunderstanding of how data formats work and not knowing how to use debug, be careful. Thus, now we can save this data to a new list and use all the methods of the lists, because now this is ordinary text and, in general, do with it what we want.
Let's display our data:
for i in range(len(new_news)):
print(new_news[i])
Here's what we get:

We get post time and only interesting news.
Then you can build a bot in the Cart and upload this news there, or create a widget on your desktop with current news. In general, you can come up with a convenient way to learn about the news.
Hopefully this article will help newbies understand what can be done with parsers and help them get a little bit forward with their learning.
Thank you for your attention, I was glad to share my experience.