However, writing programs entirely in assembly language is not just long, dreary and difficult, but also somewhat silly - because high-level abstractions were invented for this purpose, to reduce development time and simplify the programming process. Therefore, most often, separately taken well-optimized functions are written in assembly language, which are then called from higher-level languages such as C ++ and C #.
Based on this, the most convenient programming environment will be Visual Studio, which already includes MASM. You can connect it to a C / C ++ project through the context menu of the Build Dependencies - Build Customizations ... project, by checking the box next to masm, and the assembler programs themselves will be located in files with the .asm extension (in the properties of which the Item Type must be set to Microsoft Macro Assembler ). This will allow not only compiling and calling assembly language programs without unnecessary gestures - but also performing end-to-end debugging, "falling through" into the assembler source directly from c ++ or c # (including the breakpoint inside the assembly listing), as well as tracking the state of the registers along with with the usual variables in the Watch window.
Syntax highlighting
Visual Studio does not have built-in syntax highlighting for assembler and other achievements of the modern IDE structure; but it can be provided with third party extensions.
AsmHighlighter is historically the first with minimal functionality and incomplete command set - not only AVX is missing, but also some of the standard ones, in particular fsqrt. This fact prompted me to write my own extension -
ASM Advanced Editor . In addition to highlighting and collapsing code sections (using comments "; [", "; [+" and ";]"), it binds hints to registers that pop-up on hovering down the code (also via comments). It looks like this:
;rdx=
or like this:
mov rcx, 8;=
Hints for commands are also present, but rather in an experimental form - it turned out that it will take more time to fill them fully than to write the extension itself.
It also suddenly turned out that the usual buttons for annotating / commenting the highlighted section of the code stopped working. Therefore, I had to write another extension in which this functionality was hung on the same button, and the need for this or that action is selected automatically.
Asm dude- showed up a little later. In it, the author went the other way and focused his efforts on the built-in command reference and autocompletion, including tracking tags. Code folding is also present there (according to "#region / #end region"), but there seems to be no binding of comments to registers yet.
32 vs. 64
Since the 64-bit platform appeared, it has become the norm to write 2 versions of applications. It's time to quit this! How much legacy can you pull. The same applies to extensions - you can only find a processor without SSE2 in a museum - besides, without SSE2 64-bit applications will not work. There will be no programming pleasure if you write 4 variants of optimized functions for each platform.
The advantage of the 64-bit platform is not at all in "wide" registers - but in the fact that the number of these registers has become 2 times more - 16 pieces of both general purpose and XMM / YMM. This not only simplifies programming, but also significantly reduces memory accesses.
FPU
If earlier there was nowhere without FPU, tk. functions with real numbers left the result on the top of the stack, then on a 64-bit platform the exchange takes place without its participation using the xmm registers of the SSE2 extension. Intel also actively recommends ditching FPUs in favor of SSE2 in its guidelines. However, there is a caveat: FPU allows you to perform calculations with 80-bit precision - which in some cases can be critical. Therefore, FPU support has not gone anywhere, and it is definitely not worth considering it as an outdated technology. For example, the calculation of the hypotenuse can be done "head-on" without fear of overflow,
namely
fld x fmul st(0), st(0) fld y fmul st(0), st(0) faddp st(1), st(0) fsqrt fstp hypot
The main difficulty in programming FPU is its stack organization. To simplify, a small utility was written that automatically generates comments with the current state of the stack (it was planned to add similar functionality directly to the main extension for syntax highlighting - but we never got around to that)
Optimization example: Hartley transform
Modern C ++ compilers are smart enough to automatically vectorize code for simple tasks such as summing numbers in an array or rotating vectors, recognizing the corresponding patterns in the code. Therefore, getting a significant performance gain on primitive tasks is not something that will not work - on the contrary, it may turn out that your super-optimized program runs slower than what the compiler generated. But you shouldn't draw far-reaching conclusions from this either - as soon as the algorithms become a little more complicated and not obvious for optimization, all the magic of optimizing compilers disappears. It is still possible to get a tenfold increase in performance through manual optimization in 2021.
So, as a task, we take the algorithm (slow) Hartley transforms :
the code
static void ht_csharp(double[] data, double[] result)
{
int n = data.Length;
double phi = 2.0 * Math.PI / n;
for (int i = 0; i < n; ++i)
{
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
double w = phi * i * j;
sum += data[j] * (Math.Cos(w) + Math.Sin(w));
}
result[i] = sum / Math.Sqrt(n);
}
}
It's also quite trivial for automatic vectorization (we'll see later), but it gives a little more room for optimization. Well, our optimized version will look like this:
code (comments removed)
ht_asm PROC local sqrtn:REAL10 local _2pin:REAL10 local k:DWORD local n:DWORD and r8, 0ffffffffh mov n, r8d mov r11, rcx xor rcx, rcx mov r9, r8 dec r9 shr r9, 1 mov r10, r8 sub r10, 2 shl r10, 3 finit fld _2pi fild n fdivp st(1), st fstp _2pin fld1 fild n fsqrt fdivp st(1), st ; mov rax, r11 mov rcx, r8 fldz @loop0: fadd QWORD PTR [rax] add rax, 8 loop @loop0 fmul st, st(1) fstp QWORD PTR [rdx] fstp sqrtn add rdx, 8 mov k, 1 @loop1: mov rax, r11 fld QWORD PTR [rax] fld st(0) add rax, 8 fld _2pin fild k fmulp st(1),st fsincos fld1;=u fldz;=v mov rcx, r8 dec rcx @loop2: fld st(1) fmul st(0),st(4) fld st(1) fmul st,st(4) faddp st(1),st fxch st(1) fmul st, st(4) fxch st(2) fmul st,st(3) fsubrp st(2),st fld st(0) fadd st, st(2) fmul QWORD PTR [rax] faddp st(5), st fld st(0) fsubr st, st(2) fmul QWORD PTR [rax] faddp st(6), st add rax, 8 loop @loop2 fcompp fcompp fld sqrtn fmul st(1), st fxch st(1) fstp QWORD PTR [rdx] fmulp st(1), st fstp QWORD PTR [rdx+r10] add rdx,8 sub r10, 16 inc k dec r9 jnz @loop1 test r10, r10 jnz @exit mov rax, r11 fldz mov rcx, r8 shr rcx, 1 @loop3:;[ fadd QWORD PTR [rax] fsub QWORD PTR [rax+8] add rax, 16 loop @loop3;] fld sqrtn fmulp st(1), st fstp QWORD PTR [rdx] @exit: ret ht_asm ENDP
Please note: there is no loop unrolling, no SSE / AVX, no cosine tables, no complexity reduction due to the "fast" transformation algorithm. The only explicit optimization is the iterative sine / cosine computation in the inner loop of the algorithm directly in the FPU registers.
Since we are talking about an integral transformation, in addition to speed, we are also interested in the accuracy of the calculation and the level of accumulated errors. In this case, it is very simple to calculate it - by doing two transformations in a row, we should get (in theory) the initial data. In practice, they will be slightly different, and it will be possible to calculate the error through the standard deviation of the obtained result from the analytical one.
The results of auto-optimizing a c ++ program can also greatly depend on the compiler parameter settings and the choice of a valid extended instruction set (SSE / AVX / etc). However, there are two nuances:
- Modern compilers tend to calculate everything possible at the compilation stage - therefore, it is quite possible in the compiled code, instead of the algorithm, to see a pre-calculated value, which, when measuring performance, will give the compiler an advantage of 100,500 times. To avoid this, my measurements use the external function zero (), which adds ambiguity to the input parameters.
- « AVX» — , AVX. . – , AVX .
The most interesting optimization parameter is the Floating Point Model, which takes Precise | Strict | Fast values. In the case of Fast, the compiler is allowed to do any mathematical transformations at its discretion (including iterative calculations) - in fact, only in this mode automatic vectorization takes place.
So, Visual Studio 2019 compiler, AVX2 target framework, Floating Point Model = Precise. To make it even more interesting, it will measure from a c # project on an array of 10,000 elements:
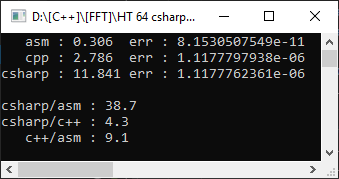
C #, as expected, turned out to be slower than C ++, and the assembler function turned out to be 9 times faster! However, it's too early to rejoice - let's set Floating Point Model = Fast:

As you can see, this helped to significantly speed up the code and the lag from manual optimization was only 1.8 times. But what has not changed is the error. That the other option gave an error of 4 significant digits - and this is important in mathematical calculations.
In this case, our version turned out to be both faster and more accurate. But this is not always the case - and choosing FPU to store the results, we will inevitably lose in the possibility of optimization by vectorization. Also, no one forbids combining FPU and SSE2 in cases where it makes sense (in particular, I used this approach in the implementation of double-double arithmetic , having received a 10-fold speedup during multiplication).
Further optimization of the Hartley transform lies in a different plane and (for an arbitrary size) requires the Bluestein algorithm, which is also critical to the accuracy of intermediate calculations. Well, this project can be downloaded on GitHub , and as a bonus there are also a couple of functions for summing / scaling arrays for FPU / SSE2 / AVX (for educational purposes).
What to read
Literature on assembler in bulk. But there are several key sources:
1. Official documentation from Intel . Nothing superfluous, the probability of typos is minimal (which are ubiquitous in the printed literature).
2. Online directory , grabbed from the official documentation.
3. Site of Agner Fogh , a recognized optimization expert. Also contains samples of optimized C ++ code using intrinsics.
4. SIMPLY FPU .
5.40 Basic Practices in Assembly Language Programming .
6. Everything you need to know to start programming for 64-bit versions of Windows .
Appendix: Why not just use Intrinsics?
Hidden text
, , , - — , SIMD- . — .
:
:
- . DOS , – .
- . – .
- . , , (FPU). . , //etc.
- - – , , . , , .
- , C++ , - SIMD-. 32- XMM8 XMM0 / XMM7 – . — , , , . – , C++.
- , . , – Microsoft , C++.