
GTA Online is notorious for its slow loading speed. Having recently launched the game to complete new raid missions, I was shocked to find it loading just as slowly as it did when it was released seven years ago.
The time has come. For now, figure out the reasons for this.
Intelligence service
To begin with, I wanted to check if anyone had already solved this problem. Most of the results found consisted of anecdotal data about how difficult the game was , that it had to load for so long, stories about the lameness of the p2p network architecture (and this is true), complex ways of loading into story mode, and then into a single session and pairs mods that allowed you to skip the opening video with the R * logo. Some sources reported that when all these methods are used together, you can save as much as 10-30 seconds!
Meanwhile, on my PC ...
Benchmark
: 1 10
-: 6
, R* ( social club ).
, : AMD FX-8350
SSD: KINGSTON SA400S37120G
: 2 Kingston 8192 (DDR3-1337) 99U5471
GPU: NVIDIA GeForce GTX 1070
I know my car is outdated, but why the hell does online mode load six times slower? I could not find any difference when using the “story first, then online” uploading technique, as others have done before me . But even if it worked, the results would be within the margin of error.
I'm not alone
According to this poll , the problem is so widespread that it slightly infuriates over 80% of the player base. Guys from R *, actually seven years have passed!

18.8% of players have the most powerful computers or consoles, 81.2% are pretty sad, 35.1% are quite sad.
After searching for 20% of those lucky ones whose loading takes less than three minutes, I found a number of benchmarks with powerful gaming PCs and an online loading time of about two minutes. To get a load time of two minutes I would
How is it that the people doing these benchmarks still take about a minute to load story mode? (By the way, the benchmark with M.2 does not take into account the display time of the logos at the beginning.) In addition, loading from story mode to online mode takes them only a minute, while mine takes more than five. I know that their technique is much better than mine, but definitely not five times.
Very accurate measurements
Armed with powerful tools like the Task Manager , I launched an investigation to figure out what resources might be the bottleneck.
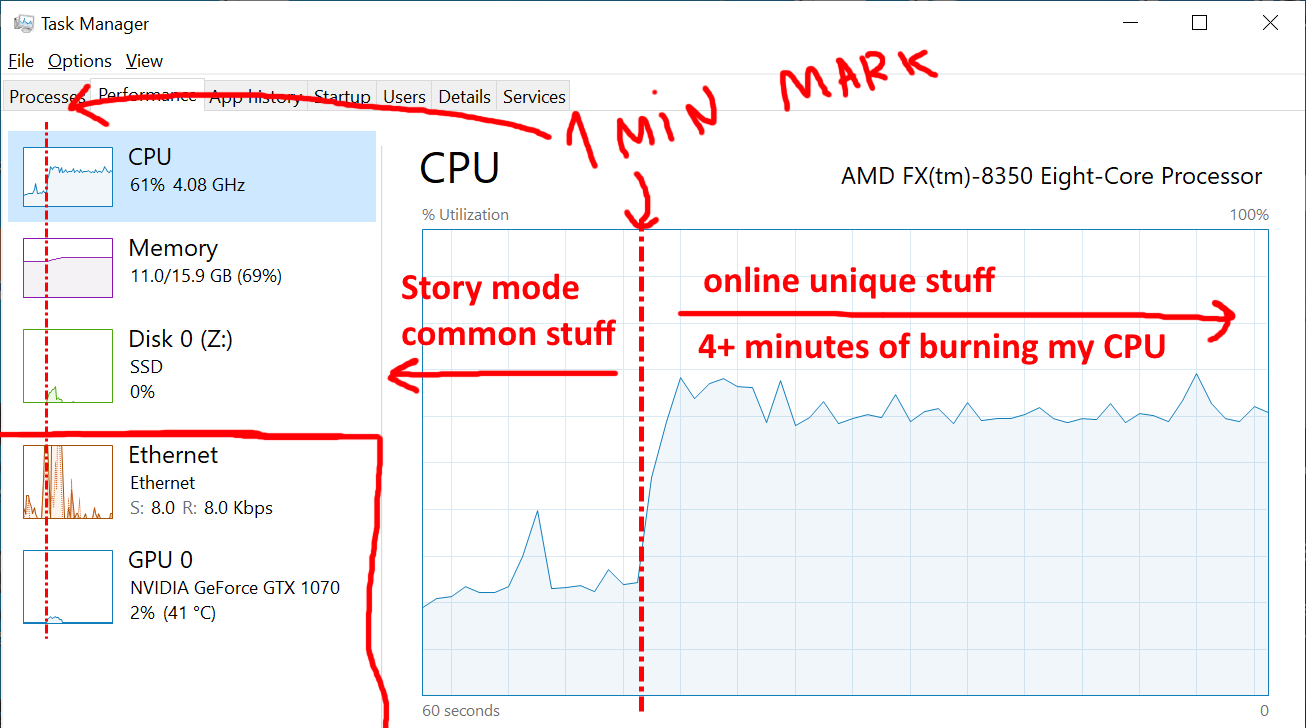
Within one minute, the standard resources of the story mode are loaded, after which the game loads the processor for more than four minutes.
After a minute of loading the shared resources used in both story and online modes (an indicator almost equal to the benchmarks of powerful PCs), GTA decides to load one core of my machine as much as possible for four minutes and do nothing else.
Disk access? He's gone! Network usage? There are not many, but after just a few seconds, the traffic drops to almost zero (except for the loading of rotating banners with information). GPU usage? By zeros. Memory usage? Perfectly flat graph ...
What's going on, the game is mining a crypto or something? It starts to smell like code. Very bad code .
Limiting one stream
Although my old AMD CPU has eight cores and can still perform well, it was built in the old days. Back then, the single-threaded performance of AMD processors was far behind those of Intel processors. This may not explain all the difference in load times, but it should explain the most important thing.
The weird thing is that the game only uses the CPU. I was expecting a huge amount of resources loaded from disk or a bunch of network requests to create a session on the p2p network. But this? This is most likely a bug.
Profiling
Profilers are a great way to find CPU bottlenecks. There is only one problem - most of them use source code to get a perfect picture of what is happening in the process. And I don't have it. But I also don't need readings accurate to microseconds — the bottleneck lasts four minutes.
Stack sampling comes on the scene: this is the only way to explore closed source applications. We perform a stack dump of the running process and the location of the current command pointer to build a call tree at specified intervals. Then we add them up to get statistics about what is happening. There is only one profiler I know (I could be wrong here) that can do this on Windows. And it hasn't been updated for over ten years. This is Luke Stackwalker! Let someone give their love to this project.

The culprits # 1 and # 2.
Luke usually groups the same functions, but since I have no debug symbols, I need to look through the nearest addresses with my eyes to understand that they are the same place. And what do we see? Not one, but two bottlenecks!
Down the rabbit hole
Borrowing from other quite legitimate copy of the popular disassembler (no, I can not afford it ... have to somehow explore ghidra ), I began to GTA disassembly.
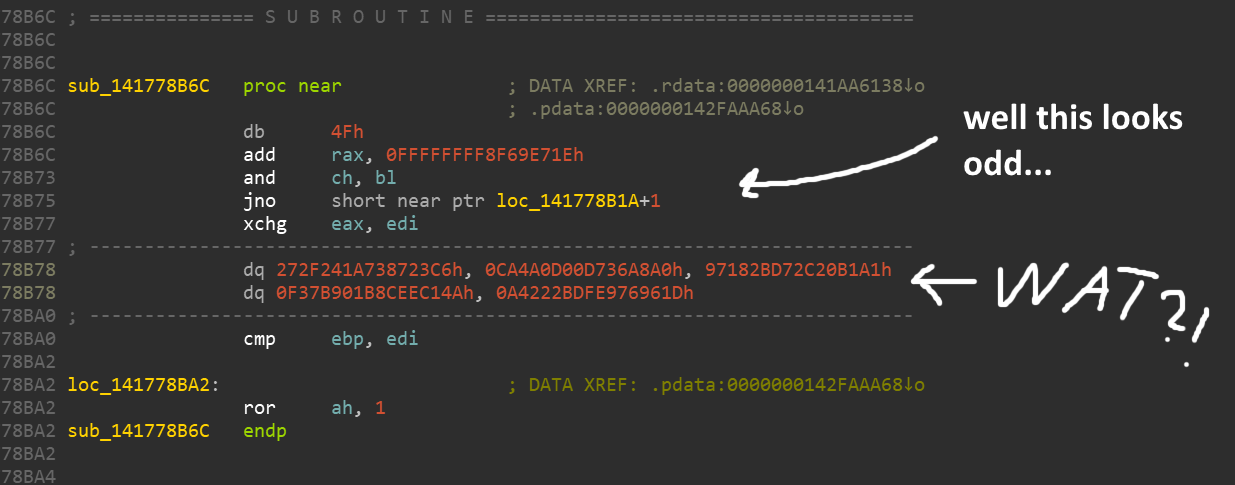
It all seems completely wrong. Many high-budget games have built-in reverse engineering protection to guard against pirates, cheaters, and modders (not to say that it ever stops them).
It looks like some kind of obfuscation / encryption is used here, due to which most of the commands are replaced by gibberish. But don't worry, we just need to dump the game's memory when we execute the part we want to learn. Before their execution, the commands must be deobfuscated in one way or another. I had Process Dump close at hand , but there are many other tools out there that can do similar things.
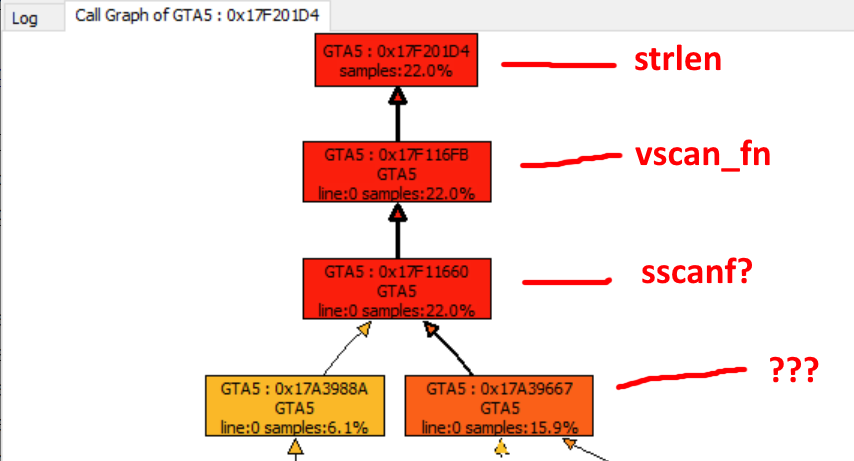
Problem # 1: is this ... strlen ?!
Disassembling the now less obfuscated dump reveals that one of the addresses has a label taken from nowhere! Is it
strlen
? The next one down the call stack is marked as
vscan_fn
, after which the labels end, however I'm pretty sure it is
sscanf
.
They scrape something. But what? Parsing the disassembled code would take infinity, so I decided to dump some samples from the running process using x64dbg . After a bit of debugging, I figured out that this is ... JSON! They parse JSON. A whopping 10 megabytes of JSON data with almost 63 thousand elements .
...,
{
"key": "WP_WCT_TINT_21_t2_v9_n2",
"price": 45000,
"statName": "CHAR_KIT_FM_PURCHASE20",
"storageType": "BITFIELD",
"bitShift": 7,
"bitSize": 1,
"category": ["CATEGORY_WEAPON_MOD"]
},
...
What is it? According to some sources, this looks like an "online store directory" data. I will assume that they contain a list of all the possible items and upgrades that can be purchased in GTA Online.
Clarification: I believe these are items purchased with in-game money and not directly related to microtransactions .
But 10 megabytes is a trifle! And the use
sscanf
may not be optimal, but it cannot be so bad? Well ...

10 megabytes of C strings in memory. 1. Move the pointer a few bytes to the next value. 2. We call
sscanf(p, "%d", ...)
. 3. We read each character in 10 megabytes while reading each small value (!?). 4. Return the scanned value.
Yes, it will take a long time ... To be honest, I had no idea what most implementations are
sscanf
calling
strlen
, so I can't blame the developer who wrote this. I would suggest that this data is simply scanned byte by byte and processing may stop at
NULL
.
Problem # 2: Let's use a hash ... array?
It turned out that the second culprit is being called directly next to the first. They are both even called in the same statement
if
, as can be understood in this ugly decompilation:

Both problems are inside one big parsing loop of all items. Problem # 1 is parsing, problem # 2 is saving.
All the labels are specified by me, I have no idea what the functions and parameters are really called.
What is the second problem? Immediately after the item is parsed, it is saved into an array (or into a C ++ embedded list? Is not entirely clear). Each item looks something like this:
struct {
uint64_t *hash;
item_t *item;
} entry;
But what happens before saving? The code checks the entire array, element by element, comparing the hash of the item to see if it is in the list. If my calculations are correct, then with about 63 thousand elements this gives
(n^2+n)/2 = (63000^2+63000)/2 = 1984531500
checks. Most of them are useless. We have unique hashes , so why not use a hash map ?

The profiler shows that the first two lines are loading the processor. The statement
if
is executed only at the very end. The penultimate line inserts the subject.
In reverse engineering, I named this structure
hashmap
, but it is obvious that it is
not_a_hashmap
. And then everything just gets better. This hash / array / list is empty before loading JSON. And all items in JSON are unique! The code does n't even need to check if the item is on the list! There is even a function for directly inserting items, just use it! Seriously, what the fuck !?
Proof of Concept
This is all great, of course, but no one will take me seriously until I test it so that I can write a clickbait headline for a post.
What's the plan? Write
.dll
, inject her GTA, intercept several functions, ???, PROFIT!
The JSON problem is confusing, and replacing the parser would be extremely time consuming. It is much more realistic to try to replace it
sscanf
with a function that does not depend on
strlen
. But there is an even easier way.
- intercept strlen
- wait for a long line
- "Cache" its start and length
- if it is called again within the string, return the cached value
Something like this:
size_t strlen_cacher(char* str)
{
static char* start;
static char* end;
size_t len;
const size_t cap = 20000;
// if we have a "cached" string and current pointer is within it
if (start && str >= start && str <= end) {
// calculate the new strlen
len = end - str;
// if we're near the end, unload self
// we don't want to mess something else up
if (len < cap / 2)
MH_DisableHook((LPVOID)strlen_addr);
// super-fast return!
return len;
}
// count the actual length
// we need at least one measurement of the large JSON
// or normal strlen for other strings
len = builtin_strlen(str);
// if it was the really long string
// save it's start and end addresses
if (len > cap) {
start = str;
end = str + len;
}
// slow, boring return
return len;
}
As for the hash array problem, everything is easier with it - you can just completely skip duplicate checks and insert items directly, because we know that the values are unique.
char __fastcall netcat_insert_dedupe_hooked(uint64_t catalog, uint64_t* key, uint64_t* item)
{
// didn't bother reversing the structure
uint64_t not_a_hashmap = catalog + 88;
// no idea what this does, but repeat what the original did
if (!(*(uint8_t(__fastcall**)(uint64_t*))(*item + 48))(item))
return 0;
// insert directly
netcat_insert_direct(not_a_hashmap, key, &item);
// remove hooks when the last item's hash is hit
// and unload the .dll, we are done here :)
if (*key == 0x7FFFD6BE) {
MH_DisableHook((LPVOID)netcat_insert_dedupe_addr);
unload();
}
return 1;
}
Full sources of proof of concept can be found here .
results
So how did it work?
Initial load time for online mode: about 6 minutes
Time with only patched duplicate checks: 4 minutes 30 seconds
Time with JSON parser patch only: 2 minutes 50 seconds
Time with patches of both problems: 1 minute 50 seconds
(6 * 60 - (1 * 60 + 50)) / (6 * 60) = download time decreased by 69.4% (great!)
Oh yes, how it worked!
Most likely, this will not decrease the load time for all players - there may be other bottlenecks on other systems, but this is such an obvious problem that I do not understand how R * has not noticed it all these years.
tl; dr
- There is a CPU bottleneck when launching GTA Online due to single threaded execution
- It turns out that GTA is battling parsing a 10MB JSON file at this time.
- The JSON parser itself is poorly written / naively implemented and
- After parsing, a slow procedure is performed to check that there are no duplicate items
R * please solve the problem
Please, if this article somehow makes it to Rockstar, it won't take more than a day for one developer to fix these issues. Please do something about it.
You can switch to hashmap to eliminate duplicates, or skip this check entirely, which will be faster. In the JSON parser, replace the library with a more efficient one. I don't think there is an easier solution here.
Thank.