
When we talk about CI&CD, we often go deeper into the basic tools for automating build, testing and application delivery - focusing on the tools, but forgetting to cover the processes that occur during the cutting and stabilization of releases. However, not all ready-made tools are equally useful, and some custom processes do not fit into their coverage. You have to research the processes and find ways to automate them to optimize them.
At our company, QA engineers use Zephyr to track the progress of regression, since we cannot replace manual and exploratory testing with autotests. But despite this, autotests are often chased here and in large quantities, so I want to be able to omit some banal checks that have been automated and let testers do more productive and useful work.
We have night runs where full test suites are being chased. But at the very dawn of mastering Zephyr, during regression our testers had to download xcresult, or even earlier plist, or junit xml, and then put down the correspondences of green and red tests in marshmallows with their hands. This is a rather routine operation, and it takes a lot of time to pass 500-600 tests by hand. You want to leave such things at the mercy of a soulless machine. This is how ZERG was born.
Zerg is born
Zephyr Enterprise Report Generator is a small utility that initially only knew how to search for matches in the test report and send their current statuses to Zephyr. Later, the utility received new functions, but today we will focus on finding and sending reports.
In Zephyr, we are asked to operate with versions, loops, and executions of test cases. Each version contains an arbitrary number of cycles, and each cycle contains case passes. Such passes contain information about the task (zephyr integrates perfectly with jira and the test case is, in fact, a task in jira), the author, the status of the case, as well as who is engaged in this case and other necessary details.
To automate the problem that we outlined above, it is important for us to understand how to set the status of the case.
Working with code
But how do you correlate the code test and the marshmallow test? Here we have taken a rather simple and straightforward approach: for each test, we add links to tasks in jira in the comments section.
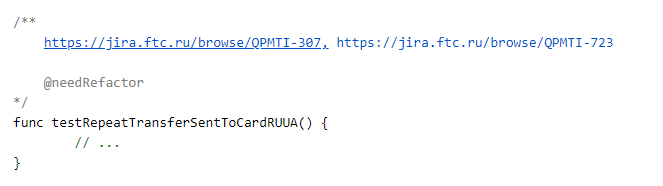
Additional parameters can also be placed in the comments, but more on that later.
So, one test in the code can cover several tasks. But the reverse logic also works. Several tests can be written in code for one task. Their statuses will be taken into account when compiling the report.
We need to go through the source code, extract all test classes and tests, link tasks with methods and correlate this with the test passing report (xcresult or junit).
You can work with the code itself in different ways:
- just read files and retrieve information through regular expressions
- use SourceKit
Be that as it may, even when using SourceKit, we cannot do without regular expressions for extracting task IDs from links in comments.
At this stage, we are not interested in details, so we will fence ourselves off from them with a protocol:

We need to get tests. To do this, we describe the structures:
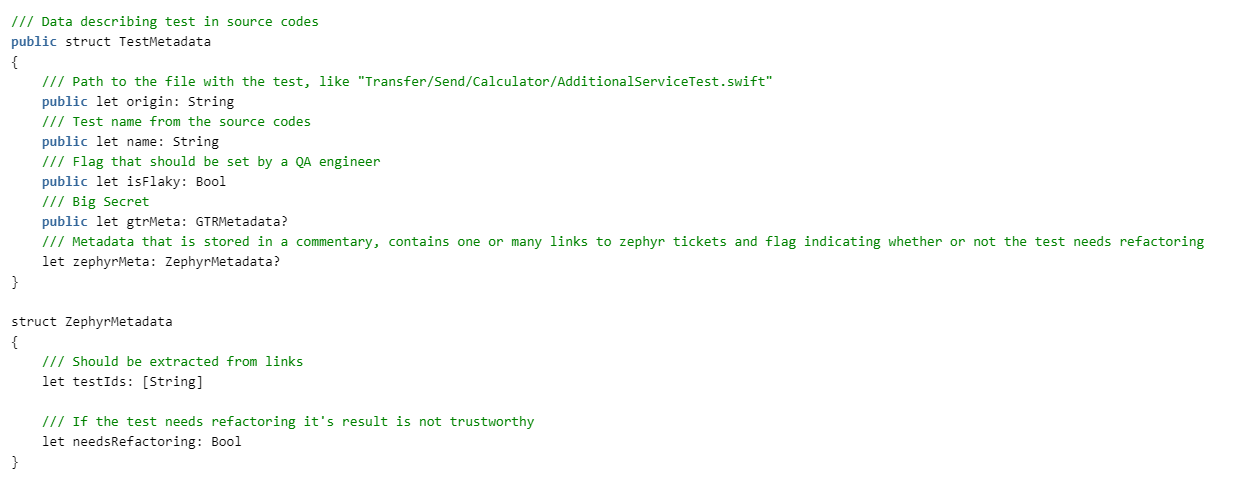
Then we need to read the report on the passing of tests. ZERG was born before moving to xcresult, and therefore can parse plist and junit. We are still not interested in the details in this article, they will be attached in the code. Therefore, we will fence off the protocols

All that remains is to link the tests in the code with the test results from the reports.
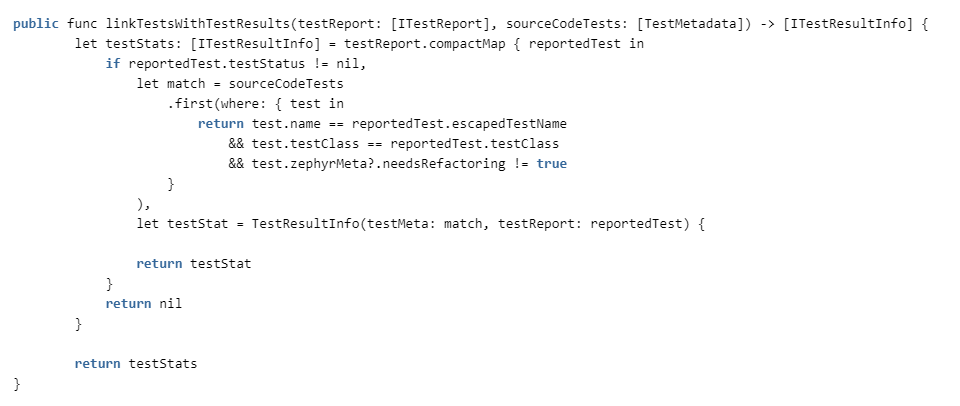
We check the correspondence by class name and test name (different classes may have methods with the same name) and whether refactoring is needed for the test. If you need it, then we consider that it is unreliable and throw it out of statistics.
We work with marshmallows
Now that we have read the test reports, we need to translate them into the zephyr context. To do this, you need to get a list of project versions, correlate with the version of the application (for this to work like this, it is necessary that the version in the marshmallow coincides with the version in the Info.plist of your application, for example, 2.56), download loops and passes. And then correlate the passes with our existing reports.
To do this, we need to implement the following methods in ZephyrAPI: The
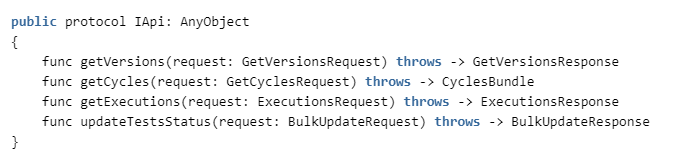
specification can be seen here: getzephyr.docs.apiary.io , and the client implementation is in our repository.
The general algorithm is pretty simple:
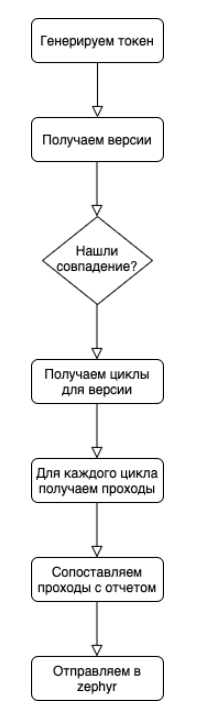
At the stage of matching passes with reports, there is a subtle point that must be taken into account: in the zephyr api, it is most convenient to send the execution update in batches, where the general status and a list of pass IDs are transmitted. We need to expand our ticket reports and take into account the nm ratio. For one case in marshmallow, there can be several tests in the code. One test in the code can cover several cases. If for one case there are n tests in the code and one of them is red, then for such a case the general status is red, but if one of such tests covers m cases and it is green, then the rest of the cases should not turn red.
Therefore, we operate with sets and look for the intersection of red and green. Anything that falls into the intersection we subtract from the green results and send the edited information to zephyr.

It should also be noted here that within the team we have agreed that zerg will not change the status of the pass if:
1. The current status is blocked or failed (we used to change the status for failed, but now we have given up practice, because we want testers to pay attention for red autotests during regression).
2. If the current status is pass and it was set by a person, not zerg.
3. If the test is marked as flashing.
Zephyr API Interests
When requesting loops, we receive json, which at first glance cannot be systematized for deserialization. The point is that a request to get loops for a version, although it should return an array of loops, in fact, returns one object, where each field is unique and is called the loop identifier, which lies in the value. To handle this, we use simple hacks:

Test passing statuses come in one of the requests next to the request object. But they can be moved in advance to enum:

When requesting loops, you need to pass the version and integer project identifier to the request parameters. But in the request for passes for the loop, the same project identifier must be passed in a string format.

Instead of a conclusion
If there is a lot of routine work, then most likely something can be automated. Synchronizing the passage of autotests with the test management system is one of such cases.
Thus, every night we have a full test run, and during regression, the report is sent to QA engineers. This reduces the regression time and gives time for exploratory testing.
If you correctly implement the android source parser, then it can be applied with the same success for the second platform.
Our Zerg, in addition to comparing tests, is also able to perform initial impact analysis, but more about that, perhaps next time.