Our readers couldn't help but notice our growing interest in the Go language. Along with the book from the previous post , we have a lot of interesting things on this topic . Today we want to offer you a translation of the material "for the pros", which demonstrates interesting aspects of manual memory management in Go, as well as the simultaneous execution of memory operations in Go and C ++.
In Dgraph Labs language Go used since its establishment in 2015. After five years or 200 000 lines of code on the Go, ready to happily announce that it is not wrong to Go. This language inspires not only as a tool for creating new systems, but even encourages scripts to be written in Go that were traditionally written in Bash or Python. It turns out that Go allows you to create a base of clean, readable, maintainable code that - most importantly - is efficient and easy to handle concurrently.
However, there is one problem with Go, which manifests itself already in the early stages of work: memory management... We have not had any complaints about the Go garbage collector, but, besides, how much it simplifies the life of developers, it has the same problems as other garbage collectors: it simply cannot compete in efficiency with manual memory management .
Managing memory manually results in less memory usage, predictable memory usage, and avoids crazy spikes in memory usage when a large new chunk of memory is allocated sharply. All of the above problems with automatic memory management have been noticed when using memory in Go.
Languages like Rust are able to gain a foothold in part because they provide safe manual memory management. This is welcome.
In my experience, manually allocating memory and tracking down potential memory leaks is easier than trying to optimize memory usage with garbage collection tools. Manual garbage collection is well worth the hassle of creating databases that offer virtually unlimited scalability.
For the love of Go and the need to avoid garbage collection using the Go GC, we had to find innovative ways to manually manage memory in Go. Of course, most Go users will never need to manually manage memory, and we recommend that you avoid doing this unless you really need to. And when you need it - you need to know how to do it .
Building memory with Cgo
This section is modeled after the Cgo wiki article on converting C arrays to Go segments. We could use malloc to allocate memory in C and use unsafe to pass it to Go, without requiring any intervention from the Go garbage collector.
import "C"
import "unsafe"
...
var theCArray *C.YourType = C.getTheArray()
length := C.getTheArrayLength()
slice := (*[1 << 28]C.YourType)(unsafe.Pointer(theCArray))[:length:length]
However, the above is possible with the caveat noted at golang.org/cmd/cgo.
: . Go nil C ( Go) C, , C Go. , C Go, Go . C, Go.
Therefore, instead of malloc, we will use its
calloc
slightly heavier counterpart .
calloc
works exactly like this
malloc
, with the caveat that it resets memory to zero before returning it to the caller.
To get started, we just implemented in their simplest form the Calloc and Free functions that allocate and free byte segments for Go via Cgo. To test these features, a continuous memory usage test was developed and tested. ... This test, in the form of an endless loop, repeated a memory allocation / release cycle, in which first randomly sized memory fragments were allocated until the total amount of allocated memory reached 16GB, and then these fragments were gradually freed until only 1GB of memory remained.
The equivalent C program worked as expected. We
htop
saw how the amount of memory allocated to the process (RSS) first gets to 16GB, then drops to 1 GB, then grows back to 16 GB, and so on. However, a Go program using
Calloc
and was
Free
using more and more memory after each loop (see diagram below).
It has been suggested that this is due to memory fragmentation due to the lack of "thread awareness" in the
C.calloc
default calls . To avoid this, it was decided to try
jemalloc
.
jemalloc
jemalloc
Is a generic implementationmalloc
that focuses on preventing fragmentation and maintaining scalable concurrency.jemalloc
was first used in FreeBSD in 2005 as an allocatorlibc
and has since found use in many applications due to its predictable behavior. - jemalloc.net
We switched our APIs to use
jemalloc
with calls
calloc
and
free
. Moreover, this option worked perfectly: it
jemalloc
natively supports streams with almost no memory fragmentation. The memory test, which tested the memory allocation and deallocation cycles, remained within reason, apart from the small overhead involved in running the test.
Just to reinforce that we are using jemalloc and avoiding naming conflicts, we add a prefix when installing
je_
so that our APIs now call
je_calloc
and
je_free
, not
calloc
and
free
.
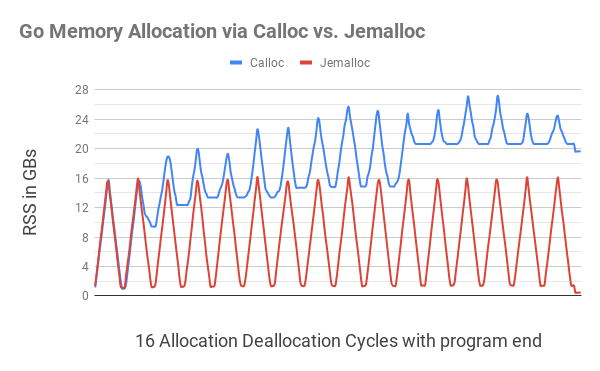
This illustration shows that allocating Go memory with
C.calloc
leads to serious memory fragmentation, which causes the program to consume up to 20GB of memory by the 11th cycle. The equivalent code
jemalloc
did not give any noticeable fragmentation, fitting in each cycle close to 1GB.
Closer to the end of the program (a small ripple on the right edge), after all the allocated memory was freed, the program
C.calloc
still consumed a little less than 20GB of memory, while it
jemalloc
cost only 400MB of memory.
To install jemalloc, download it from here and then run the following commands:
./configure --with-jemalloc-prefix='je_' --with-malloc-conf='background_thread:true,metadata_thp:auto' make sudo make install
The whole code
Calloc
looks something like this:
ptr := C.je_calloc(C.size_t(n), 1)
if ptr == nil {
// NB: throw panic, ,
// . , – , Go,
// .
throw("out of memory")
}
uptr := unsafe.Pointer(ptr)
atomic.AddInt64(&numBytes, int64(n))
// C Go, .
return (*[MaxArrayLen]byte)(uptr)[:n:n]
This code is included in the Ristretto package . An assembly tag has been added to enable the resulting code to switch to jemalloc for allocating byte chunks
jemalloc
. To further simplify deployment operations, the library was statically linked
jemalloc
to any resulting Go binary by setting the appropriate LDFLAGS flags.
Decomposing Go Structures into Byte Segments
We now have a way to allocate and free a byte segment, and then we'll use that to arrange structures in Go. You can start with the simplest example (complete code).
type node struct {
val int
next *node
}
var nodeSz = int(unsafe.Sizeof(node{}))
func newNode(val int) *node {
b := z.Calloc(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = val
return n
}
func freeNode(n *node) {
buf := (*[z.MaxArrayLen]byte)(unsafe.Pointer(n))[:nodeSz:nodeSz]
z.Free(buf)
}
In the example above, we laid out the Go structure on memory allocated in C using
newNode
. We have created a function
freeNode
that allows us to free memory as soon as we are done with the structure. The structure in Go language contains the simplest data type
int
and a pointer to the next node structure, all this can be set in the program, and then these entities can be accessed. We have selected 2M node objects and created a linked list from them to demonstrate that jemalloc functions as expected.
With Go's default memory allocation, you can see that 31 MiB of the heap is allocated to a linked list with 2M objects, but nothing is allocated through
jemalloc
.
$ go run . Allocated memory: 0 Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 31 MiB
Using the assembly tag
jemalloc
, we see that 30 MiB bytes of memory are allocated in through
jemalloc
, and after the linked list is released, this value drops to zero. Go only allocates 399 KiB from memory, which is probably due to the overhead of running the program.
$ go run -tags=jemalloc . Allocated memory: 30 MiB Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 399 KiB
Amortizing Calloc Costs with Allocator
The above code does a great job of memory allocation in Go. But this is done at the expense of performance degradation . Having driven both copies with
time
, we see that without the
jemalloc
program coped in 1.15 seconds. Since
jemalloc
she did 5 times slower, with over 5.29.
$ time go run . go run . 1.15s user 0.25s system 162% cpu 0.861 total $ time go run -tags=jemalloc . go run -tags=jemalloc . 5.29s user 0.36s system 108% cpu 5.200 total
This slowdown can be attributed to the fact that Cgo calls were made for each memory allocation, and each Cgo call incurs some overhead. To deal with these, the Allocator library was written , also included in the ristretto / z package . This library allocates larger memory segments in one call, each of which can accommodate many small objects, which eliminates the need for expensive Cgo calls .
The Allocator starts with a buffer and, as soon as it is used up, creates a new buffer twice the size of the first. It maintains an internal list of all allocated buffers. Finally, when the user is done with the data, we can call Release to release all of those buffers in one fell swoop. Note: Allocator does not move memory at all. This ensures that all the pointers we have to the struct continue to function.
Although such a memory management can appear clumsy and compared to how to operate
tcmalloc
and
jemalloc
, this approach is much simpler. Once you allocate memory, you cannot then free just one structure. You can only free all the memory used by the Allocator at once.
What Allocator is really good at is allocating millions of structures cheaply and then freeing them when the job is done without having to involve a bunch of Go to do the job . Running the above program with the new allocator build tag makes it even faster than the Go memory version.
$ time go run -tags="jemalloc,allocator" . go run -tags="jemalloc,allocator" . 1.09s user 0.29s system 143% cpu 0.956 total
In Go 1.14 and later, the flag
-race
enables alignment checks of structures in memory. Allocator has a method
AllocateAligned
that returns memory, and the pointer must be correctly aligned to pass these checks. If the structure is large, then some memory may be lost, but the CPU instructions start to work more efficiently due to the correct delimitation of words.
There was another problem with memory management. It so happens that memory is allocated in one place, and released in a completely different place. All communication between these two points can be carried out through structures, and they can be distinguished only by transferring a specific object
Allocator
. To deal with this, we assign a unique ID to each object.
Allocator
which these objects store in the reference
uint64
. Each new object
Allocator
is stored in the global dictionary with reference to a reference to itself. Allocator objects can then be recalled using this reference, and released when the data is no longer required.
Arrange links competently
DO NOT reference Go allocated memory from manually allocated memory.
When allocating a structure by hand as shown above, it is important to ensure that there are no references to Go-allocated memory within that structure. Let's modify the above structure a bit:
type node struct {
val int
next *node
buf []byte
}
Let's use the function
root := newNode(val)
defined above to manually select a node. If we then set
root.next = &node{val: val}
, thus allocating all the other nodes in the linked list through Go memory, we inevitably get the following sharding error:
$ go run -race -tags="jemalloc" . Allocated memory: 16 B Objects: 2000001 unexpected fault address 0x1cccb0 fatal error: fault [signal SIGSEGV: segmentation violation code=0x1 addr=0x1cccb0 pc=0x55a48b]
Memory allocated by Go is subject to garbage collection because no valid Go structure points to it. The references are only from memory allocated in C, and the Go heap does not contain any suitable references, which provokes the above error. Thus, if you create a structure and manually allocate memory for it, it is important to ensure that all recursively accessible fields are also manually allocated.
For example, if the above structure used a byte segment, then we allocated that segment using an Allocator, and also avoided mixing Go memory with C memory.
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = -1
n.buf = allocator.Allocate(16) // 16
rand.Read(n.buf)
How to deal with gigabytes of dedicated memory
Allocator
good for manually selecting millions of structures. But there are also cases when you need to create billions of small objects and sort them. To do this in Go, even with help
Allocator
, you need to write code like this:
var nodes []*node
for i := 0; i < 1e9; i++ {
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
nodes = append(nodes, n)
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].val < nodes[j].val
})
// .
All these 1B nodes are manually allocated in
Allocator
, which is expensive. You also have to spend money on each memory segment in Go, which is quite expensive in itself, since we need 8GB of memory (8 bytes per node pointer).
To deal with these practical situations, a
z.Buffer
memory-mapped file has been created, thus allowing Linux to swap and flush memory pages as the system requires. It implements
io.Writer
and allows us not to depend on
bytes.Buffer
.
More importantly, it
z.Buffer
provides a new way to highlight smaller data segments. When you call
SliceAllocate(n)
,
z.Buffer
will record the length of the segment to be selected
(n)
, and then select that segment. This makes
z.Buffer
it easier to understand segment boundaries and iterate over segments correctly with
SliceIterate
.
Sorting variable length data
For sorting, we initially tried to get segment offsets from
z.Buffer
, refer to segments for comparison, but sort only the offsets. Having received the offset, it
z.Buffer
can read it, find the segment length and return this segment. Thus, such a system allows you to return the segments in a sorted form without resorting to any memory shuffling. As innovative as it is, this mechanism puts significant pressure on memory, since we still have to pay an 8GB memory penalty just to push the offsets of interest to Go memory.
The most important factor limiting our work was that the sizes were not the same for all segments. Moreover, we could access these segments only in sequential order, and not in reverse or random, not being able to calculate and store offsets in advance. Most algorithms for sorting in place assume that all values are the same size, can be accessed in any order, and nothing prevents them from being swapped.
sort.Slice
in Go works in a similar way, and was therefore poorly suited for
z.Buffer
.
Given these limitations, it was concluded that the merge sort algorithm is best suited for the task at hand. With merge sort, you can work in a buffer, performing operations in sequential order, with the additional memory overhead being only half the size of the buffer. It turned out to be not only cheaper than moving the indentation into memory, but it also significantly improves predictability in terms of memory overhead (half the buffer size). Better yet, the overhead required to perform merge sort is itself mapped to memory.
There is one more very positive effect of using merge sort. Offset sorting has to keep the offsets in memory while we iterate over them and process the buffer, which only increases the pressure on memory. With merge sort, all the additional memory that we needed is freed by the time the enumeration starts, which means that we will have more memory to process the buffer.
z.Buffer also supports memory allocation through
Calloc
, as well as automatic memory mapping after exceeding a certain limit specified by the user. Therefore, the tool works well with data of any size.
buffer := z.NewBuffer(256<<20) // 256MB Calloc.
buffer.AutoMmapAfter(1<<30) // mmap 1GB.
for i := 0; i < 1e9; i++ {
b := buffer.SliceAllocate(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
}
buffer.SortSlice(func(left, right []byte) bool {
nl := (*node)(unsafe.Pointer(&left[0]))
nr := (*node)(unsafe.Pointer(&right[0]))
return nl.val < nr.val
})
// .
buffer.SliceIterate(func(b []byte) error {
n := (*node)(unsafe.Pointer(&b[0]))
_ = n.val
return nil
})
Catching memory leaks
This entire discussion would be incomplete without touching on the topic of memory leaks. After all, if we allocate memory manually, then memory leaks will be inevitable in all those cases when we forget to free memory. How can you catch them?
We have long used a simple solution - we used an atomic counter that keeps track of the number of bytes allocated during such calls. In this case, you can quickly find out how much memory we have allocated manually in the program using
z.NumAllocBytes()
. If by the end of the memory test we still had some extra memory left, it meant a leak.
When we managed to find a leak, we first tried to use the jemalloc memory profiler. But it soon became clear that this did not help - he did not see the entire call stack, as he was bumping into the Cgo border. All that the profiler sees is memory allocation and release acts from the same calls
z.Calloc
and
z.Free
.
Thanks to the Go runtime, we were quickly able to build a simple system for catching callers in
z.Calloc
and mapping them to calls
z.Free
. This system requires mutex locks, so we decided not to enable it by default. Instead, we used the build flag
leak
to enable debug messages for leaks in developer assemblies. Thus, leaks are automatically detected and displayed to the console exactly where they originated.
// .
pc, _, l, ok := runtime.Caller(1)
if ok {
dallocsMu.Lock()
dallocs[uptr] = &dalloc{
pc: pc,
no: l,
sz: n,
}
dallocsMu.Unlock()
}
// , , .
// ,
// , .
$ go test -v -tags="jemalloc leak" -run=TestCalloc
...
LEAK: 128 at func: github.com/dgraph-io/ristretto/z.TestCalloc 91
Output
With the help of the described techniques, a golden mean is achieved. We can manually allocate memory in critical code paths that are highly dependent on available memory. At the same time, we can take advantage of automatic garbage collection in less critical ways. Even if you are not very good at handling Cgo or jemalloc, you can use these techniques with relatively large chunks of memory in Go - the effect will be comparable.
All libraries mentioned above are available under the Apache 2.0 license in the Ristretto / z package . The memory test and demo code are in the contrib folder .